ConcurrentHashMap的transfer阅读
流程图
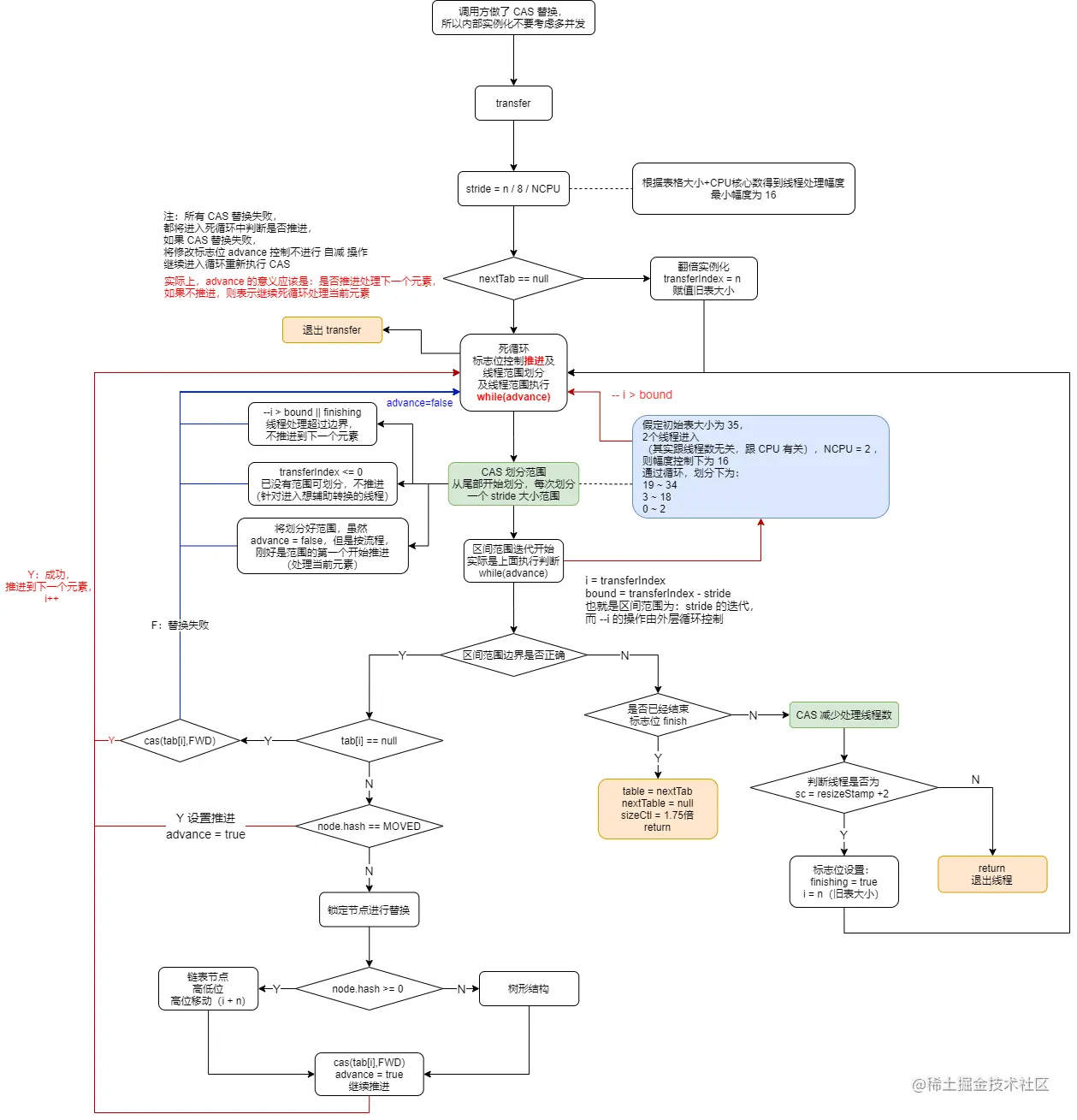
ConcurrenthashMap 的 transfer 主要是用于扩容重组阶段,当内部数组的容量值超过阈值时,将触发扩容重组, transfer 是该过程的主要实现。
相关概念
ConcurrentHashMap中,使用一个字段复用了多种功能,如:阈值控制、内部Node[]数组状态控制、扩容线程控制 等,该字段就是sizeCtl。
1 | /** |
ConcurrentHashMap在重组时,做法与HashMap类似,但是具体新的数组,则是使用了内部一个数组变量nextTable以保证并发控制。其他如:链表的重组、树结构的重组 流程均是大同小异。ConcurrentHashMap的重组采用了跟分段表类似的思想,实际上是将数组划分为不同的分段区间,如果有线程进入,可获取该区间辅助转换。transferIndex是ConcurrentHashMap的内部属性,主要是在重组阶段中使用,用来表示还未被转换的数组,区间为:table[0] ~ table[transferIndex-1]ConcurrentHashMap并发转换的过程,借助了 信号量 的概念,只有获取到信号的线程,才能进入辅助转换,而 信号量 则存储在sizeCtl,每当一个线程进入获取,则sizeCtl + 1(首个线程开启转换则是sizeCtl + 2)。主要注意的是,该信号量的初始值为 负数,加入线程将增大sizeCtl,直到sizeCtl的增大达到 0 时,信号量将用完,默认的与 信号量 相加等于 0 的值是:65534,也就是说,最多允许 65534 条线程参与辅助转换(非固定,可调节)。所以可通过rs + 1 ~ rs + 65534的边界控制,来决定线程是否加入辅助转换。让sizeCtl成为负数变成信号量的主要代码是:resizeStamp(n) << RESIZE_STAMP_SHIFTConcurrentHash的转换过程中,用到的辅助属性有两个:nextTable,transferIndex,它们属于线程共享的,所以在对他们进行变更时,都是使用了“自旋/死循环 + CAS”的方式,实现线程并发安全。
解析
转换过程 transfer 的每个调用入口,实际上外部都有对 sizeCtl 进行 自旋 + CAS 的操作。也就是并发情况下,即使多条线程想要进行扩容,那也只有一条线程能够成功,另外的线程则进入辅助扩容的过程
addCount
扩容方法进入前的判断如下:
1 | private final void addCount(long x, int check) { |
这里出现大量的判断比较,容易造成混乱,但主要记住:这些判断比较,在 ConcurrentHashMap 大部分是边界判断。记住这点后能够帮助理解大部分的判断比较,比如:sc == rs + MAX_RESIZERS 和 sc == rs + 1 实际上是对线程数的上下界的限制,超过限制,则不进入辅助转换。
transfer
ConcurrentHashMap 是分段进行并发转换,就是一个数组,按 幅度 划分,然后相应的线程获取到哪个分组,则负责该分组的转换的完成。那么重组转换的出口在哪里呢?只有当所有线程都执行完毕,处理转换的线程的信号量没有被获取了 ,才退出整个转换过程。默认最小幅度是 16,也就是说线程的最少处理元素个数是 16 个。
