断点续传小解
断点续传的原理
HTTP 协议是互联网上应用最广泛网络传输协议之一,它基于 TCP/IP 通信协议来传递数据。断点续传的奥秘就隐藏在这 HTTP 协议中了。
我们知道HTTP请求会有一个Request header 和 Response header,在请求头里边有个和Range相关的参数
当下载文件的时候,response header会有如下:
1 | Content-Length: 65804256 // 请求的文件的大小,单位 byte |
可见并不是所有的下载都支持断点续传,只有在response header中有 Accpet-Ranges: bytes字段时,才可以断点续传。
如何使用
利用content-range字段,就可以实现断点续传了。只需要在response header中指定Content-Range值就可以了。
使用方式如下:
1 | Content-Range: <unit>=<range-start>-<range-end>/<size> // size 为文件总大小,如果不知道可以用 * |
举例说明
单位 bytes,从第 10 个 bytes 开始下载
1 | Content-Range: bytes=10- |
单位 bytes,从第 10 个 bytes 开始下载,下载到第100个 bytes
1 | Content-Range: bytes=10-100 |
重启续传文件时保证文件一致性
下载中,如何保证文件的完整性?
我们要写的下载器是支持断点续传的,那么在进行续传时,怎么确定文件从我们上次下载时没有进行更新呢?这里通过response header中的几个属性值进行判断。
1 | Last-Modified: Tue, 07 Jul 2020 13:19:46 GMT // 服务端文件最后修改时间,可以用于校验文件是否更改过 |
- ETag: 根据 HTTP 协议的规定,当文件更新时,是会生成新的 ETag 值的,它类似于文件的指纹信息
- Last-Modified: 只是上次修改时间,有时候可能并不能够证明文件内容被修改过
写入阶段,如何保证文件顺序?
不管单线程还是多线程,由于要断点续传,在写入时都要在指定位置进行字符追加。
在Java中使用RandomAccessFile类,它可以在使用时指定读写模式,使用 seek 方法可以随意移动要操作的文件指针位置。很适合断点续传的写入场景。使用它你可以快速定位到已知的位置,进行快速检索;也可以在同一个文件的不同位置进行并发读写。
举个例子
在 aaa.text 文件中的位置 0 开始写入字符 abcdef,在位置 100 的位置开始写入字符 ddeeff。
1 | // rw 为读写模式 |
网速贷宽固定,为什么多线程下载可以提速
最大网速是固定的,运营商给你 100Mbs的网速,不管你怎么使用,速度最大也就是100/8=12.5MB/s。那么为什么多线程下载可以提高下载速度呢?
理论上来说,单线程下载就可以达到最大的理想网速,但是事实是,网络经常不那么通畅,很难达到理想的最大速度,也就是说只有在网路不那么通畅的时候,多线程下载才能提速。
多线程下载提速原因
HTTP 协议在传输时候是基于 TCP 协议传输数据的,TCP 协具有拥塞控制机制。拥塞控制 是TCP 的一个避免网络拥塞的算法,它是基于和性增长/乘性降低这样的控制方法来控制拥塞的。
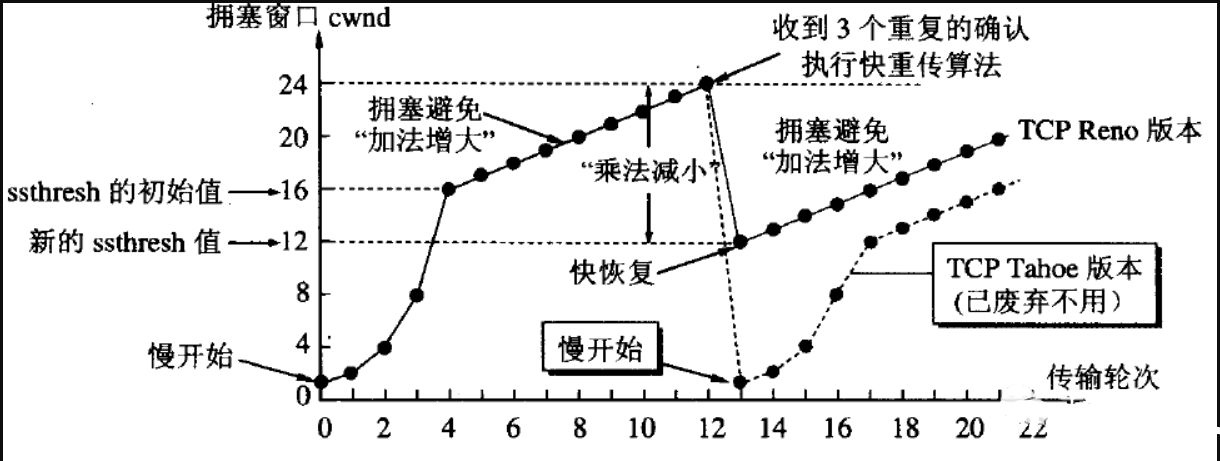
简单来说就是在 TCP 开始传输数据时,服务端会不断的探测可用带宽。在一个传输内容段被成功接收后,会加倍传输两倍段内容,如果再次被成功接收,就继续加倍,直到发生了丢包,这是这也被叫做慢启动。当达到慢启动阀值(ssthresh)时,慢启动算法就会转换为线性增长的阶段,每次只增加一个分段,放缓增加速度。我觉得其实慢启动的加倍增速过程并不慢,只是一种叫法。
但是当发生了丢包,也就是检测到拥塞时,发送方就会将发送段大小降低一个乘数,比如二分之一,慢启动阈值降为超时前拥塞窗口的一半大小、拥塞窗口会降为1个MSS,并且重新回到慢启动阶段。这时多线程的优势就体现出来了,因为你的多线程会让这个速度减速没有那么猛烈,毕竟这时可能有另一个线程正处在慢启动的在最终加速阶段,这样总体的下载速度就优于单线程了。