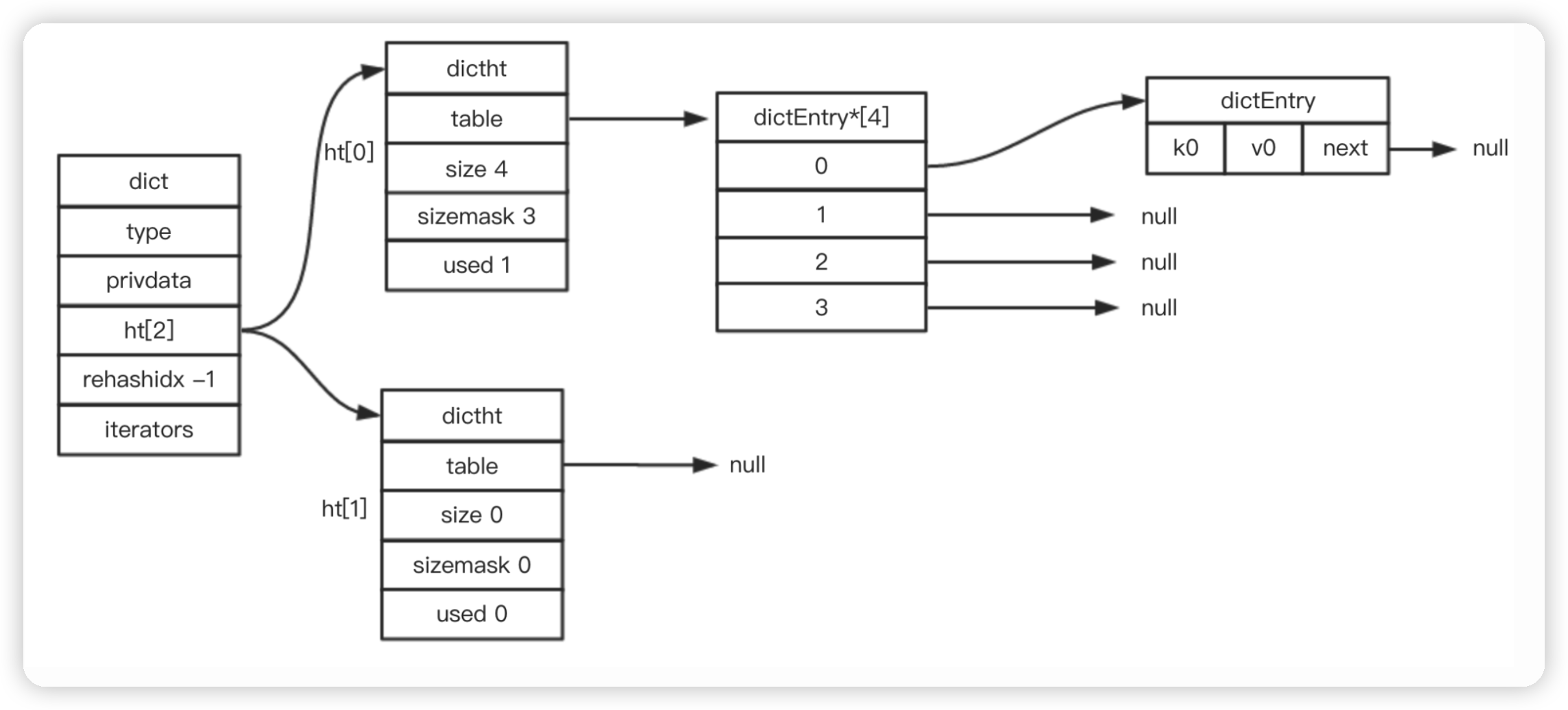
/* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ /* 哈希表 * 每个字典都使用两个哈希表,以实现渐进式 rehash 。 */ typedefstructdictht { // 哈希表数组 // 可以看作是:一个哈希表数组,数组的每个项是entry链表的头结点(链地址法解决哈希冲突) dictEntry **table; // 哈希表大小 unsignedlong size; // 哈希表大小掩码,用于计算索引值 // 总是等于 size - 1 unsignedlong sizemask; // 该哈希表已有节点的数量 unsignedlong used; } dictht; /* 字典 */ typedefstructdict { // 类型特定函数 dictType *type; // 私有数据 void *privdata; // 哈希表 dictht ht[2]; // rehash 索引 // 当 rehash 不在进行时,值为 -1 int rehashidx; /* rehashing not in progress if rehashidx == -1 */ // 目前正在运行的安全迭代器的数量 int iterators; /* number of iterators currently running */ } dict;
#define HASHTABLE_MIN_FILL 10 /* Minimal hash table fill 10% */ /* Expand or create the hash table, * when malloc_failed is non-NULL, it'll avoid panic if malloc fails (in which case it'll be set to 1). * Returns DICT_OK if expand was performed, and DICT_ERR if skipped. */ int _dictExpand(dict *d, unsignedlong size, int* malloc_failed) { if (malloc_failed) *malloc_failed = 0; /* the size is invalid if it is smaller than the number of * elements already inside the hash table */ if (dictIsRehashing(d) || d->ht[0].used > size) return DICT_ERR; dictht n; /* the new hash table */ unsignedlong realsize = _dictNextPower(size); /* Rehashing to the same table size is not useful. */ if (realsize == d->ht[0].size) return DICT_ERR; /* Allocate the new hash table and initialize all pointers to NULL */ n.size = realsize; n.sizemask = realsize-1; if (malloc_failed) { n.table = ztrycalloc(realsize*sizeof(dictEntry*)); *malloc_failed = n.table == NULL; if (*malloc_failed) return DICT_ERR; } else n.table = zcalloc(realsize*sizeof(dictEntry*)); n.used = 0; /* Is this the first initialization? If so it's not really a rehashing * we just set the first hash table so that it can accept keys. */ if (d->ht[0].table == NULL) { d->ht[0] = n; return DICT_OK; } /* Prepare a second hash table for incremental rehashing */ d->ht[1] = n; d->rehashidx = 0; return DICT_OK; } /* return DICT_ERR if expand was not performed */ intdictExpand(dict *d, unsignedlong size) { return _dictExpand(d, size, NULL); } /* Resize the table to the minimal size that contains all the elements, * but with the invariant of a USED/BUCKETS ratio near to <= 1 */ intdictResize(dict *d) { unsignedlong minimal; if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; minimal = d->ht[0].used; if (minimal < DICT_HT_INITIAL_SIZE) minimal = DICT_HT_INITIAL_SIZE; return dictExpand(d, minimal); } inthtNeedsResize(dict *dict) { longlong size, used; size = dictSlots(dict); used = dictSize(dict); return (size > DICT_HT_INITIAL_SIZE && (used*100/size < HASHTABLE_MIN_FILL)); } /* 当HashTable的使用率为10%的时候,开始缩容,进行rehash操作。 */ /* If the percentage of used slots in the HT reaches HASHTABLE_MIN_FILL * we resize the hash table to save memory */ voidtryResizeHashTables(int dbid) { if (htNeedsResize(server.db[dbid].dict)) dictResize(server.db[dbid].dict); if (htNeedsResize(server.db[dbid].expires)) dictResize(server.db[dbid].expires); }