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
进入转换方法后,首先就是确定线程处理幅度,然后初始化 nextTable (如果需要的话),并初始化转换过程中需要用到的一些辅助属性,如:transferIndex = n = table.length。
接下来,就是一个死循环(假象)。死循环内嵌死循环。第一个死循环使用到了局部参数 i 和 bound,实际上,在每个线程进入该方法后,都会获得自己这两个局部变量值,而它们的值变动则是在内部循环中开始赋值,一旦赋值成功,那么第一个死循环就变成了一个有界的 for 循环
优先看第二个内部循环, advance 变量控制了该循环。advance 变量主要表示:是否推进到下一个元素。它实际与 i 和 bound 是有逻辑关系的,一旦 i 和 bound 的关系不匹配,那么 advance 也就必须为 false,不再让线程进行推进,推进的操作是( --i )。也就是说,线程进入后,将有三个变量控制其运行,其中 bound, i 是线程处理的数组边界,而 advance 则控制线程在这个边界中进行移动
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
可以看到,内部死循环的主要作用,其实是为了划分分区(划分幅度为 stride),也可以意识到,即使是单线程,其执行也是按分区执行,并且执行的分区顺序是从尾部到首部。通过 CAS 保证分区的划分的线程安全,失败则重新循环再次操作。
划分完分区后,剩下的就是线程的处理过程。处理过程包括 2 部分,一部分是普通的元素处理,一部分是边界控制——退出出口。
在每一个元素的处理过程中,线程都会先判断是否到达出口,是则退出?差不离,但退出包含两种情况,一种是普通的辅助线程的退出,它只擦自己的屁股,另外一种是整体线程的退出,它除了处理负责自己的退出出口,还要负责将重组后的结果 nextTable 重复赋值给 table,并为 sizeCtl 赋值为新数组大小的 0.75 倍的阈值
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
说完了边界出口,剩下的就是普通的操作了,有以下判断:
- 当线程转换时旧数组对应位置上为
null,则直接CAS替换为ForwardingNode(其hash = MOVED),表示转移过了;此时,当外部有操作put刚好命中此位置时,将会进入辅助转换的过程,判断依据就是if (hash == MOVED)。也就是说,在重组转换过程中,进行put操作,将进入辅助转换过程。 - 如果
hash 为 MOVED,则表示该位置已被其他线程转移过,推进到下一个元素
最后,进入与 HashMap 相同的链表重组和树结构重组的逻辑中,成功执行后,advance = true,继续推进处理元素(--i)。这里比 HashMap 多出一步,就是将旧数组对应位置上的标记为已处理。
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
至此,整个 ConcurrentHashMap 的转换过程算完了