/* Our hash table capability is a power of two */ staticunsignedlong _dictNextPower(unsignedlong size) { unsignedlong i = DICT_HT_INITIAL_SIZE; if (size >= LONG_MAX) return LONG_MAX + 1LU; while(1) { if (i >= size) return i; i *= 2; //体现了扩容的大小不是传入的size(也就是ht[0].used*2),而是距离这个size最近的2^n。 } }
#define dictIsRehashing(d) ((d)->rehashidx != -1) /* Because we may need to allocate huge memory chunk at once when dict * expands, we will check this allocation is allowed or not if the dict * type has expandAllowed member function. */ staticintdictTypeExpandAllowed(dict *d) { if (d->type->expandAllowed == NULL) return1; return d->type->expandAllowed( _dictNextPower(d->ht[0].used + 1) * sizeof(dictEntry*), (double)d->ht[0].used / d->ht[0].size); } /* Expand the hash table if needed */ staticint _dictExpandIfNeeded(dict *d) { /* Incremental rehashing already in progress. Return. */ if (dictIsRehashing(d)) return DICT_OK; /* If the hash table is empty expand it to the initial size. */ if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); /* If we reached the 1:1 ratio, and we are allowed to resize the hash * table (global setting) or we should avoid it but the ratio between * elements/buckets is over the "safe" threshold, we resize doubling * the number of buckets. */ if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) && dictTypeExpandAllowed(d)) { return dictExpand(d, d->ht[0].used + 1); } return DICT_OK; }
#define dictIsRehashing(d) ((d)->rehashidx != -1) /* Low level add or find: * This function adds the entry but instead of setting a value returns the * dictEntry structure to the user, that will make sure to fill the value * field as they wish. * * This function is also directly exposed to the user API to be called * mainly in order to store non-pointers inside the hash value, example: * * entry = dictAddRaw(dict,mykey,NULL); * if (entry != NULL) dictSetSignedIntegerVal(entry,1000); * * Return values: * * If key already exists NULL is returned, and "*existing" is populated * with the existing entry if existing is not NULL. * * If key was added, the hash entry is returned to be manipulated by the caller. */ dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) { long index; dictEntry *entry; dictht *ht; if (dictIsRehashing(d)) _dictRehashStep(d); //如果rehash操作未完成,进行一次rehash操作 /* Get the index of the new element, or -1 if * the element already exists. */ if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) returnNULL; /* Allocate the memory and store the new entry. * Insert the element in top, with the assumption that in a database * system it is more likely that recently added entries are accessed * more frequently. */ ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; entry = zmalloc(sizeof(*entry)); //为ht[1]开辟新的空间 entry->next = ht->table[index]; ht->table[index] = entry; ht->used++; /* Set the hash entry fields. */ dictSetKey(d, entry, key); return entry; }
/* This function performs just a step of rehashing, and only if hashing has * not been paused for our hash table. When we have iterators in the * middle of a rehashing we can't mess with the two hash tables otherwise * some element can be missed or duplicated. * * This function is called by common lookup or update operations in the * dictionary so that the hash table automatically migrates from H1 to H2 * while it is actively used. */ staticvoid _dictRehashStep(dict *d) { if (d->pauserehash == 0) dictRehash(d,1); } /* Performs N steps of incremental rehashing. Returns 1 if there are still * keys to move from the old to the new hash table, otherwise 0 is returned. * * Note that a rehashing step consists in moving a bucket (that may have more * than one key as we use chaining) from the old to the new hash table, however * since part of the hash table may be composed of empty spaces, it is not * guaranteed that this function will rehash even a single bucket, since it * will visit at max N*10 empty buckets in total, otherwise the amount of * work it does would be unbound and the function may block for a long time. */ intdictRehash(dict *d, int n) { int empty_visits = n*10; /* Max number of empty buckets to visit. */ if (!dictIsRehashing(d)) return0; while(n-- && d->ht[0].used != 0) { dictEntry *de, *nextde; /* Note that rehashidx can't overflow as we are sure there are more * elements because ht[0].used != 0 */ assert(d->ht[0].size > (unsignedlong)d->rehashidx); while(d->ht[0].table[d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return1; } de = d->ht[0].table[d->rehashidx]; /* Move all the keys in this bucket from the old to the new hash HT */ while(de) { uint64_t h; nextde = de->next; /* Get the index in the new hash table */ h = dictHashKey(d, de->key) & d->ht[1].sizemask; de->next = d->ht[1].table[h]; d->ht[1].table[h] = de; d->ht[0].used--; d->ht[1].used++; de = nextde; } d->ht[0].table[d->rehashidx] = NULL; d->rehashidx++; } /* Check if we already rehashed the whole table... */ if (d->ht[0].used == 0) { zfree(d->ht[0].table); //当ht[0]的元素全部rehash到ht[1]的时候释放ht[0]的空间 d->ht[0] = d->ht[1]; //将原来的ht[1]设置为ht[0] _dictReset(&d->ht[1]); //ht[1] 设置为NULL d->rehashidx = -1; return0; } /* More to rehash... */ return1; }